 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Conditioned Multi-Objective Reinforcement Learning: Decomposed, Diversity-Driven Policy Optimization
Feb 08, 2026Multi-objective reinforcement learning (MORL) seeks to learn policies that balance multiple, often conflicting objectives. Although a single preference-conditioned policy is the most flexible and scalable solution, existing approaches remain brittle in practice, frequently failing to recover complete Pareto fronts. We show that this failure stems from two structural issues in current methods: destructive gradient interference caused by premature scalarization and representational collapse across the preference space. We introduce $D^3PO$, a PPO-based framework that reorganizes multi-objective policy optimization to address these issues directly. $D^3PO$ preserves per-objective learning signals through a decomposed optimization pipeline and integrates preferences only after stabilization, enabling reliable credit assignment. In addition, a scaled diversity regularizer enforces sensitivity of policy behavior to preference changes, preventing collapse. Across standard MORL benchmarks, including high-dimensional and many-objective control tasks, $D^3PO$ consistently discovers broader and higher-quality Pareto fronts than prior single- and multi-policy methods, matching or exceeding state-of-the-art hypervolume and expected utility while using a single deployable policy.
Fake News Detection After LLM Laundering: Measurement and Explanation
Jan 29, 2025



With their advanced capabilities, Large Language Models (LLMs) can generate highly convincing and contextually relevant fake news, which can contribute to disseminating misinformation. Though there is much research on fake news detection for human-written text, the field of detecting LLM-generated fake news is still under-explored. This research measures the efficacy of detectors in identifying LLM-paraphrased fake news, in particular, determining whether adding a paraphrase step in the detection pipeline helps or impedes detection. This study contributes: (1) Detectors struggle to detect LLM-paraphrased fake news more than human-written text, (2) We find which models excel at which tasks (evading detection, paraphrasing to evade detection, and paraphrasing for semantic similarity). (3) Via LIME explanations, we discovered a possible reason for detection failures: sentiment shift. (4) We discover a worrisome trend for paraphrase quality measurement: samples that exhibit sentiment shift despite a high BERTSCORE. (5) We provide a pair of datasets augmenting existing datasets with paraphrase outputs and scores. The dataset is available on GitHub
Demystifying Legalese: An Automated Approach for Summarizing and Analyzing Overlaps in Privacy Policies and Terms of Service
Apr 17, 2024The complexities of legalese in terms and policy documents can bind individuals to contracts they do not fully comprehend, potentially leading to uninformed data sharing. Our work seeks to alleviate this issue by developing language models that provide automated, accessible summaries and scores for such documents, aiming to enhance user understanding and facilitate informed decisions. We compared transformer-based and conventional models during training on our dataset, and RoBERTa performed better overall with a remarkable 0.74 F1-score. Leveraging our best-performing model, RoBERTa, we highlighted redundancies and potential guideline violations by identifying overlaps in GDPR-required documents, underscoring the necessity for stricter GDPR compliance.
Experiments with Encoding Structured Data for Neural Networks
Feb 15, 2024



The project's aim is to create an AI agent capable of selecting good actions in a game-playing domain called Battlespace. Sequential domains like Battlespace are important testbeds for planning problems, as such, the Department of Defense uses such domains for wargaming exercises. The agents we developed combine Monte Carlo Tree Search (MCTS) and Deep Q-Network (DQN) techniques in an effort to navigate the game environment, avoid obstacles, interact with adversaries, and capture the flag. This paper will focus on the encoding techniques we explored to present complex structured data stored in a Python class, a necessary precursor to an agent.
Identifying Reasoning Flaws in Planning-Based RL Using Tree Explanations
Sep 28, 2021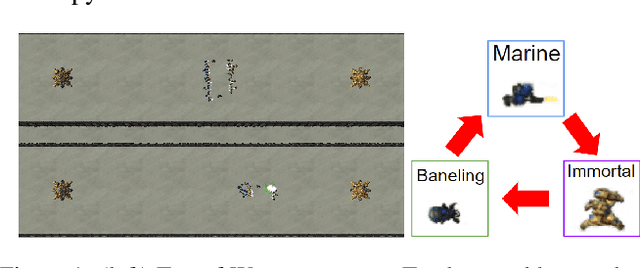

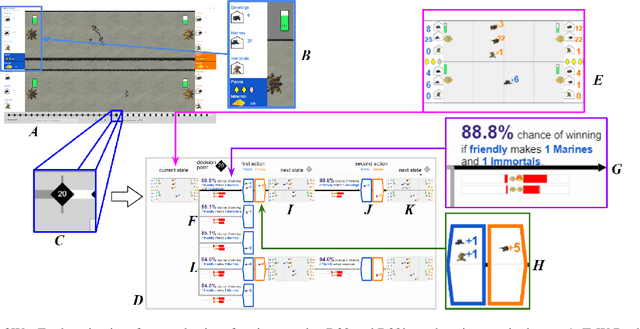
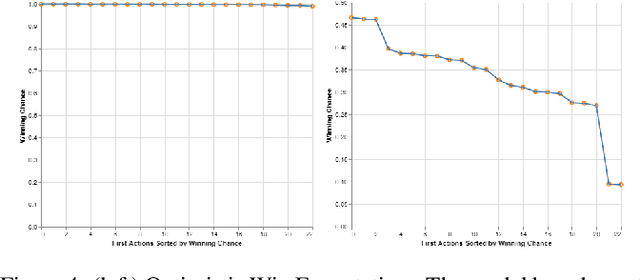
Enabling humans to identify potential flaws in an agent's decision making is an important Explainable AI application. We consider identifying such flaws in a planning-based deep reinforcement learning (RL) agent for a complex real-time strategy game. In particular, the agent makes decisions via tree search using a learned model and evaluation function over interpretable states and actions. This gives the potential for humans to identify flaws at the level of reasoning steps in the tree, even if the entire reasoning process is too complex to understand. However, it is unclear whether humans will be able to identify such flaws due to the size and complexity of trees. We describe a user interface and case study, where a small group of AI experts and developers attempt to identify reasoning flaws due to inaccurate agent learning. Overall, the interface allowed the group to identify a number of significant flaws of varying types, demonstrating the promise of this approach.
Explaining Reinforcement Learning to Mere Mortals: An Empirical Study
Mar 22, 2019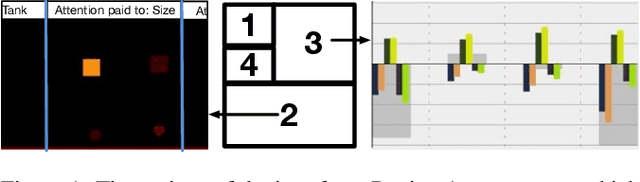
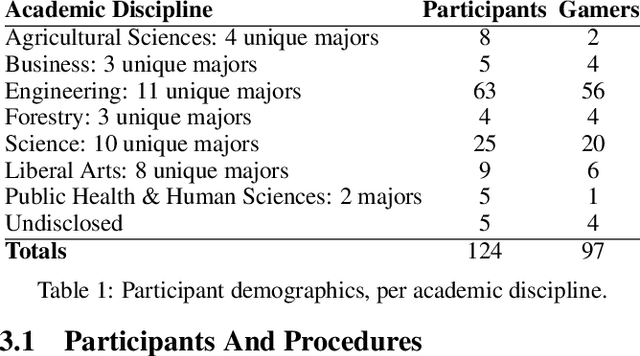
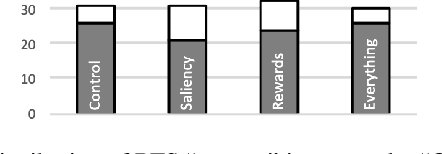
We present a user study to investigate the impact of explanations on non-experts' understanding of reinforcement learning (RL) agents. We investigate both a common RL visualization, saliency maps (the focus of attention), and a more recent explanation type, reward-decomposition bars (predictions of future types of rewards). We designed a 124 participant, four-treatment experiment to compare participants' mental models of an RL agent in a simple Real-Time Strategy (RTS) game. Our results show that the combination of both saliency and reward bars were needed to achieve a statistically significant improvement in mental model score over the control. In addition, our qualitative analysis of the data reveals a number of effects for further study.
Visualizing and Understanding Atari Agents
Sep 10, 2018
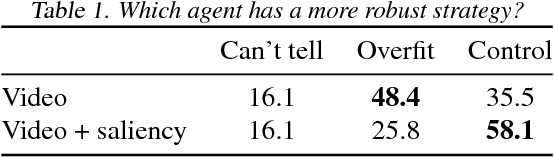
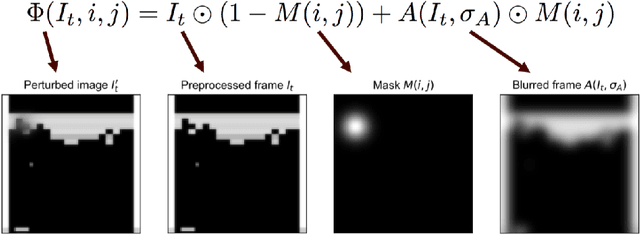

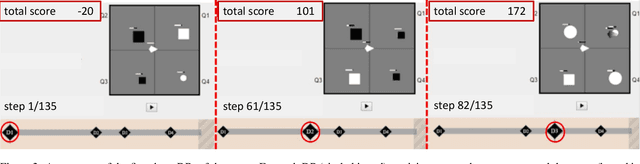
While deep reinforcement learning (deep RL) agents are effective at maximizing rewards, it is often unclear what strategies they use to do so. In this paper, we take a step toward explaining deep RL agents through a case study using Atari 2600 environments. In particular, we focus on using saliency maps to understand how an agent learns and executes a policy. We introduce a method for generating useful saliency maps and use it to show 1) what strong agents attend to, 2) whether agents are making decisions for the right or wrong reasons, and 3) how agents evolve during learning. We also test our method on non-expert human subjects and find that it improves their ability to reason about these agents. Overall, our results show that saliency information can provide significant insight into an RL agent's decisions and learning behavior.