 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePcLast: Discovering Plannable Continuous Latent States
Nov 06, 2023



Goal-conditioned planning benefits from learned low-dimensional representations of rich, high-dimensional observations. While compact latent representations, typically learned from variational autoencoders or inverse dynamics, enable goal-conditioned planning they ignore state affordances, thus hampering their sample-efficient planning capabilities. In this paper, we learn a representation that associates reachable states together for effective onward planning. We first learn a latent representation with multi-step inverse dynamics (to remove distracting information); and then transform this representation to associate reachable states together in $\ell_2$ space. Our proposals are rigorously tested in various simulation testbeds. Numerical results in reward-based and reward-free settings show significant improvements in sampling efficiency, and yields layered state abstractions that enable computationally efficient hierarchical planning.
Offline Policy Comparison with Confidence: Benchmarks and Baselines
May 22, 2022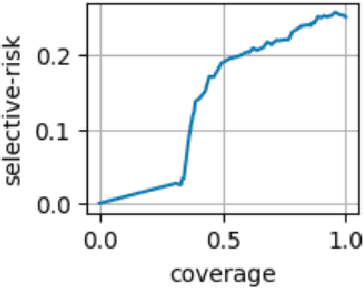
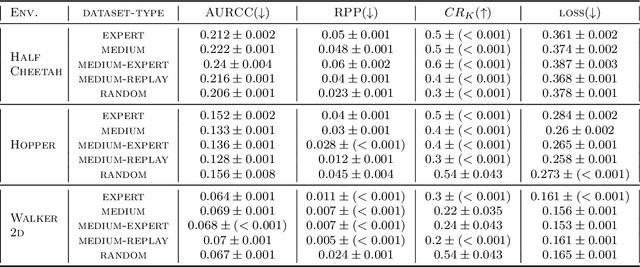


Decision makers often wish to use offline historical data to compare sequential-action policies at various world states. Importantly, computational tools should produce confidence values for such offline policy comparison (OPC) to account for statistical variance and limited data coverage. Nevertheless, there is little work that directly evaluates the quality of confidence values for OPC. In this work, we address this issue by creating benchmarks for OPC with Confidence (OPCC), derived by adding sets of policy comparison queries to datasets from offline reinforcement learning. In addition, we present an empirical evaluation of the risk versus coverage trade-off for a class of model-based baselines. In particular, the baselines learn ensembles of dynamics models, which are used in various ways to produce simulations for answering queries with confidence values. While our results suggest advantages for certain baseline variations, there appears to be significant room for improvement in future work.
Dream and Search to Control: Latent Space Planning for Continuous Control
Oct 19, 2020
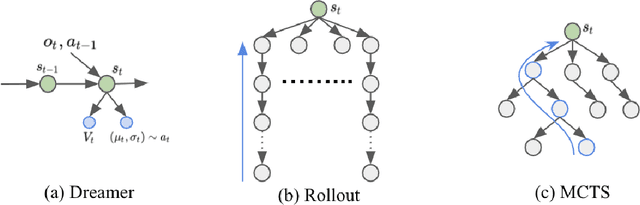
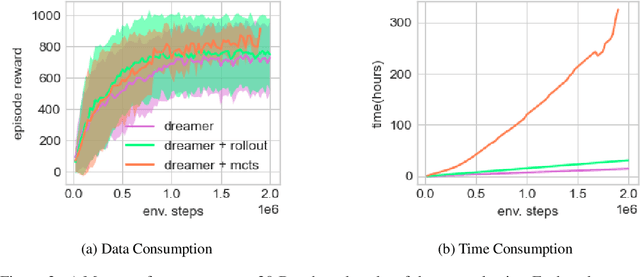
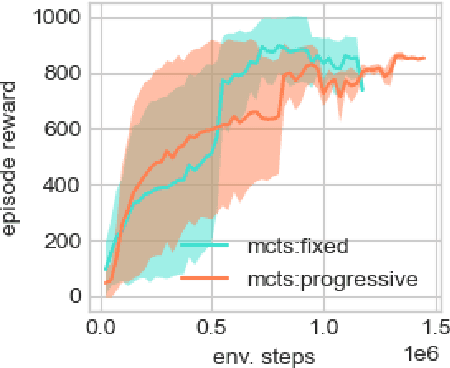
Learning and planning with latent space dynamics has been shown to be useful for sample efficiency in model-based reinforcement learning (MBRL) for discrete and continuous control tasks. In particular, recent work, for discrete action spaces, demonstrated the effectiveness of latent-space planning via Monte-Carlo Tree Search (MCTS) for bootstrapping MBRL during learning and at test time. However, the potential gains from latent-space tree search have not yet been demonstrated for environments with continuous action spaces. In this work, we propose and explore an MBRL approach for continuous action spaces based on tree-based planning over learned latent dynamics. We show that it is possible to demonstrate the types of bootstrapping benefits as previously shown for discrete spaces. In particular, the approach achieves improved sample efficiency and performance on a majority of challenging continuous-control benchmarks compared to the state-of-the-art.
Understanding Finite-State Representations of Recurrent Policy Networks
Jun 06, 2020
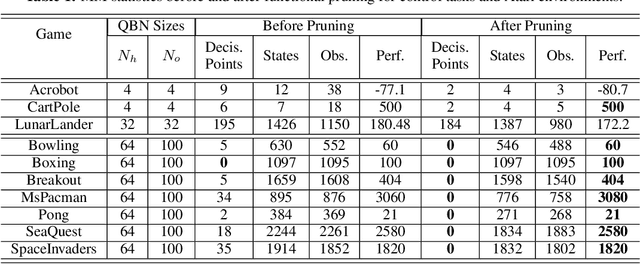
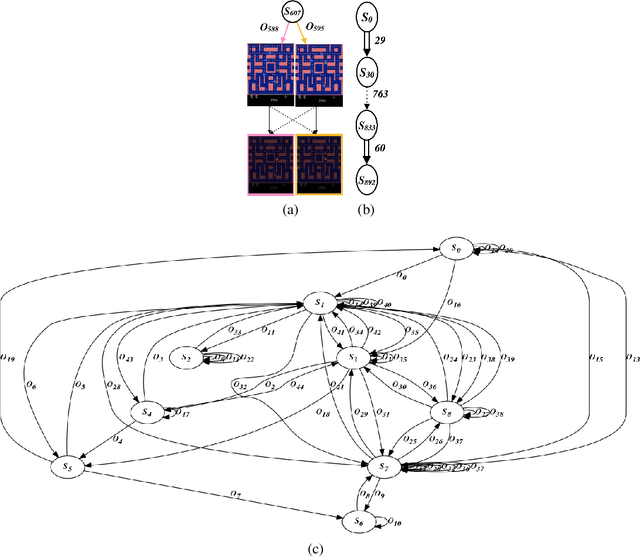
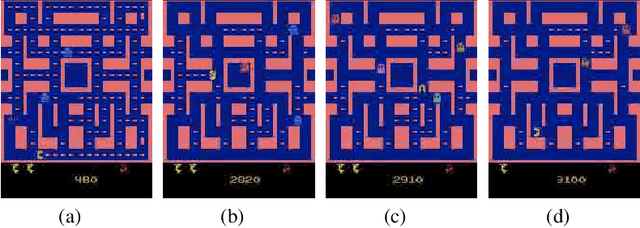
We introduce an approach for understanding finite-state machine (FSM) representations of recurrent policy networks. Recent work focused on minimizing FSMs to gain high-level insight, however, minimization can obscure a deeper understanding by merging states that are semantically distinct. Conversely, our approach starts with an unminimized machine and applies more-interpretable reductions that preserve the key decision points of the policy. We also contribute a saliency tool to attain a deeper understanding of the role of observations in the decisions. Our case studies on policies from 7 Atari games and 3 control benchmarks demonstrate that the approach can reveal insights that have not been noticed in prior work.
Learning Finite State Representations of Recurrent Policy Networks
Nov 29, 2018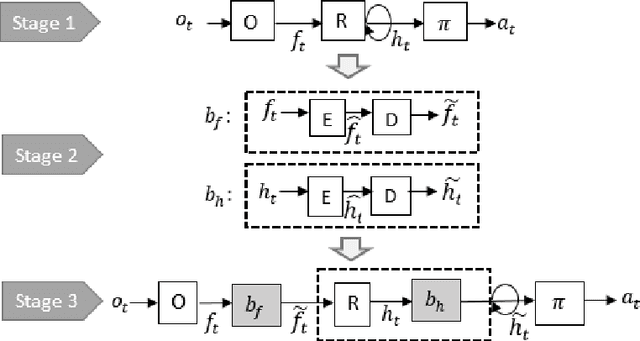
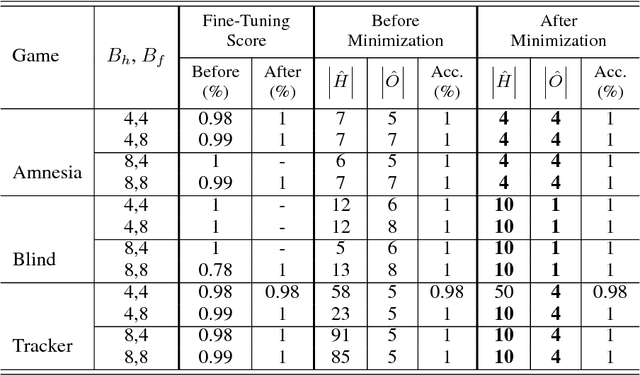
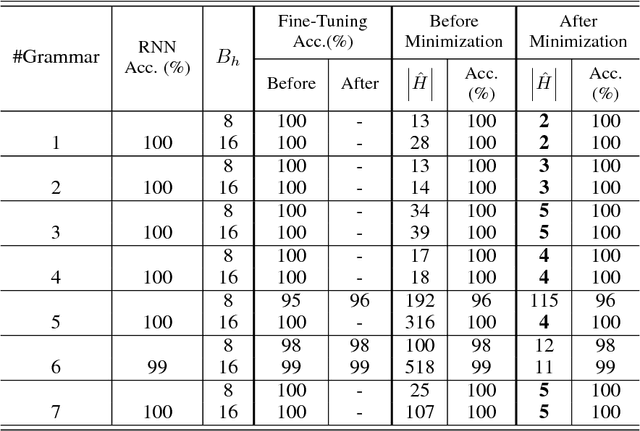
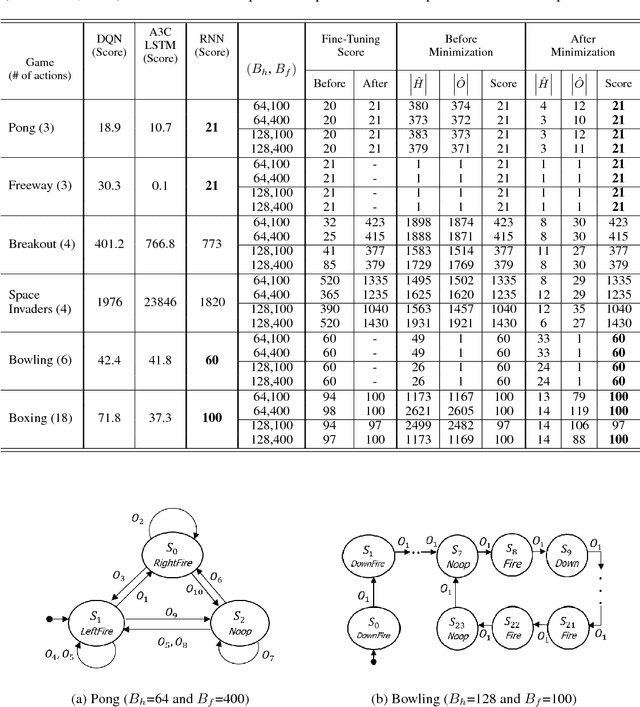
Recurrent neural networks (RNNs) are an effective representation of control policies for a wide range of reinforcement and imitation learning problems. RNN policies, however, are particularly difficult to explain, understand, and analyze due to their use of continuous-valued memory vectors and observation features. In this paper, we introduce a new technique, Quantized Bottleneck Insertion, to learn finite representations of these vectors and features. The result is a quantized representation of the RNN that can be analyzed to improve our understanding of memory use and general behavior. We present results of this approach on synthetic environments and six Atari games. The resulting finite representations are surprisingly small in some cases, using as few as 3 discrete memory states and 10 observations for a perfect Pong policy. We also show that these finite policy representations lead to improved interpretability.
Visualizing and Understanding Atari Agents
Sep 10, 2018
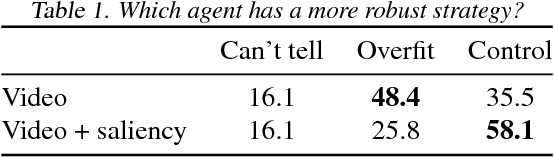
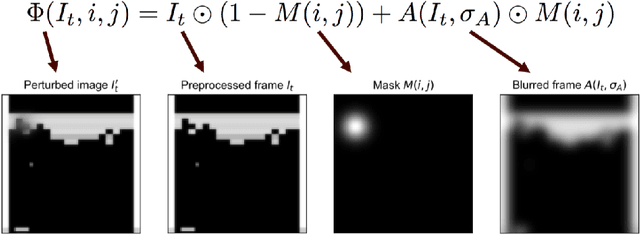

While deep reinforcement learning (deep RL) agents are effective at maximizing rewards, it is often unclear what strategies they use to do so. In this paper, we take a step toward explaining deep RL agents through a case study using Atari 2600 environments. In particular, we focus on using saliency maps to understand how an agent learns and executes a policy. We introduce a method for generating useful saliency maps and use it to show 1) what strong agents attend to, 2) whether agents are making decisions for the right or wrong reasons, and 3) how agents evolve during learning. We also test our method on non-expert human subjects and find that it improves their ability to reason about these agents. Overall, our results show that saliency information can provide significant insight into an RL agent's decisions and learning behavior.