 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFloorSet -- a VLSI Floorplanning Dataset with Design Constraints of Real-World SoCs
May 09, 2024



Floorplanning for systems-on-a-chip (SoCs) and its sub-systems is a crucial and non-trivial step of the physical design flow. It represents a difficult combinatorial optimization problem. A typical large scale SoC with 120 partitions generates a search-space of nearly 10E250. As novel machine learning (ML) approaches emerge to tackle such problems, there is a growing need for a modern benchmark that comprises a large training dataset and performance metrics that better reflect real-world constraints and objectives compared to existing benchmarks. To address this need, we present FloorSet -- two comprehensive datasets of synthetic fixed-outline floorplan layouts that reflect the distribution of real SoCs. Each dataset has 1M training samples and 100 test samples where each sample is a synthetic floor-plan. FloorSet-Prime comprises fully-abutted rectilinear partitions and near-optimal wire-length. A simplified dataset that reflects early design phases, FloorSet-Lite comprises rectangular partitions, with under 5 percent white-space and near-optimal wire-length. Both datasets define hard constraints seen in modern design flows such as shape constraints, edge-affinity, grouping constraints, and pre-placement constraints. FloorSet is intended to spur fundamental research on large-scale constrained optimization problems. Crucially, FloorSet alleviates the core issue of reproducibility in modern ML driven solutions to such problems. FloorSet is available as an open-source repository for the research community.
MOTO: Offline Pre-training to Online Fine-tuning for Model-based Robot Learning
Jan 06, 2024We study the problem of offline pre-training and online fine-tuning for reinforcement learning from high-dimensional observations in the context of realistic robot tasks. Recent offline model-free approaches successfully use online fine-tuning to either improve the performance of the agent over the data collection policy or adapt to novel tasks. At the same time, model-based RL algorithms have achieved significant progress in sample efficiency and the complexity of the tasks they can solve, yet remain under-utilized in the fine-tuning setting. In this work, we argue that existing model-based offline RL methods are not suitable for offline-to-online fine-tuning in high-dimensional domains due to issues with distribution shifts, off-dynamics data, and non-stationary rewards. We propose an on-policy model-based method that can efficiently reuse prior data through model-based value expansion and policy regularization, while preventing model exploitation by controlling epistemic uncertainty. We find that our approach successfully solves tasks from the MetaWorld benchmark, as well as the Franka Kitchen robot manipulation environment completely from images. To the best of our knowledge, MOTO is the first method to solve this environment from pixels.
* This is an updated version of a manuscript that originally appeared at CoRL 2023. The project website is here https://sites.google.com/view/mo2o
Searching for High-Value Molecules Using Reinforcement Learning and Transformers
Oct 04, 2023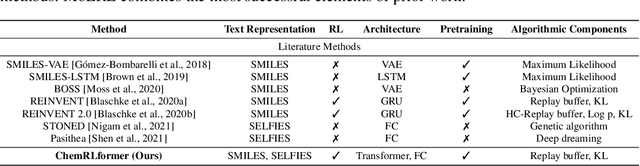
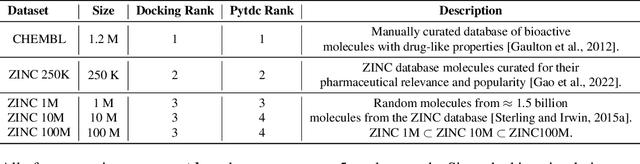
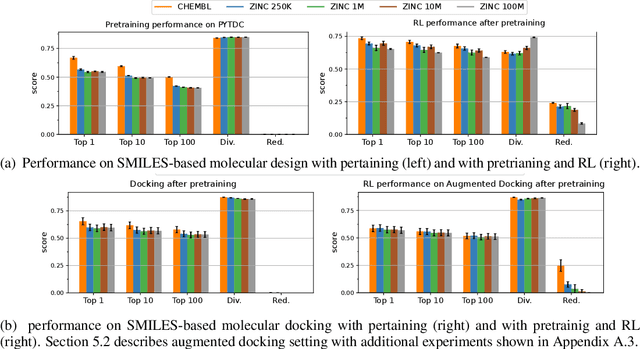
Reinforcement learning (RL) over text representations can be effective for finding high-value policies that can search over graphs. However, RL requires careful structuring of the search space and algorithm design to be effective in this challenge. Through extensive experiments, we explore how different design choices for text grammar and algorithmic choices for training can affect an RL policy's ability to generate molecules with desired properties. We arrive at a new RL-based molecular design algorithm (ChemRLformer) and perform a thorough analysis using 25 molecule design tasks, including computationally complex protein docking simulations. From this analysis, we discover unique insights in this problem space and show that ChemRLformer achieves state-of-the-art performance while being more straightforward than prior work by demystifying which design choices are actually helpful for text-based molecule design.
Learning Sparse Control Tasks from Pixels by Latent Nearest-Neighbor-Guided Explorations
Feb 28, 2023



Recent progress in deep reinforcement learning (RL) and computer vision enables artificial agents to solve complex tasks, including locomotion, manipulation and video games from high-dimensional pixel observations. However, domain specific reward functions are often engineered to provide sufficient learning signals, requiring expert knowledge. While it is possible to train vision-based RL agents using only sparse rewards, additional challenges in exploration arise. We present a novel and efficient method to solve sparse-reward robot manipulation tasks from only image observations by utilizing a few demonstrations. First, we learn an embedded neural dynamics model from demonstration transitions and further fine-tune it with the replay buffer. Next, we reward the agents for staying close to the demonstrated trajectories using a distance metric defined in the embedding space. Finally, we use an off-policy, model-free vision RL algorithm to update the control policies. Our method achieves state-of-the-art sample efficiency in simulation and enables efficient training of a real Franka Emika Panda manipulator.
Modularity through Attention: Efficient Training and Transfer of Language-Conditioned Policies for Robot Manipulation
Dec 08, 2022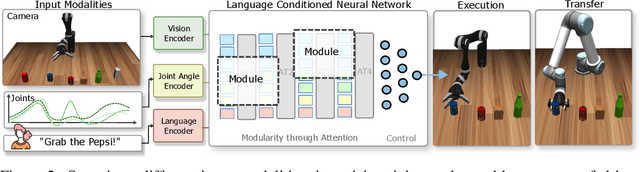

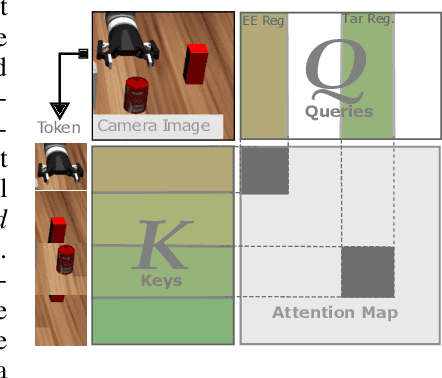

Language-conditioned policies allow robots to interpret and execute human instructions. Learning such policies requires a substantial investment with regards to time and compute resources. Still, the resulting controllers are highly device-specific and cannot easily be transferred to a robot with different morphology, capability, appearance or dynamics. In this paper, we propose a sample-efficient approach for training language-conditioned manipulation policies that allows for rapid transfer across different types of robots. By introducing a novel method, namely Hierarchical Modularity, and adopting supervised attention across multiple sub-modules, we bridge the divide between modular and end-to-end learning and enable the reuse of functional building blocks. In both simulated and real world robot manipulation experiments, we demonstrate that our method outperforms the current state-of-the-art methods and can transfer policies across 4 different robots in a sample-efficient manner. Finally, we show that the functionality of learned sub-modules is maintained beyond the training process and can be used to introspect the robot decision-making process. Code is available at https://github.com/ir-lab/ModAttn.
Group SELFIES: A Robust Fragment-Based Molecular String Representation
Nov 23, 2022


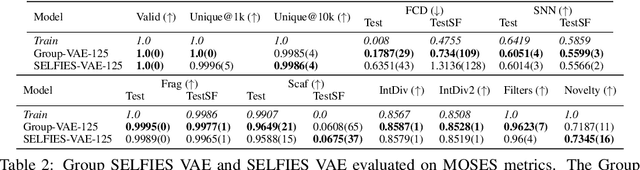
We introduce Group SELFIES, a molecular string representation that leverages group tokens to represent functional groups or entire substructures while maintaining chemical robustness guarantees. Molecular string representations, such as SMILES and SELFIES, serve as the basis for molecular generation and optimization in chemical language models, deep generative models, and evolutionary methods. While SMILES and SELFIES leverage atomic representations, Group SELFIES builds on top of the chemical robustness guarantees of SELFIES by enabling group tokens, thereby creating additional flexibility to the representation. Moreover, the group tokens in Group SELFIES can take advantage of inductive biases of molecular fragments that capture meaningful chemical motifs. The advantages of capturing chemical motifs and flexibility are demonstrated in our experiments, which show that Group SELFIES improves distribution learning of common molecular datasets. Further experiments also show that random sampling of Group SELFIES strings improves the quality of generated molecules compared to regular SELFIES strings. Our open-source implementation of Group SELFIES is available online, which we hope will aid future research in molecular generation and optimization.
AnyMorph: Learning Transferable Polices By Inferring Agent Morphology
Jun 17, 2022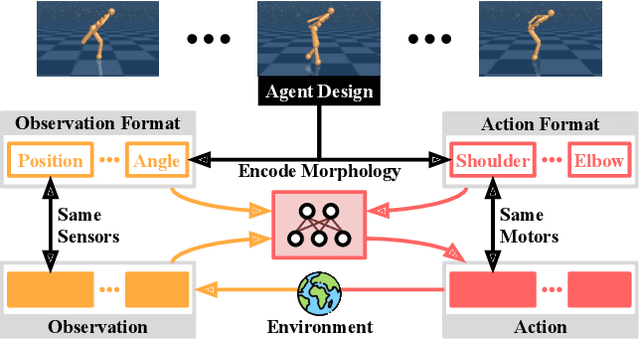
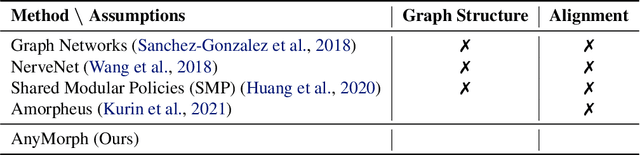
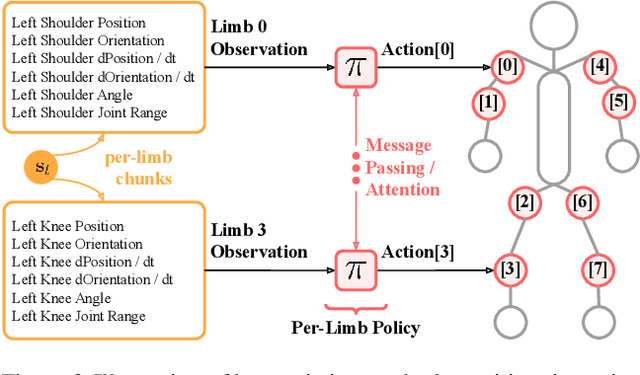

The prototypical approach to reinforcement learning involves training policies tailored to a particular agent from scratch for every new morphology. Recent work aims to eliminate the re-training of policies by investigating whether a morphology-agnostic policy, trained on a diverse set of agents with similar task objectives, can be transferred to new agents with unseen morphologies without re-training. This is a challenging problem that required previous approaches to use hand-designed descriptions of the new agent's morphology. Instead of hand-designing this description, we propose a data-driven method that learns a representation of morphology directly from the reinforcement learning objective. Ours is the first reinforcement learning algorithm that can train a policy to generalize to new agent morphologies without requiring a description of the agent's morphology in advance. We evaluate our approach on the standard benchmark for agent-agnostic control, and improve over the current state of the art in zero-shot generalization to new agents. Importantly, our method attains good performance without an explicit description of morphology.
Offline Policy Comparison with Confidence: Benchmarks and Baselines
May 22, 2022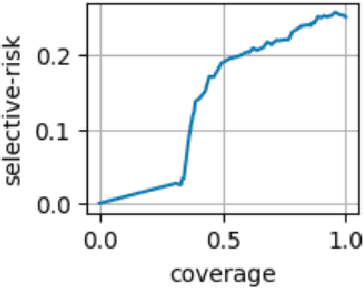
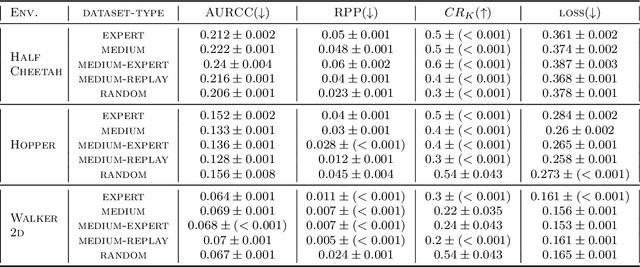


Decision makers often wish to use offline historical data to compare sequential-action policies at various world states. Importantly, computational tools should produce confidence values for such offline policy comparison (OPC) to account for statistical variance and limited data coverage. Nevertheless, there is little work that directly evaluates the quality of confidence values for OPC. In this work, we address this issue by creating benchmarks for OPC with Confidence (OPCC), derived by adding sets of policy comparison queries to datasets from offline reinforcement learning. In addition, we present an empirical evaluation of the risk versus coverage trade-off for a class of model-based baselines. In particular, the baselines learn ensembles of dynamics models, which are used in various ways to produce simulations for answering queries with confidence values. While our results suggest advantages for certain baseline variations, there appears to be significant room for improvement in future work.
Pretraining Graph Neural Networks for few-shot Analog Circuit Modeling and Design
Apr 01, 2022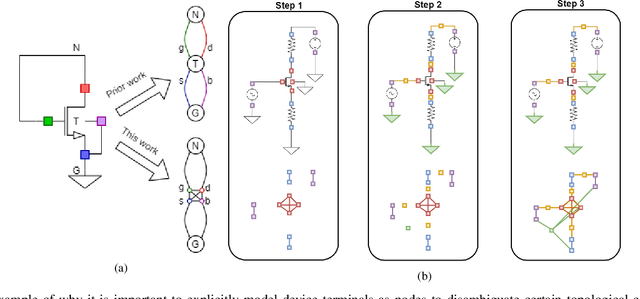
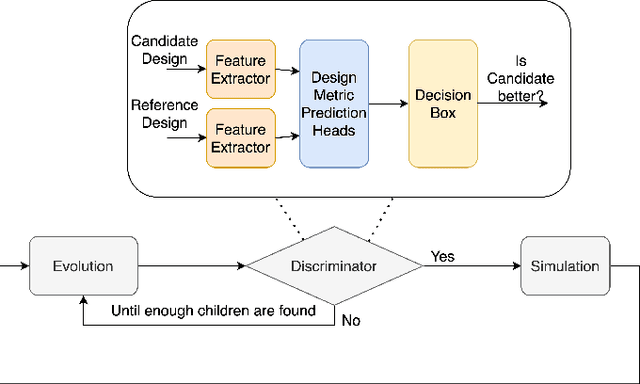
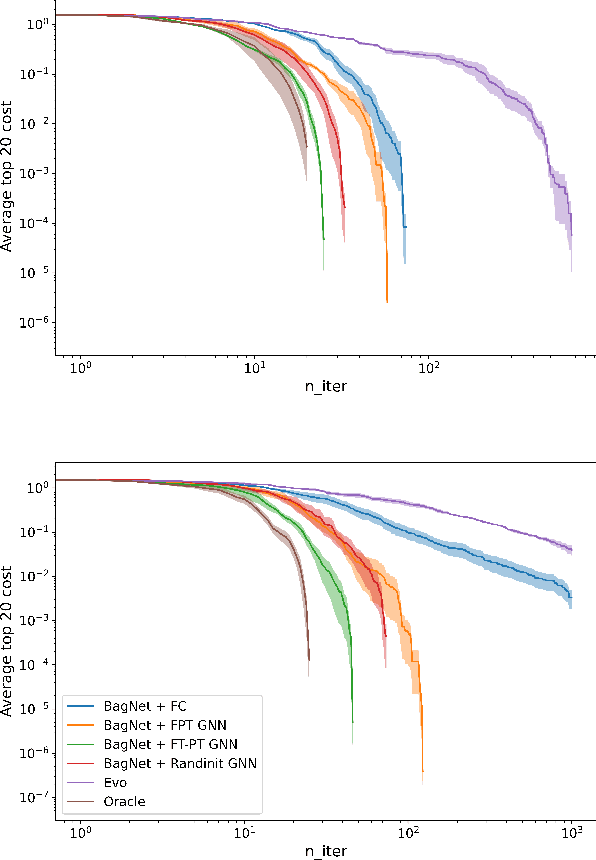

Being able to predict the performance of circuits without running expensive simulations is a desired capability that can catalyze automated design. In this paper, we present a supervised pretraining approach to learn circuit representations that can be adapted to new circuit topologies or unseen prediction tasks. We hypothesize that if we train a neural network (NN) that can predict the output DC voltages of a wide range of circuit instances it will be forced to learn generalizable knowledge about the role of each circuit element and how they interact with each other. The dataset for this supervised learning objective can be easily collected at scale since the required DC simulation to get ground truth labels is relatively cheap. This representation would then be helpful for few-shot generalization to unseen circuit metrics that require more time consuming simulations for obtaining the ground-truth labels. To cope with the variable topological structure of different circuits we describe each circuit as a graph and use graph neural networks (GNNs) to learn node embeddings. We show that pretraining GNNs on prediction of output node voltages can encourage learning representations that can be adapted to new unseen topologies or prediction of new circuit level properties with up to 10x more sample efficiency compared to a randomly initialized model. We further show that we can improve sample efficiency of prior SoTA model-based optimization methods by 2x (almost as good as using an oracle model) via fintuning pretrained GNNs as the feature extractor of the learned models.
DNS: Determinantal Point Process Based Neural Network Sampler for Ensemble Reinforcement Learning
Feb 06, 2022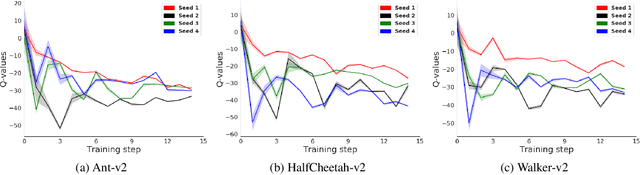
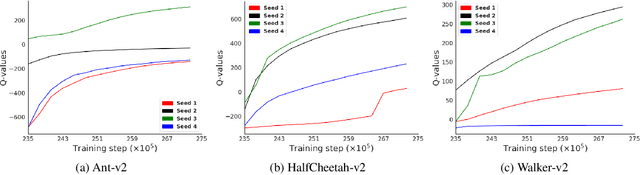
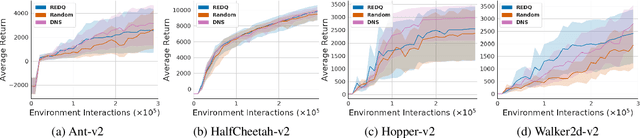
Application of ensemble of neural networks is becoming an imminent tool for advancing the state-of-the-art in deep reinforcement learning algorithms. However, training these large numbers of neural networks in the ensemble has an exceedingly high computation cost which may become a hindrance in training large-scale systems. In this paper, we propose DNS: a Determinantal Point Process based Neural Network Sampler that specifically uses k-dpp to sample a subset of neural networks for backpropagation at every training step thus significantly reducing the training time and computation cost. We integrated DNS in REDQ for continuous control tasks and evaluated on MuJoCo environments. Our experiments show that DNS augmented REDQ outperforms baseline REDQ in terms of average cumulative reward and achieves this using less than 50% computation when measured in FLOPS.