 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Interplay Between Sparsity and Training in Deep Reinforcement Learning
Jan 28, 2025



We study the benefits of different sparse architectures for deep reinforcement learning. In particular, we focus on image-based domains where spatially-biased and fully-connected architectures are common. Using these and several other architectures of equal capacity, we show that sparse structure has a significant effect on learning performance. We also observe that choosing the best sparse architecture for a given domain depends on whether the hidden layer weights are fixed or learned.
Meta-Gradient Search Control: A Method for Improving the Efficiency of Dyna-style Planning
Jun 27, 2024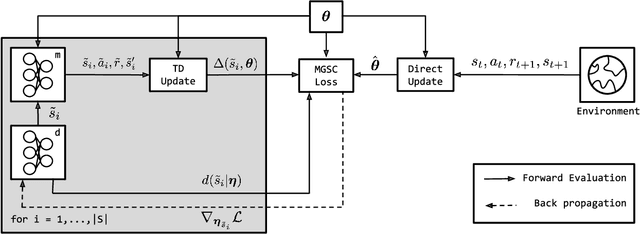

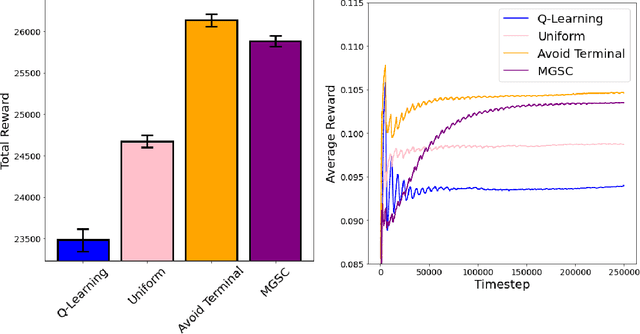
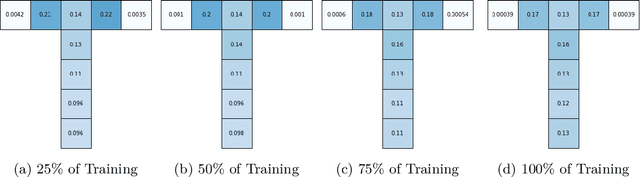
We study how a Reinforcement Learning (RL) system can remain sample-efficient when learning from an imperfect model of the environment. This is particularly challenging when the learning system is resource-constrained and in continual settings, where the environment dynamics change. To address these challenges, our paper introduces an online, meta-gradient algorithm that tunes a probability with which states are queried during Dyna-style planning. Our study compares the aggregate, empirical performance of this meta-gradient method to baselines that employ conventional sampling strategies. Results indicate that our method improves efficiency of the planning process, which, as a consequence, improves the sample-efficiency of the overall learning process. On the whole, we observe that our meta-learned solutions avoid several pathologies of conventional planning approaches, such as sampling inaccurate transitions and those that stall credit assignment. We believe these findings could prove useful, in future work, for designing model-based RL systems at scale.
MOTO: Offline Pre-training to Online Fine-tuning for Model-based Robot Learning
Jan 06, 2024We study the problem of offline pre-training and online fine-tuning for reinforcement learning from high-dimensional observations in the context of realistic robot tasks. Recent offline model-free approaches successfully use online fine-tuning to either improve the performance of the agent over the data collection policy or adapt to novel tasks. At the same time, model-based RL algorithms have achieved significant progress in sample efficiency and the complexity of the tasks they can solve, yet remain under-utilized in the fine-tuning setting. In this work, we argue that existing model-based offline RL methods are not suitable for offline-to-online fine-tuning in high-dimensional domains due to issues with distribution shifts, off-dynamics data, and non-stationary rewards. We propose an on-policy model-based method that can efficiently reuse prior data through model-based value expansion and policy regularization, while preventing model exploitation by controlling epistemic uncertainty. We find that our approach successfully solves tasks from the MetaWorld benchmark, as well as the Franka Kitchen robot manipulation environment completely from images. To the best of our knowledge, MOTO is the first method to solve this environment from pixels.
* This is an updated version of a manuscript that originally appeared at CoRL 2023. The project website is here https://sites.google.com/view/mo2o
Robust Route Planning with Distributional Reinforcement Learning in a Stochastic Road Network Environment
Apr 19, 2023



Route planning is essential to mobile robot navigation problems. In recent years, deep reinforcement learning (DRL) has been applied to learning optimal planning policies in stochastic environments without prior knowledge. However, existing works focus on learning policies that maximize the expected return, the performance of which can vary greatly when the level of stochasticity in the environment is high. In this work, we propose a distributional reinforcement learning based framework that learns return distributions which explicitly reflect environmental stochasticity. Policies based on the second-order stochastic dominance (SSD) relation can be used to make adjustable route decisions according to user preference on performance robustness. Our proposed method is evaluated in a simulated road network environment, and experimental results show that our method is able to plan the shortest routes that minimize stochasticity in travel time when robustness is preferred, while other state-of-the-art DRL methods are agnostic to environmental stochasticity.
Settling the Reward Hypothesis
Dec 20, 2022

The reward hypothesis posits that, "all of what we mean by goals and purposes can be well thought of as maximization of the expected value of the cumulative sum of a received scalar signal (reward)." We aim to fully settle this hypothesis. This will not conclude with a simple affirmation or refutation, but rather specify completely the implicit requirements on goals and purposes under which the hypothesis holds.
Should Models Be Accurate?
May 22, 2022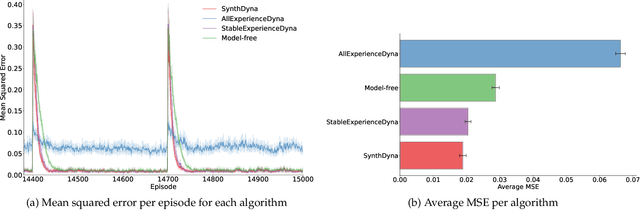
Model-based Reinforcement Learning (MBRL) holds promise for data-efficiency by planning with model-generated experience in addition to learning with experience from the environment. However, in complex or changing environments, models in MBRL will inevitably be imperfect, and their detrimental effects on learning can be difficult to mitigate. In this work, we question whether the objective of these models should be the accurate simulation of environment dynamics at all. We focus our investigations on Dyna-style planning in a prediction setting. First, we highlight and support three motivating points: a perfectly accurate model of environment dynamics is not practically achievable, is not necessary, and is not always the most useful anyways. Second, we introduce a meta-learning algorithm for training models with a focus on their usefulness to the learner instead of their accuracy in modelling the environment. Our experiments show that in a simple non-stationary environment, our algorithm enables faster learning than even using an accurate model built with domain-specific knowledge of the non-stationarity.
Adapting the Function Approximation Architecture in Online Reinforcement Learning
Jun 17, 2021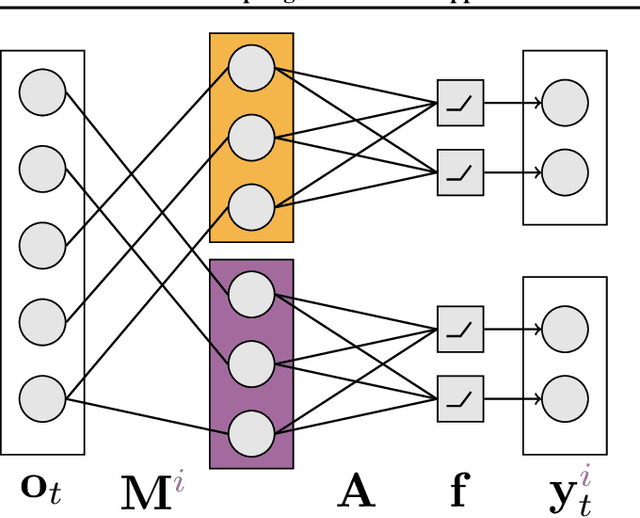
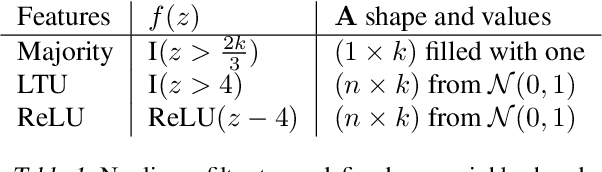
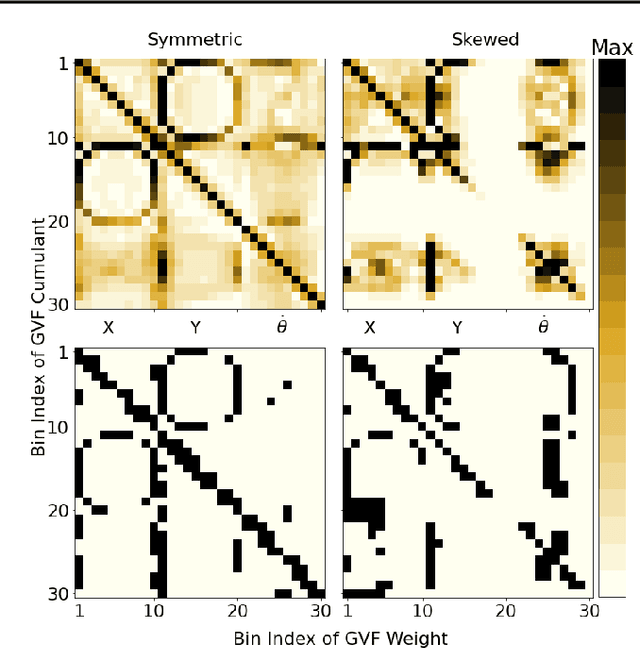

The performance of a reinforcement learning (RL) system depends on the computational architecture used to approximate a value function. Deep learning methods provide both optimization techniques and architectures for approximating nonlinear functions from noisy, high-dimensional observations. However, prevailing optimization techniques are not designed for strictly-incremental online updates. Nor are standard architectures designed for observations with an a priori unknown structure: for example, light sensors randomly dispersed in space. This paper proposes an online RL prediction algorithm with an adaptive architecture that efficiently finds useful nonlinear features. The algorithm is evaluated in a spatial domain with high-dimensional, stochastic observations. The algorithm outperforms non-adaptive baseline architectures and approaches the performance of an architecture given side-channel information. These results are a step towards scalable RL algorithms for more general problems, where the observation structure is not available.
Variational Filtering with Copula Models for SLAM
Aug 02, 2020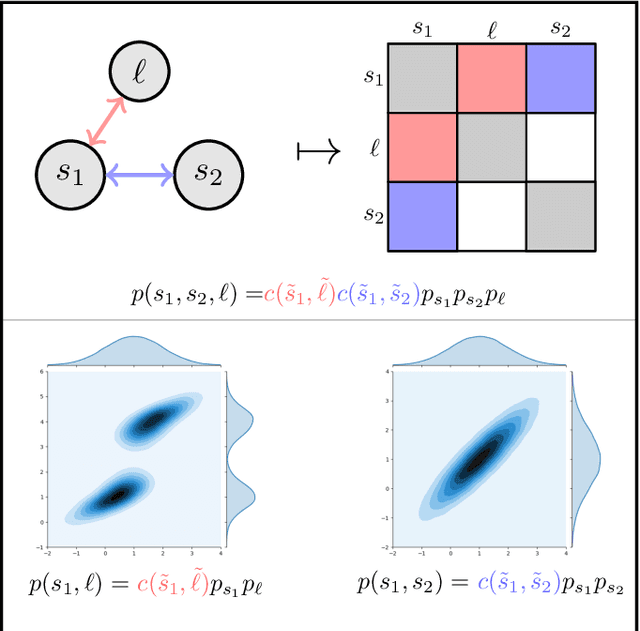

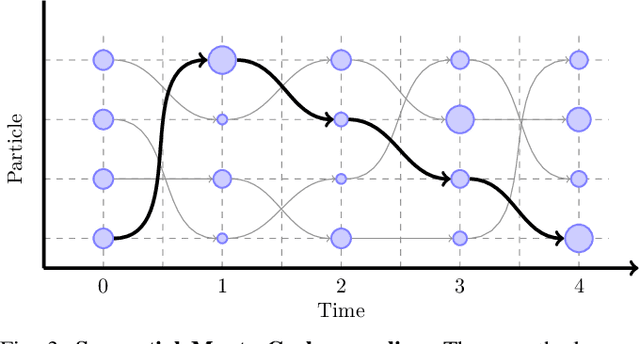

The ability to infer map variables and estimate pose is crucial to the operation of autonomous mobile robots. In most cases the shared dependency between these variables is modeled through a multivariate Gaussian distribution, but there are many situations where that assumption is unrealistic. Our paper shows how it is possible to relax this assumption and perform simultaneous localization and mapping (SLAM) with a larger class of distributions, whose multivariate dependency is represented with a copula model. We integrate the distribution model with copulas into a Sequential Monte Carlo estimator and show how unknown model parameters can be learned through gradient-based optimization. We demonstrate our approach is effective in settings where Gaussian assumptions are clearly violated, such as environments with uncertain data association and nonlinear transition models.
Autonomous Exploration Under Uncertainty via Deep Reinforcement Learning on Graphs
Jul 24, 2020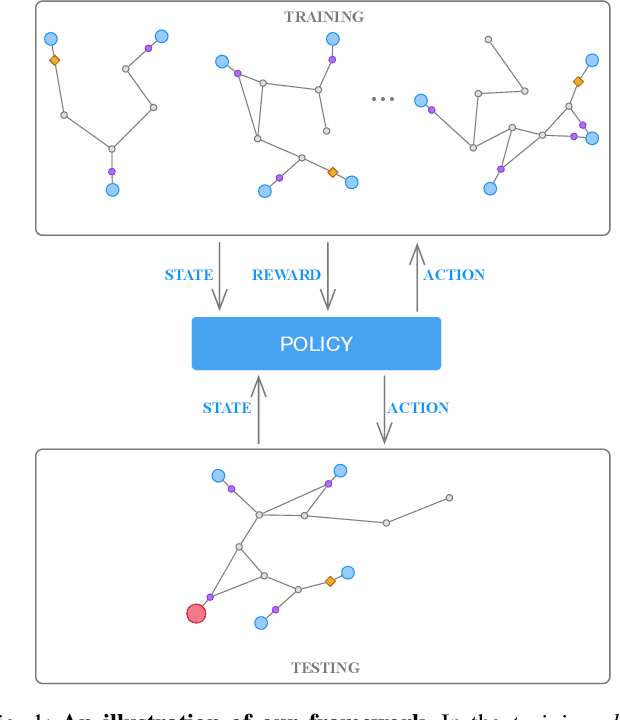
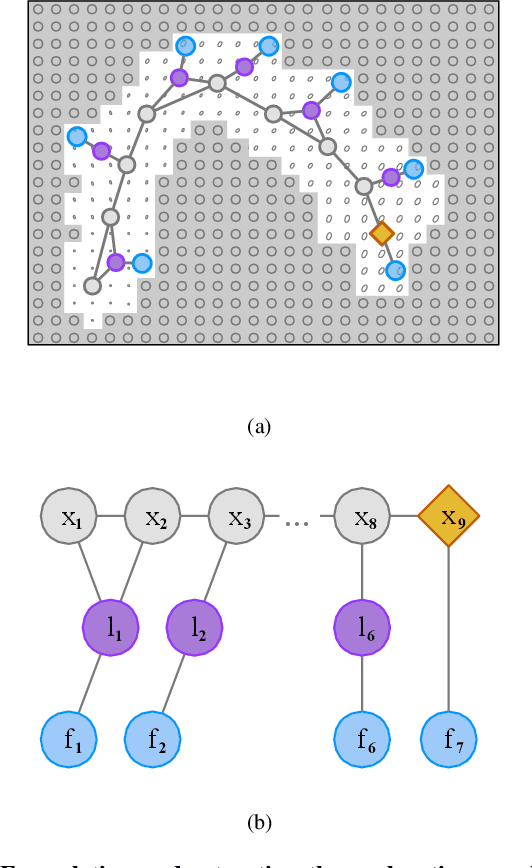
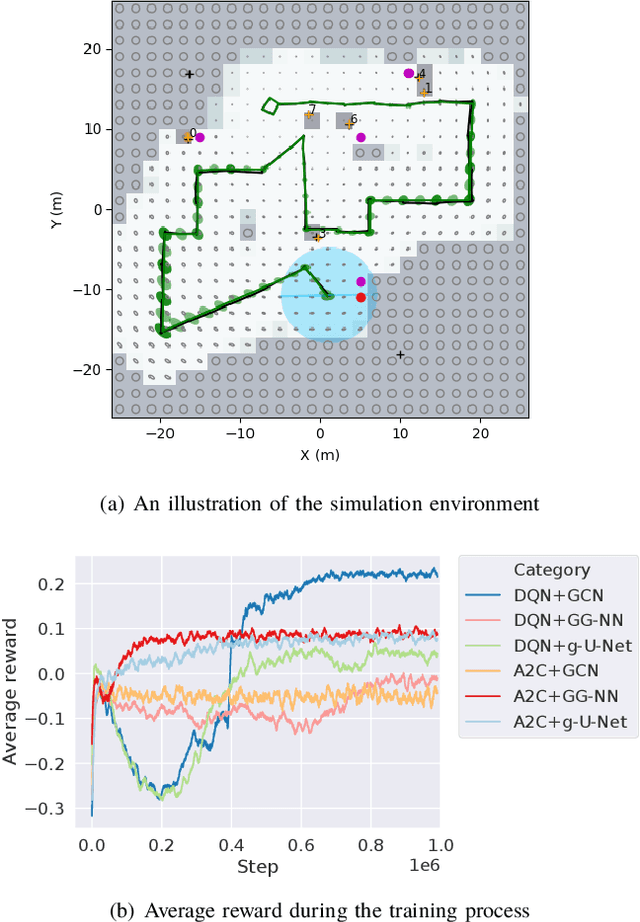
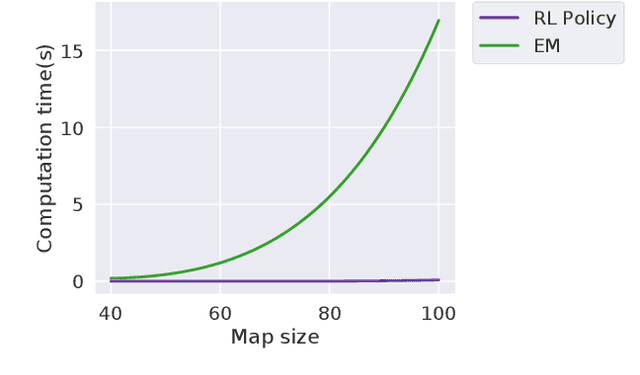
We consider an autonomous exploration problem in which a range-sensing mobile robot is tasked with accurately mapping the landmarks in an a priori unknown environment efficiently in real-time; it must choose sensing actions that both curb localization uncertainty and achieve information gain. For this problem, belief space planning methods that forward-simulate robot sensing and estimation may often fail in real-time implementation, scaling poorly with increasing size of the state, belief and action spaces. We propose a novel approach that uses graph neural networks (GNNs) in conjunction with deep reinforcement learning (DRL), enabling decision-making over graphs containing exploration information to predict a robot's optimal sensing action in belief space. The policy, which is trained in different random environments without human intervention, offers a real-time, scalable decision-making process whose high-performance exploratory sensing actions yield accurate maps and high rates of information gain.
Fusing Concurrent Orthogonal Wide-aperture Sonar Images for Dense Underwater 3D Reconstruction
Jul 20, 2020



We propose a novel approach to handling the ambiguity in elevation angle associated with the observations of a forward looking multi-beam imaging sonar, and the challenges it poses for performing an accurate 3D reconstruction. We utilize a pair of sonars with orthogonal axes of uncertainty to independently observe the same points in the environment from two different perspectives, and associate these observations. Using these concurrent observations, we can create a dense, fully defined point cloud at every time-step to aid in reconstructing the 3D geometry of underwater scenes. We will evaluate our method in the context of the current state of the art, for which strong assumptions on object geometry limit applicability to generalized 3D scenes. We will discuss results from laboratory tests that quantitatively benchmark our algorithm's reconstruction capabilities, and results from a real-world, tidal river basin which qualitatively demonstrate our ability to reconstruct a cluttered field of underwater objects.