 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Gradient Search Control: A Method for Improving the Efficiency of Dyna-style Planning
Jun 27, 2024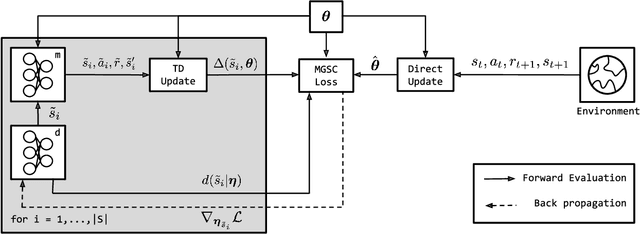

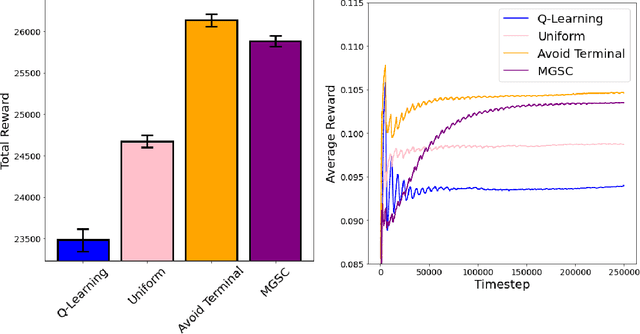
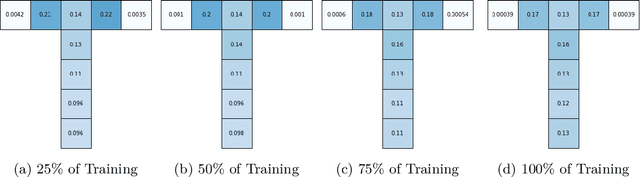
We study how a Reinforcement Learning (RL) system can remain sample-efficient when learning from an imperfect model of the environment. This is particularly challenging when the learning system is resource-constrained and in continual settings, where the environment dynamics change. To address these challenges, our paper introduces an online, meta-gradient algorithm that tunes a probability with which states are queried during Dyna-style planning. Our study compares the aggregate, empirical performance of this meta-gradient method to baselines that employ conventional sampling strategies. Results indicate that our method improves efficiency of the planning process, which, as a consequence, improves the sample-efficiency of the overall learning process. On the whole, we observe that our meta-learned solutions avoid several pathologies of conventional planning approaches, such as sampling inaccurate transitions and those that stall credit assignment. We believe these findings could prove useful, in future work, for designing model-based RL systems at scale.