 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ungrounded Alignment Problem
Aug 08, 2024



Modern machine learning systems have demonstrated substantial abilities with methods that either embrace or ignore human-provided knowledge, but combining benefits of both styles remains a challenge. One particular challenge involves designing learning systems that exhibit built-in responses to specific abstract stimulus patterns, yet are still plastic enough to be agnostic about the modality and exact form of their inputs. In this paper, we investigate what we call The Ungrounded Alignment Problem, which asks How can we build in predefined knowledge in a system where we don't know how a given stimulus will be grounded? This paper examines a simplified version of the general problem, where an unsupervised learner is presented with a sequence of images for the characters in a text corpus, and this learner is later evaluated on its ability to recognize specific (possibly rare) sequential patterns. Importantly, the learner is given no labels during learning or evaluation, but must map images from an unknown font or permutation to its correct class label. That is, at no point is our learner given labeled images, where an image vector is explicitly associated with a class label. Despite ample work in unsupervised and self-supervised loss functions, all current methods require a labeled fine-tuning phase to map the learned representations to correct classes. Finding this mapping in the absence of labels may seem a fool's errand, but our main result resolves this seeming paradox. We show that leveraging only letter bigram frequencies is sufficient for an unsupervised learner both to reliably associate images to class labels and to reliably identify trigger words in the sequence of inputs. More generally, this method suggests an approach for encoding specific desired innate behaviour in modality-agnostic models.
Towards model-free RL algorithms that scale well with unstructured data
Nov 03, 2023



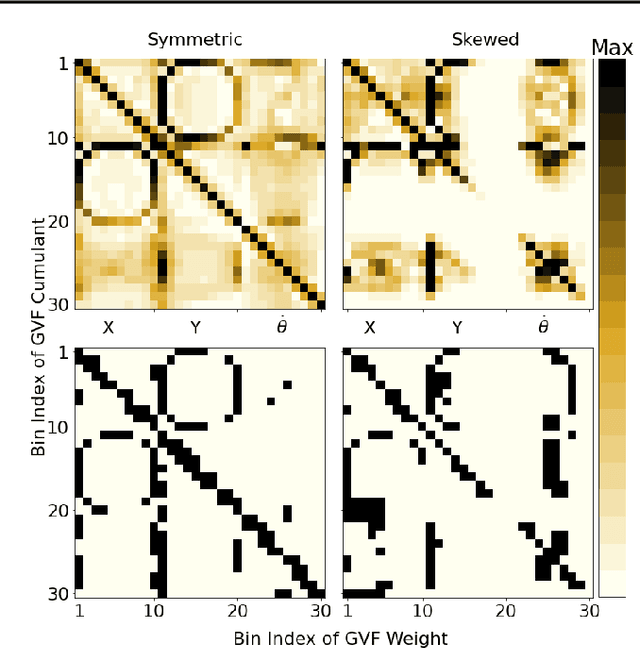
Conventional reinforcement learning (RL) algorithms exhibit broad generality in their theoretical formulation and high performance on several challenging domains when combined with powerful function approximation. However, developing RL algorithms that perform well across problems with unstructured observations at scale remains challenging because most function approximation methods rely on externally provisioned knowledge about the structure of the input for good performance (e.g. convolutional networks, graph neural networks, tile-coding). A common practice in RL is to evaluate algorithms on a single problem, or on problems with limited variation in the observation scale. RL practitioners lack a systematic way to study how well a single RL algorithm performs when instantiated across a range of problem scales, and they lack function approximation techniques that scale well with unstructured observations. We address these limitations by providing environments and algorithms to study scaling for unstructured observation vectors and flat action spaces. We introduce a family of combinatorial RL problems with an exponentially large state space and high-dimensional dynamics but where linear computation is sufficient to learn a (nonlinear) value function estimate for performant control. We provide an algorithm that constructs reward-relevant general value function (GVF) questions to find and exploit predictive structure directly from the experience stream. In an empirical evaluation of the approach on synthetic problems, we observe a sample complexity that scales linearly with the observation size. The proposed algorithm reliably outperforms a conventional deep RL algorithm on these scaling problems, and they exhibit several desirable auxiliary properties. These results suggest new algorithmic mechanisms by which algorithms can learn at scale from unstructured data.
Loss of Plasticity in Continual Deep Reinforcement Learning
Mar 13, 2023



The ability to learn continually is essential in a complex and changing world. In this paper, we characterize the behavior of canonical value-based deep reinforcement learning (RL) approaches under varying degrees of non-stationarity. In particular, we demonstrate that deep RL agents lose their ability to learn good policies when they cycle through a sequence of Atari 2600 games. This phenomenon is alluded to in prior work under various guises -- e.g., loss of plasticity, implicit under-parameterization, primacy bias, and capacity loss. We investigate this phenomenon closely at scale and analyze how the weights, gradients, and activations change over time in several experiments with varying dimensions (e.g., similarity between games, number of games, number of frames per game), with some experiments spanning 50 days and 2 billion environment interactions. Our analysis shows that the activation footprint of the network becomes sparser, contributing to the diminishing gradients. We investigate a remarkably simple mitigation strategy -- Concatenated ReLUs (CReLUs) activation function -- and demonstrate its effectiveness in facilitating continual learning in a changing environment.
The Frost Hollow Experiments: Pavlovian Signalling as a Path to Coordination and Communication Between Agents
Mar 17, 2022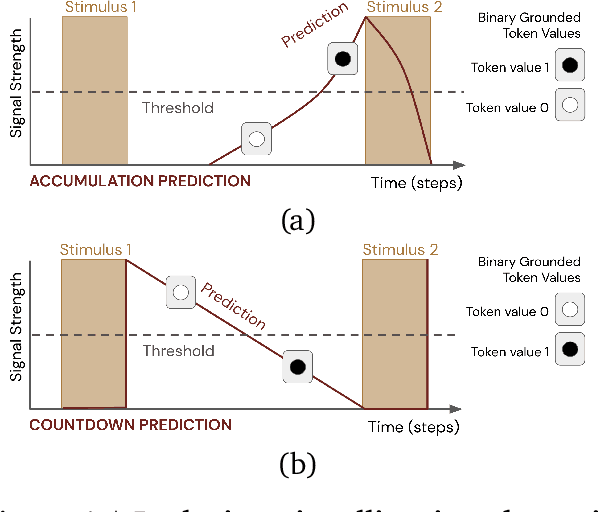

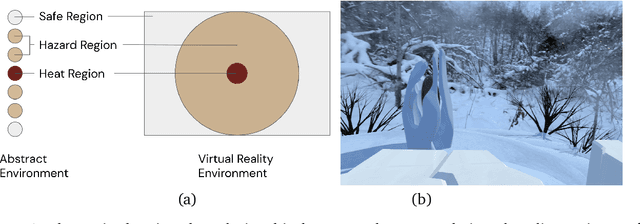
Learned communication between agents is a powerful tool when approaching decision-making problems that are hard to overcome by any single agent in isolation. However, continual coordination and communication learning between machine agents or human-machine partnerships remains a challenging open problem. As a stepping stone toward solving the continual communication learning problem, in this paper we contribute a multi-faceted study into what we term Pavlovian signalling -- a process by which learned, temporally extended predictions made by one agent inform decision-making by another agent with different perceptual access to their shared environment. We seek to establish how different temporal processes and representational choices impact Pavlovian signalling between learning agents. To do so, we introduce a partially observable decision-making domain we call the Frost Hollow. In this domain a prediction learning agent and a reinforcement learning agent are coupled into a two-part decision-making system that seeks to acquire sparse reward while avoiding time-conditional hazards. We evaluate two domain variations: 1) machine prediction and control learning in a linear walk, and 2) a prediction learning machine interacting with a human participant in a virtual reality environment. Our results showcase the speed of learning for Pavlovian signalling, the impact that different temporal representations do (and do not) have on agent-agent coordination, and how temporal aliasing impacts agent-agent and human-agent interactions differently. As a main contribution, we establish Pavlovian signalling as a natural bridge between fixed signalling paradigms and fully adaptive communication learning. Our results therefore point to an actionable, constructivist path towards continual communication learning between reinforcement learning agents, with potential impact in a range of real-world settings.
Pavlovian Signalling with General Value Functions in Agent-Agent Temporal Decision Making
Jan 11, 2022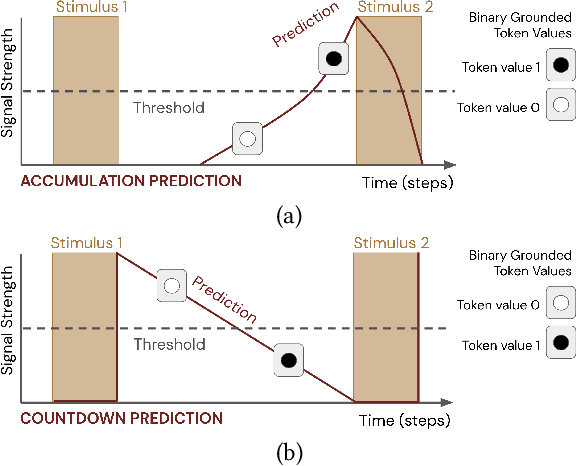
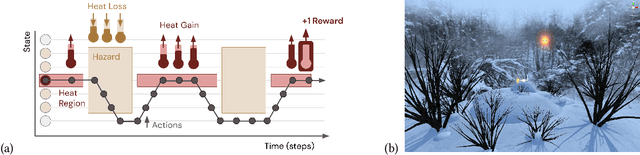
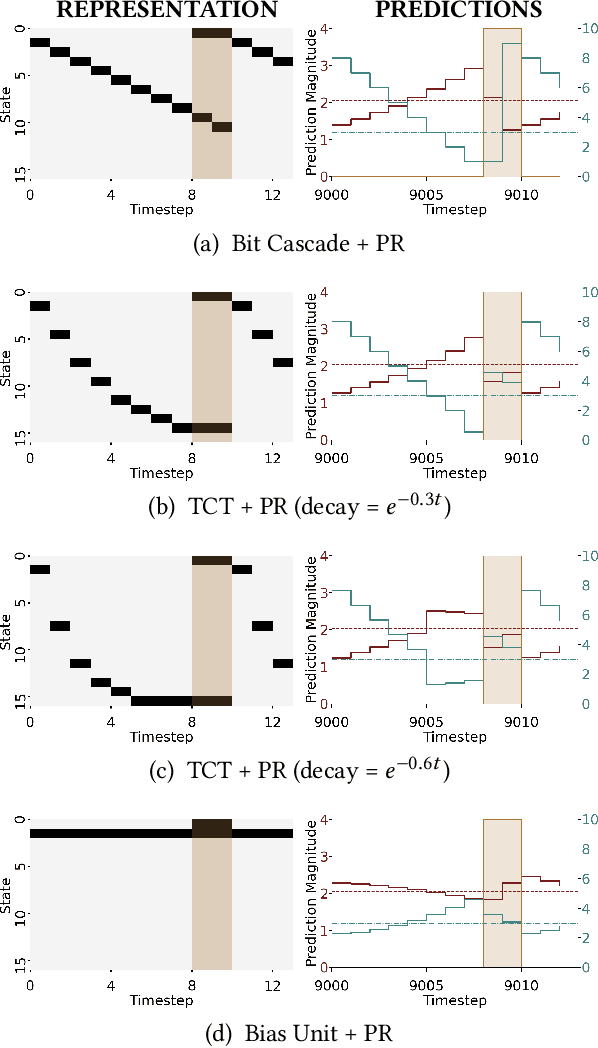
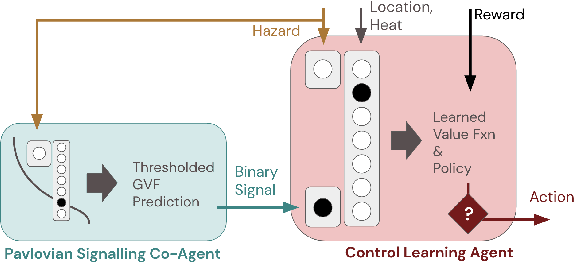
In this paper, we contribute a multi-faceted study into Pavlovian signalling -- a process by which learned, temporally extended predictions made by one agent inform decision-making by another agent. Signalling is intimately connected to time and timing. In service of generating and receiving signals, humans and other animals are known to represent time, determine time since past events, predict the time until a future stimulus, and both recognize and generate patterns that unfold in time. We investigate how different temporal processes impact coordination and signalling between learning agents by introducing a partially observable decision-making domain we call the Frost Hollow. In this domain, a prediction learning agent and a reinforcement learning agent are coupled into a two-part decision-making system that works to acquire sparse reward while avoiding time-conditional hazards. We evaluate two domain variations: machine agents interacting in a seven-state linear walk, and human-machine interaction in a virtual-reality environment. Our results showcase the speed of learning for Pavlovian signalling, the impact that different temporal representations do (and do not) have on agent-agent coordination, and how temporal aliasing impacts agent-agent and human-agent interactions differently. As a main contribution, we establish Pavlovian signalling as a natural bridge between fixed signalling paradigms and fully adaptive communication learning between two agents. We further show how to computationally build this adaptive signalling process out of a fixed signalling process, characterized by fast continual prediction learning and minimal constraints on the nature of the agent receiving signals. Our results therefore suggest an actionable, constructivist path towards communication learning between reinforcement learning agents.
Assessing Human Interaction in Virtual Reality With Continually Learning Prediction Agents Based on Reinforcement Learning Algorithms: A Pilot Study
Dec 14, 2021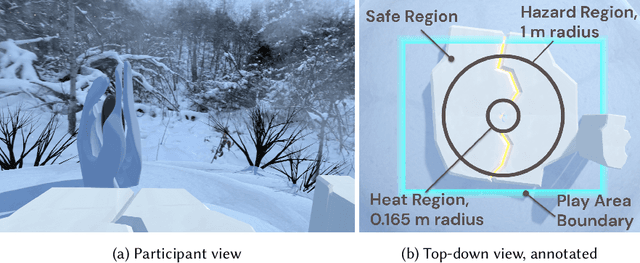
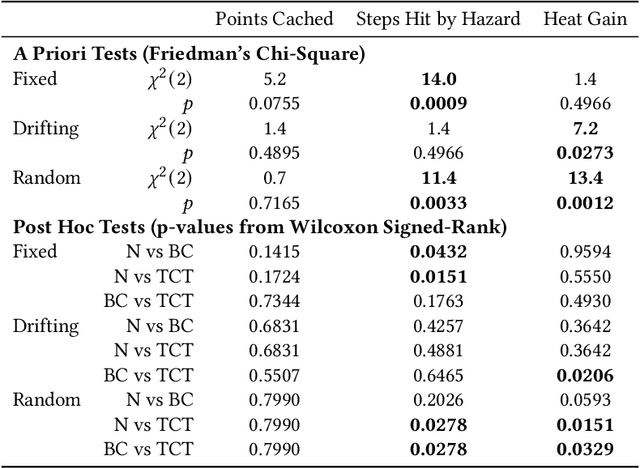
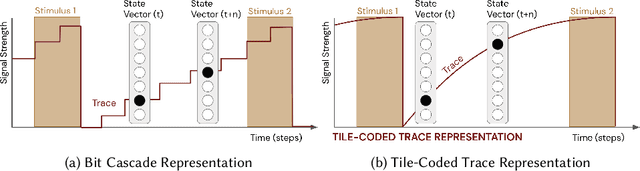
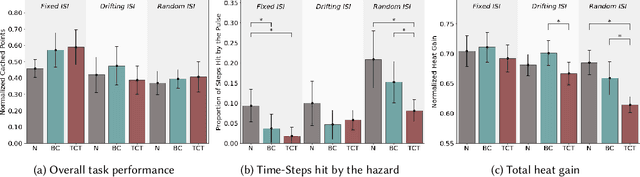
Artificial intelligence systems increasingly involve continual learning to enable flexibility in general situations that are not encountered during system training. Human interaction with autonomous systems is broadly studied, but research has hitherto under-explored interactions that occur while the system is actively learning, and can noticeably change its behaviour in minutes. In this pilot study, we investigate how the interaction between a human and a continually learning prediction agent develops as the agent develops competency. Additionally, we compare two different agent architectures to assess how representational choices in agent design affect the human-agent interaction. We develop a virtual reality environment and a time-based prediction task wherein learned predictions from a reinforcement learning (RL) algorithm augment human predictions. We assess how a participant's performance and behaviour in this task differs across agent types, using both quantitative and qualitative analyses. Our findings suggest that human trust of the system may be influenced by early interactions with the agent, and that trust in turn affects strategic behaviour, but limitations of the pilot study rule out any conclusive statement. We identify trust as a key feature of interaction to focus on when considering RL-based technologies, and make several recommendations for modification to this study in preparation for a larger-scale investigation. A video summary of this paper can be found at https://youtu.be/oVYJdnBqTwQ .
Adapting the Function Approximation Architecture in Online Reinforcement Learning
Jun 17, 2021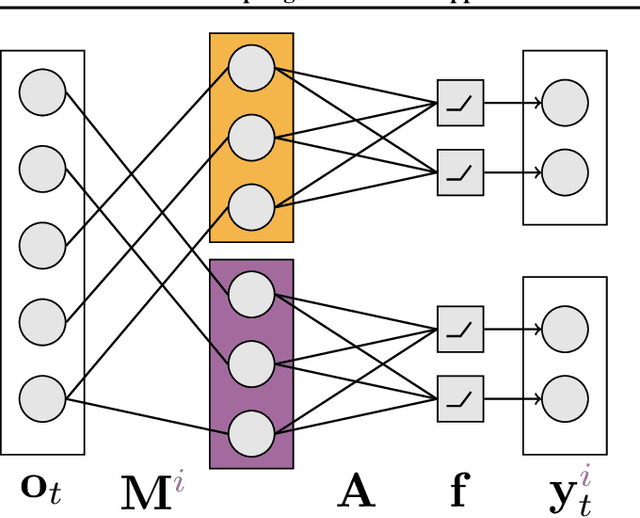
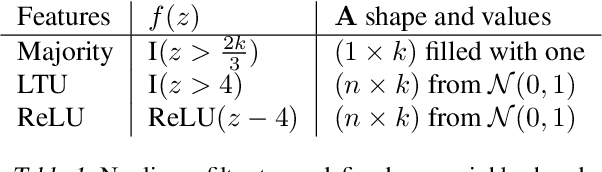

The performance of a reinforcement learning (RL) system depends on the computational architecture used to approximate a value function. Deep learning methods provide both optimization techniques and architectures for approximating nonlinear functions from noisy, high-dimensional observations. However, prevailing optimization techniques are not designed for strictly-incremental online updates. Nor are standard architectures designed for observations with an a priori unknown structure: for example, light sensors randomly dispersed in space. This paper proposes an online RL prediction algorithm with an adaptive architecture that efficiently finds useful nonlinear features. The algorithm is evaluated in a spatial domain with high-dimensional, stochastic observations. The algorithm outperforms non-adaptive baseline architectures and approaches the performance of an architecture given side-channel information. These results are a step towards scalable RL algorithms for more general problems, where the observation structure is not available.
On Inductive Biases in Deep Reinforcement Learning
Jul 05, 2019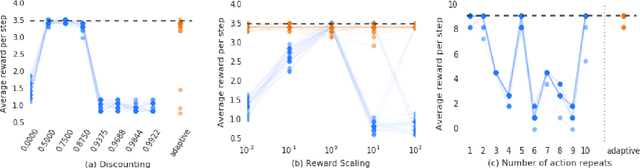
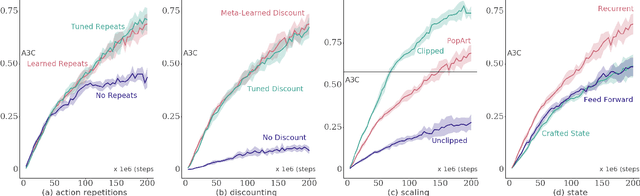
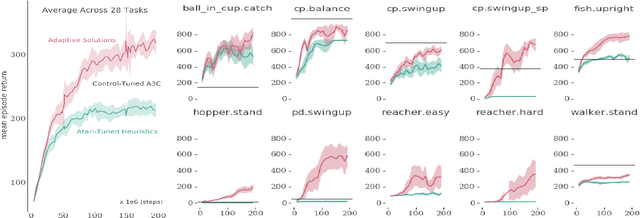
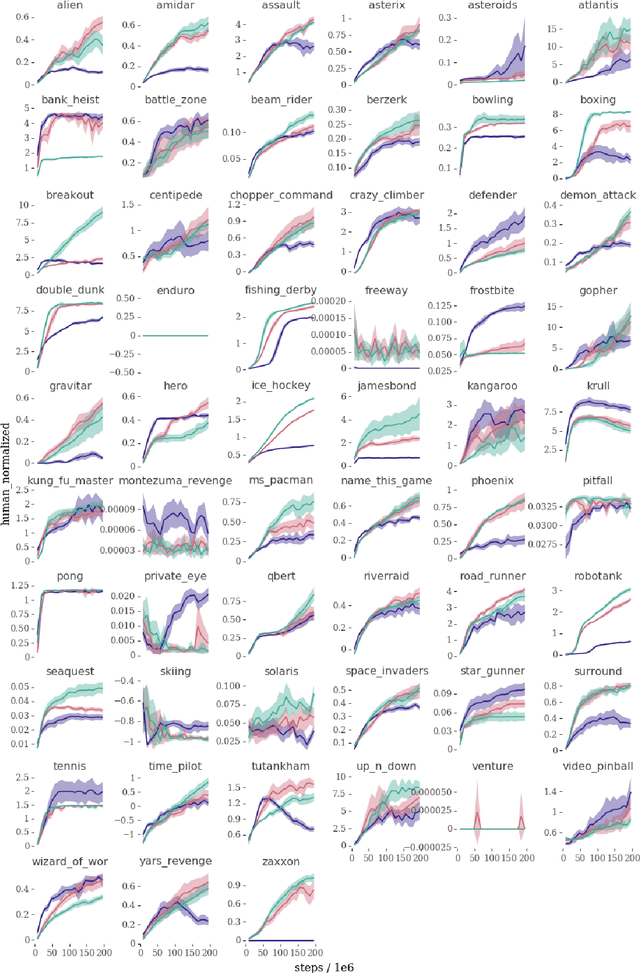
Many deep reinforcement learning algorithms contain inductive biases that sculpt the agent's objective and its interface to the environment. These inductive biases can take many forms, including domain knowledge and pretuned hyper-parameters. In general, there is a trade-off between generality and performance when algorithms use such biases. Stronger biases can lead to faster learning, but weaker biases can potentially lead to more general algorithms. This trade-off is important because inductive biases are not free; substantial effort may be required to obtain relevant domain knowledge or to tune hyper-parameters effectively. In this paper, we re-examine several domain-specific components that bias the objective and the environmental interface of common deep reinforcement learning agents. We investigated whether the performance deteriorates when these components are replaced with adaptive solutions from the literature. In our experiments, performance sometimes decreased with the adaptive components, as one might expect when comparing to components crafted for the domain, but sometimes the adaptive components performed better. We investigated the main benefit of having fewer domain-specific components, by comparing the learning performance of the two systems on a different set of continuous control problems, without additional tuning of either system. As hypothesized, the system with adaptive components performed better on many of the new tasks.
Ray Interference: a Source of Plateaus in Deep Reinforcement Learning
Apr 25, 2019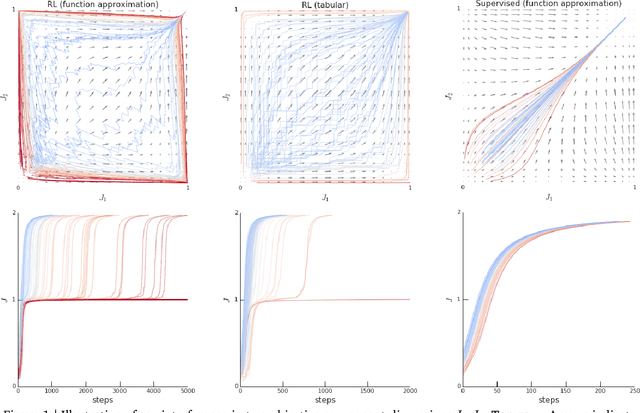
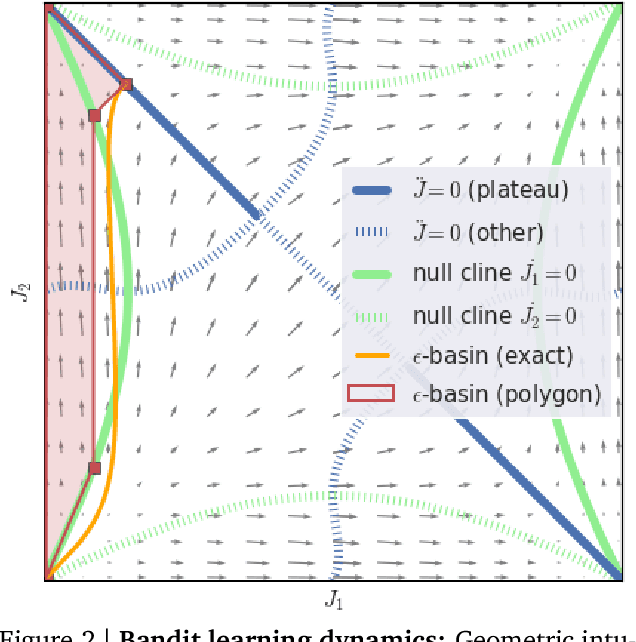
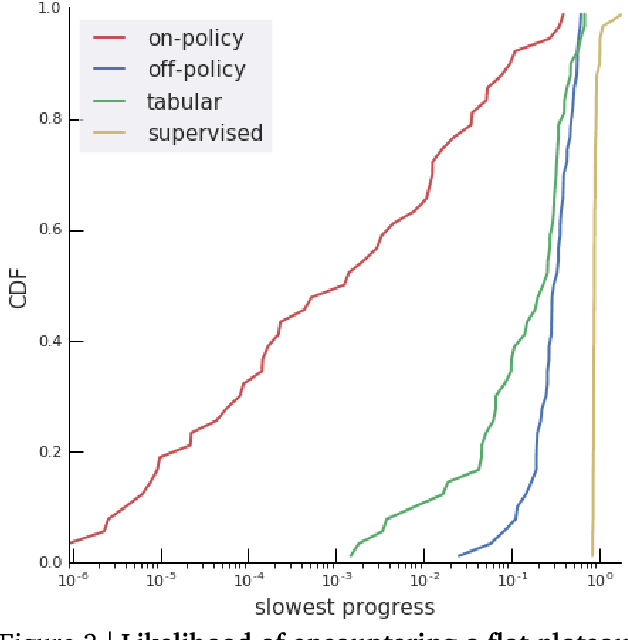
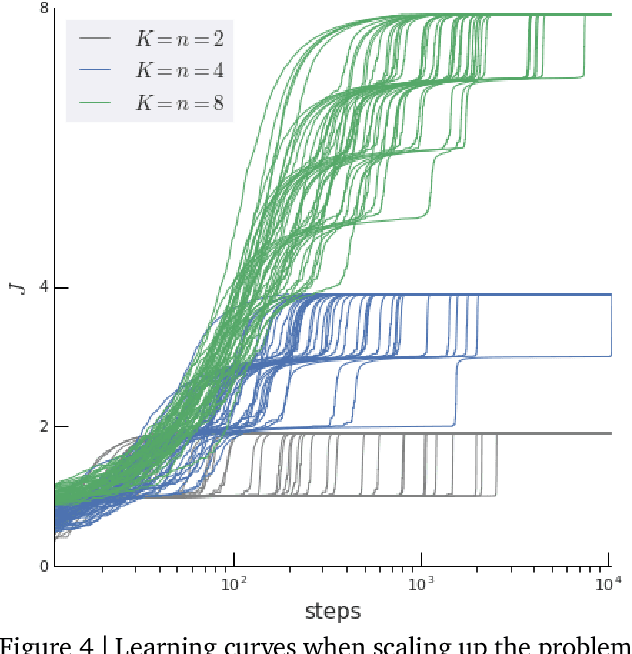
Rather than proposing a new method, this paper investigates an issue present in existing learning algorithms. We study the learning dynamics of reinforcement learning (RL), specifically a characteristic coupling between learning and data generation that arises because RL agents control their future data distribution. In the presence of function approximation, this coupling can lead to a problematic type of 'ray interference', characterized by learning dynamics that sequentially traverse a number of performance plateaus, effectively constraining the agent to learn one thing at a time even when learning in parallel is better. We establish the conditions under which ray interference occurs, show its relation to saddle points and obtain the exact learning dynamics in a restricted setting. We characterize a number of its properties and discuss possible remedies.
Deep Reinforcement Learning and the Deadly Triad
Dec 06, 2018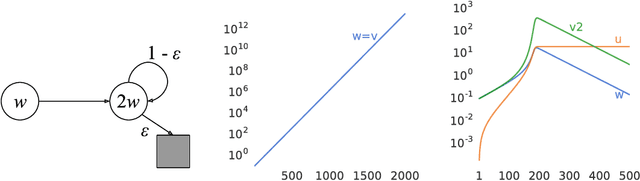
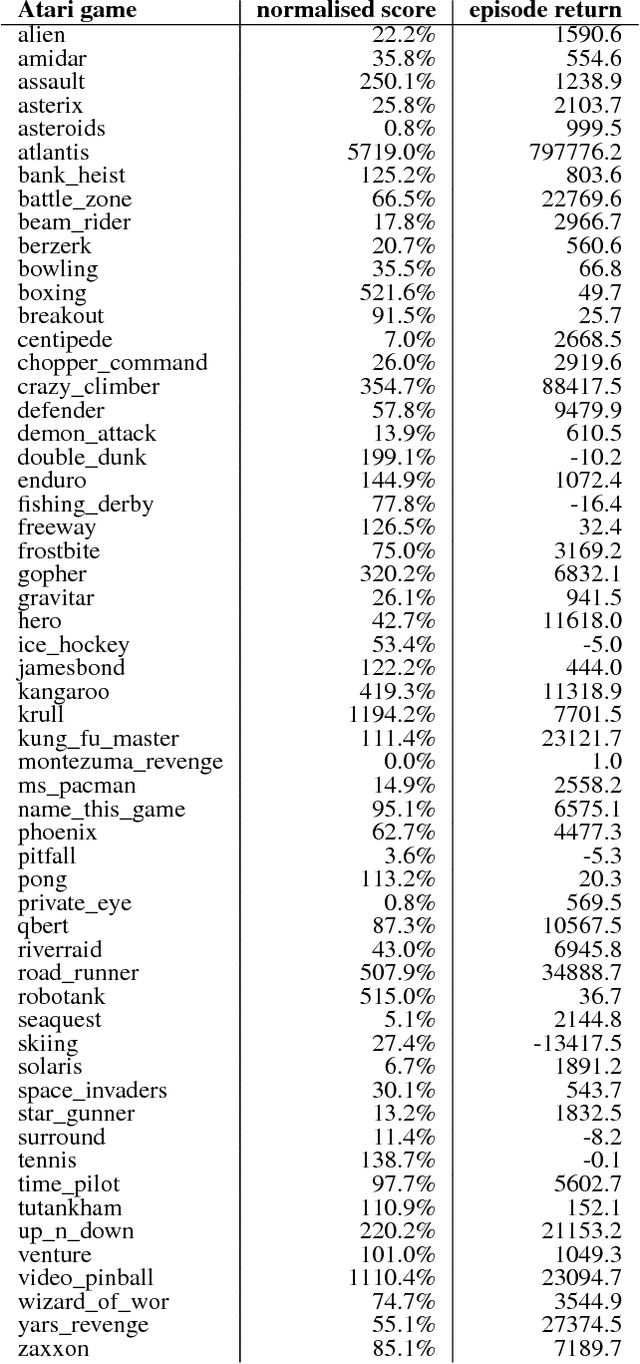
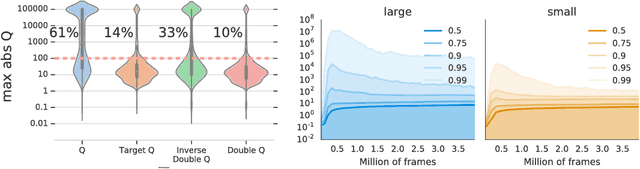
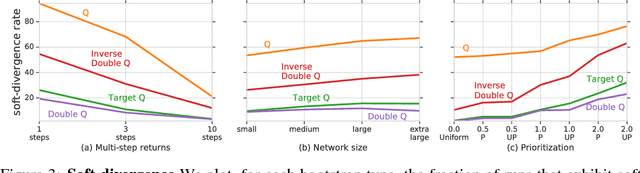
We know from reinforcement learning theory that temporal difference learning can fail in certain cases. Sutton and Barto (2018) identify a deadly triad of function approximation, bootstrapping, and off-policy learning. When these three properties are combined, learning can diverge with the value estimates becoming unbounded. However, several algorithms successfully combine these three properties, which indicates that there is at least a partial gap in our understanding. In this work, we investigate the impact of the deadly triad in practice, in the context of a family of popular deep reinforcement learning models - deep Q-networks trained with experience replay - analysing how the components of this system play a role in the emergence of the deadly triad, and in the agent's performance