 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany-Shot In-Context Learning
Apr 17, 2024



Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases and can learn high-dimensional functions with numerical inputs. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Towards model-free RL algorithms that scale well with unstructured data
Nov 03, 2023



Conventional reinforcement learning (RL) algorithms exhibit broad generality in their theoretical formulation and high performance on several challenging domains when combined with powerful function approximation. However, developing RL algorithms that perform well across problems with unstructured observations at scale remains challenging because most function approximation methods rely on externally provisioned knowledge about the structure of the input for good performance (e.g. convolutional networks, graph neural networks, tile-coding). A common practice in RL is to evaluate algorithms on a single problem, or on problems with limited variation in the observation scale. RL practitioners lack a systematic way to study how well a single RL algorithm performs when instantiated across a range of problem scales, and they lack function approximation techniques that scale well with unstructured observations. We address these limitations by providing environments and algorithms to study scaling for unstructured observation vectors and flat action spaces. We introduce a family of combinatorial RL problems with an exponentially large state space and high-dimensional dynamics but where linear computation is sufficient to learn a (nonlinear) value function estimate for performant control. We provide an algorithm that constructs reward-relevant general value function (GVF) questions to find and exploit predictive structure directly from the experience stream. In an empirical evaluation of the approach on synthetic problems, we observe a sample complexity that scales linearly with the observation size. The proposed algorithm reliably outperforms a conventional deep RL algorithm on these scaling problems, and they exhibit several desirable auxiliary properties. These results suggest new algorithmic mechanisms by which algorithms can learn at scale from unstructured data.
Loss of Plasticity in Continual Deep Reinforcement Learning
Mar 13, 2023



The ability to learn continually is essential in a complex and changing world. In this paper, we characterize the behavior of canonical value-based deep reinforcement learning (RL) approaches under varying degrees of non-stationarity. In particular, we demonstrate that deep RL agents lose their ability to learn good policies when they cycle through a sequence of Atari 2600 games. This phenomenon is alluded to in prior work under various guises -- e.g., loss of plasticity, implicit under-parameterization, primacy bias, and capacity loss. We investigate this phenomenon closely at scale and analyze how the weights, gradients, and activations change over time in several experiments with varying dimensions (e.g., similarity between games, number of games, number of frames per game), with some experiments spanning 50 days and 2 billion environment interactions. Our analysis shows that the activation footprint of the network becomes sparser, contributing to the diminishing gradients. We investigate a remarkably simple mitigation strategy -- Concatenated ReLUs (CReLUs) activation function -- and demonstrate its effectiveness in facilitating continual learning in a changing environment.
Investigating the Properties of Neural Network Representations in Reinforcement Learning
Mar 30, 2022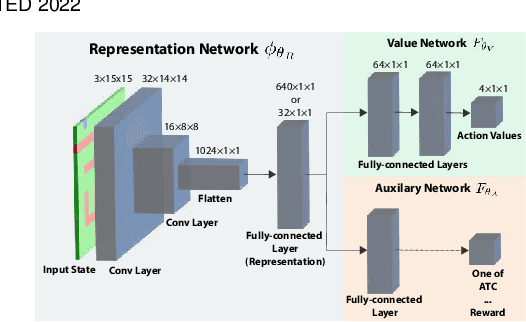

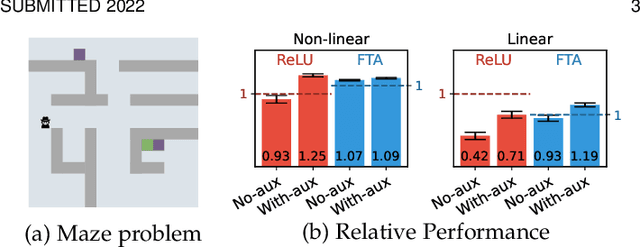

In this paper we investigate the properties of representations learned by deep reinforcement learning systems. Much of the earlier work in representation learning for reinforcement learning focused on designing fixed-basis architectures to achieve properties thought to be desirable, such as orthogonality and sparsity. In contrast, the idea behind deep reinforcement learning methods is that the agent designer should not encode representational properties, but rather that the data stream should determine the properties of the representation -- good representations emerge under appropriate training schemes. In this paper we bring these two perspectives together, empirically investigating the properties of representations that support transfer in reinforcement learning. This analysis allows us to provide novel hypotheses regarding impact of auxiliary tasks in end-to-end training of non-linear reinforcement learning methods. We introduce and measure six representational properties over more than 25 thousand agent-task settings. We consider DQN agents with convolutional networks in a pixel-based navigation environment. We develop a method to better understand \emph{why} some representations work better for transfer, through a systematic approach varying task similarity and measuring and correlating representation properties with transfer performance.