 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Exploiting Weight Update Sparsity for Communication-Efficient Distributed RL
Feb 03, 2026Reinforcement learning (RL) is a critical component for post-training large language models (LLMs). However, in bandwidth-constrained distributed RL, scalability is often bottlenecked by the synchronization of policy weights from trainers to inference workers, particularly over commodity networks or in decentralized settings. While recent studies suggest that RL updates modify only a small fraction of model parameters, these observations are typically based on coarse checkpoint differences. We present a systematic empirical study of weight-update sparsity at both step-level and multi-step granularities, examining its evolution across training dynamics, off-policy delay, and model scale. We find that update sparsity is consistently high, frequently exceeding 99% across practically relevant settings. Leveraging this structure, we propose PULSE (Patch Updates via Lossless Sparse Encoding), a simple yet highly efficient lossless weight synchronization method that transmits only the indices and values of modified parameters. PULSE is robust to transmission errors and avoids floating-point drift inherent in additive delta schemes. In bandwidth-constrained decentralized environments, our approach achieves over 100x (14 GB to ~108 MB) communication reduction while maintaining bit-identical training dynamics and performance compared to full weight synchronization. By exploiting this structure, PULSE enables decentralized RL training to approach centralized throughput, reducing the bandwidth required for weight synchronization from 20 Gbit/s to 0.2 Gbit/s to maintain high GPU utilization.
How Reliable are Confidence Estimators for Large Reasoning Models? A Systematic Benchmark on High-Stakes Domains
Jan 13, 2026The miscalibration of Large Reasoning Models (LRMs) undermines their reliability in high-stakes domains, necessitating methods to accurately estimate the confidence of their long-form, multi-step outputs. To address this gap, we introduce the Reasoning Model Confidence estimation Benchmark (RMCB), a public resource of 347,496 reasoning traces from six popular LRMs across different architectural families. The benchmark is constructed from a diverse suite of datasets spanning high-stakes domains, including clinical, financial, legal, and mathematical reasoning, alongside complex general reasoning benchmarks, with correctness annotations provided for all samples. Using RMCB, we conduct a large-scale empirical evaluation of over ten distinct representation-based methods, spanning sequential, graph-based, and text-based architectures. Our central finding is a persistent trade-off between discrimination (AUROC) and calibration (ECE): text-based encoders achieve the best AUROC (0.672), while structurally-aware models yield the best ECE (0.148), with no single method dominating both. Furthermore, we find that increased architectural complexity does not reliably outperform simpler sequential baselines, suggesting a performance ceiling for methods relying solely on chunk-level hidden states. This work provides the most comprehensive benchmark for this task to date, establishing rigorous baselines and demonstrating the limitations of current representation-based paradigms.
Calibrating LLM Confidence by Probing Perturbed Representation Stability
May 27, 2025Miscalibration in Large Language Models (LLMs) undermines their reliability, highlighting the need for accurate confidence estimation. We introduce CCPS (Calibrating LLM Confidence by Probing Perturbed Representation Stability), a novel method analyzing internal representational stability in LLMs. CCPS applies targeted adversarial perturbations to final hidden states, extracts features reflecting the model's response to these perturbations, and uses a lightweight classifier to predict answer correctness. CCPS was evaluated on LLMs from 8B to 32B parameters (covering Llama, Qwen, and Mistral architectures) using MMLU and MMLU-Pro benchmarks in both multiple-choice and open-ended formats. Our results show that CCPS significantly outperforms current approaches. Across four LLMs and three MMLU variants, CCPS reduces Expected Calibration Error by approximately 55% and Brier score by 21%, while increasing accuracy by 5 percentage points, Area Under the Precision-Recall Curve by 4 percentage points, and Area Under the Receiver Operating Characteristic Curve by 6 percentage points, all relative to the strongest prior method. CCPS delivers an efficient, broadly applicable, and more accurate solution for estimating LLM confidence, thereby improving their trustworthiness.
GVFs in the Real World: Making Predictions Online for Water Treatment
Dec 04, 2023In this paper we investigate the use of reinforcement-learning based prediction approaches for a real drinking-water treatment plant. Developing such a prediction system is a critical step on the path to optimizing and automating water treatment. Before that, there are many questions to answer about the predictability of the data, suitable neural network architectures, how to overcome partial observability and more. We first describe this dataset, and highlight challenges with seasonality, nonstationarity, partial observability, and heterogeneity across sensors and operation modes of the plant. We then describe General Value Function (GVF) predictions -- discounted cumulative sums of observations -- and highlight why they might be preferable to classical n-step predictions common in time series prediction. We discuss how to use offline data to appropriately pre-train our temporal difference learning (TD) agents that learn these GVF predictions, including how to select hyperparameters for online fine-tuning in deployment. We find that the TD-prediction agent obtains an overall lower normalized mean-squared error than the n-step prediction agent. Finally, we show the importance of learning in deployment, by comparing a TD agent trained purely offline with no online updating to a TD agent that learns online. This final result is one of the first to motivate the importance of adapting predictions in real-time, for non-stationary high-volume systems in the real world.
* Published in Machine Learning (2023)
Investigating the Properties of Neural Network Representations in Reinforcement Learning
Mar 30, 2022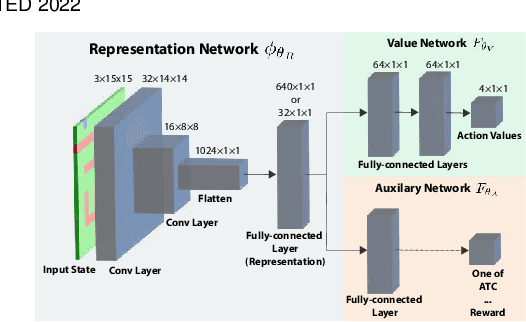

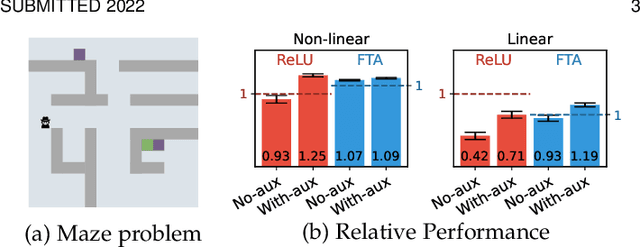

In this paper we investigate the properties of representations learned by deep reinforcement learning systems. Much of the earlier work in representation learning for reinforcement learning focused on designing fixed-basis architectures to achieve properties thought to be desirable, such as orthogonality and sparsity. In contrast, the idea behind deep reinforcement learning methods is that the agent designer should not encode representational properties, but rather that the data stream should determine the properties of the representation -- good representations emerge under appropriate training schemes. In this paper we bring these two perspectives together, empirically investigating the properties of representations that support transfer in reinforcement learning. This analysis allows us to provide novel hypotheses regarding impact of auxiliary tasks in end-to-end training of non-linear reinforcement learning methods. We introduce and measure six representational properties over more than 25 thousand agent-task settings. We consider DQN agents with convolutional networks in a pixel-based navigation environment. We develop a method to better understand \emph{why} some representations work better for transfer, through a systematic approach varying task similarity and measuring and correlating representation properties with transfer performance.
Scalable Transfer Evolutionary Optimization: Coping with Big Task Instances
Dec 03, 2020
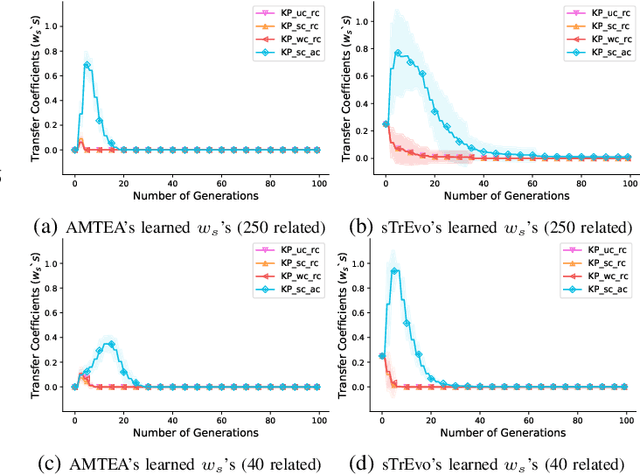

In today's digital world, we are confronted with an explosion of data and models produced and manipulated by numerous large-scale IoT/cloud-based applications. Under such settings, existing transfer evolutionary optimization frameworks grapple with satisfying two important quality attributes, namely scalability against a growing number of source tasks and online learning agility against sparsity of relevant sources to the target task of interest. Satisfying these attributes shall facilitate practical deployment of transfer optimization to big source instances as well as simultaneously curbing the threat of negative transfer. While applications of existing algorithms are limited to tens of source tasks, in this paper, we take a quantum leap forward in enabling two orders of magnitude scale-up in the number of tasks; i.e., we efficiently handle scenarios with up to thousands of source problem instances. We devise a novel transfer evolutionary optimization framework comprising two co-evolving species for joint evolutions in the space of source knowledge and in the search space of solutions to the target problem. In particular, co-evolution enables the learned knowledge to be orchestrated on the fly, expediting convergence in the target optimization task. We have conducted an extensive series of experiments across a set of practically motivated discrete and continuous optimization examples comprising a large number of source problem instances, of which only a small fraction show source-target relatedness. The experimental results strongly validate the efficacy of our proposed framework with two salient features of scalability and online learning agility.
Genetic Neural Architecture Search for automatic assessment of human sperm images
Sep 20, 2019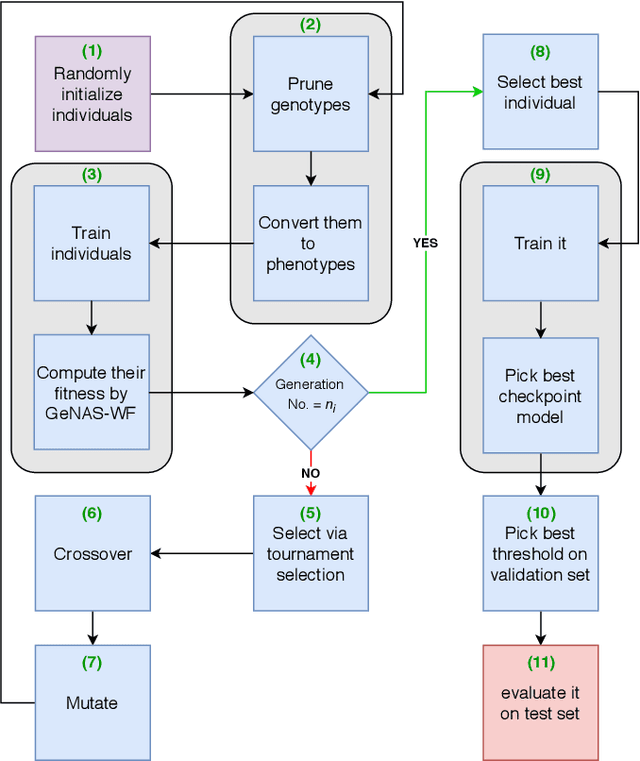
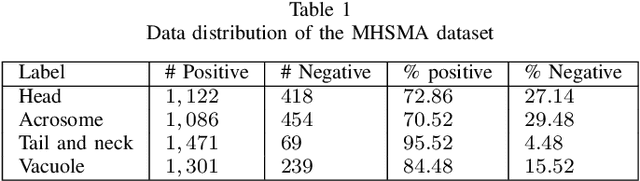
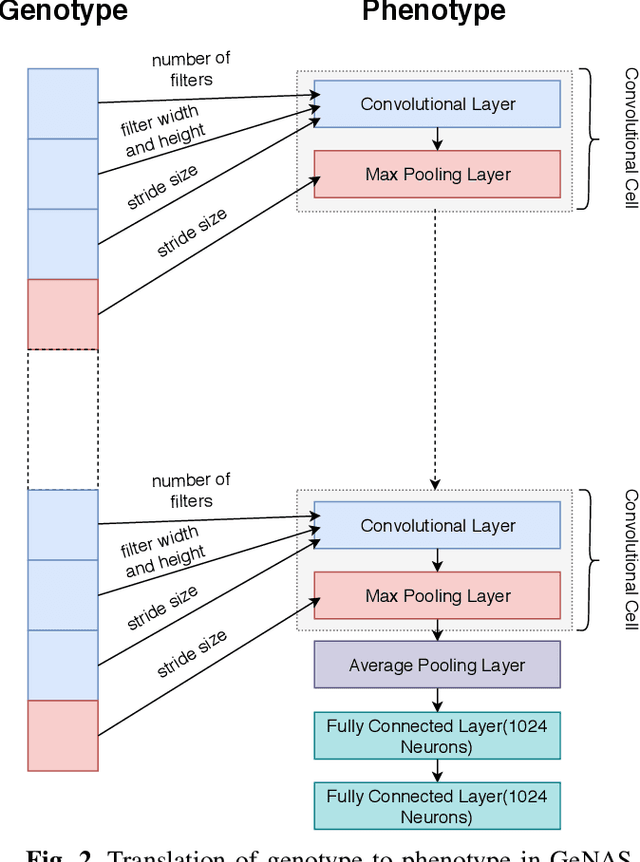
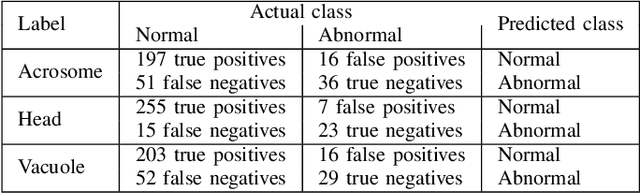
Male infertility is a disease which affects approximately 7% of men. Sperm morphology analysis (SMA) is one of the main diagnosis methods for this problem. Manual SMA is an inexact, subjective, non-reproducible, and hard to teach process. As a result, in this paper, we introduce a novel automatic SMA based on a neural architecture search algorithm termed Genetic Neural Architecture Search (GeNAS). For this purpose, we used a collection of images called MHSMA dataset contains 1,540 sperm images which have been collected from 235 patients with infertility problems. GeNAS is a genetic algorithm that acts as a meta-controller which explores the constrained search space of plain convolutional neural network architectures. Every individual of the genetic algorithm is a convolutional neural network trained to predict morphological deformities in different segments of human sperm (head, vacuole, and acrosome), and its fitness is calculated by a novel proposed method named GeNAS-WF especially designed for noisy, low resolution, and imbalanced datasets. Also, a hashing method is used to save each trained neural architecture fitness, so we could reuse them during fitness evaluation and speed up the algorithm. Besides, in terms of running time and computation power, our proposed architecture search method is far more efficient than most of the other existing neural architecture search algorithms. Additionally, other proposed methods have been evaluated on balanced datasets, whereas GeNAS is built specifically for noisy, low quality, and imbalanced datasets which are common in the field of medical imaging. In our experiments, the best neural architecture found by GeNAS has reached an accuracy of 92.66%, 77.33%, and 77.66% in the vacuole, head, and acrosome abnormality detection, respectively. In comparison to other proposed algorithms for MHSMA dataset, GeNAS achieved state-of-the-art results.