 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Language Models Know But Don't Say: Non-Generative Prior Extraction for Generalization
Jan 24, 2026In domains like medicine and finance, large-scale labeled data is costly and often unavailable, leading to models trained on small datasets that struggle to generalize to real-world populations. Large language models contain extensive knowledge from years of research across these domains. We propose LoID (Logit-Informed Distributions), a deterministic method for extracting informative prior distributions for Bayesian logistic regression by directly accessing their token-level predictions. Rather than relying on generated text, we probe the model's confidence in opposing semantic directions (positive vs. negative impact) through carefully constructed sentences. By measuring how consistently the LLM favors one direction across diverse phrasings, we extract the strength and reliability of the model's belief about each feature's influence. We evaluate LoID on ten real-world tabular datasets under synthetic out-of-distribution (OOD) settings characterized by covariate shift, where the training data represents only a subset of the population. We compare our approach against (1) standard uninformative priors, (2) AutoElicit, a recent method that prompts LLMs to generate priors via text completions, (3) LLMProcesses, a method that uses LLMs to generate numerical predictions through in-context learning and (4) an oracle-style upper bound derived from fitting logistic regression on the full dataset. We assess performance using Area Under the Curve (AUC). Across datasets, LoID significantly improves performance over logistic regression trained on OOD data, recovering up to \textbf{59\%} of the performance gap relative to the oracle model. LoID outperforms AutoElicit and LLMProcessesc on 8 out of 10 datasets, while providing a reproducible and computationally efficient mechanism for integrating LLM knowledge into Bayesian inference.
How Reliable are Confidence Estimators for Large Reasoning Models? A Systematic Benchmark on High-Stakes Domains
Jan 13, 2026The miscalibration of Large Reasoning Models (LRMs) undermines their reliability in high-stakes domains, necessitating methods to accurately estimate the confidence of their long-form, multi-step outputs. To address this gap, we introduce the Reasoning Model Confidence estimation Benchmark (RMCB), a public resource of 347,496 reasoning traces from six popular LRMs across different architectural families. The benchmark is constructed from a diverse suite of datasets spanning high-stakes domains, including clinical, financial, legal, and mathematical reasoning, alongside complex general reasoning benchmarks, with correctness annotations provided for all samples. Using RMCB, we conduct a large-scale empirical evaluation of over ten distinct representation-based methods, spanning sequential, graph-based, and text-based architectures. Our central finding is a persistent trade-off between discrimination (AUROC) and calibration (ECE): text-based encoders achieve the best AUROC (0.672), while structurally-aware models yield the best ECE (0.148), with no single method dominating both. Furthermore, we find that increased architectural complexity does not reliably outperform simpler sequential baselines, suggesting a performance ceiling for methods relying solely on chunk-level hidden states. This work provides the most comprehensive benchmark for this task to date, establishing rigorous baselines and demonstrating the limitations of current representation-based paradigms.
Extracting Overlapping Microservices from Monolithic Code via Deep Semantic Embeddings and Graph Neural Network-Based Soft Clustering
Aug 10, 2025Modern software systems are increasingly shifting from monolithic architectures to microservices to enhance scalability, maintainability, and deployment flexibility. Existing microservice extraction methods typically rely on hard clustering, assigning each software component to a single microservice. This approach often increases inter-service coupling and reduces intra-service cohesion. We propose Mo2oM (Monolithic to Overlapping Microservices), a framework that formulates microservice extraction as a soft clustering problem, allowing components to belong probabilistically to multiple microservices. This approach is inspired by expert-driven decompositions, where practitioners intentionally replicate certain software components across services to reduce communication overhead. Mo2oM combines deep semantic embeddings with structural dependencies extracted from methodcall graphs to capture both functional and architectural relationships. A graph neural network-based soft clustering algorithm then generates the final set of microservices. We evaluate Mo2oM on four open-source monolithic benchmarks and compare it against eight state-of-the-art baselines. Our results demonstrate that Mo2oM achieves improvements of up to 40.97% in structural modularity (balancing cohesion and coupling), 58% in inter-service call percentage (communication overhead), 26.16% in interface number (modularity and decoupling), and 38.96% in non-extreme distribution (service size balance) across all benchmarks.
Calibrating LLM Confidence by Probing Perturbed Representation Stability
May 27, 2025Miscalibration in Large Language Models (LLMs) undermines their reliability, highlighting the need for accurate confidence estimation. We introduce CCPS (Calibrating LLM Confidence by Probing Perturbed Representation Stability), a novel method analyzing internal representational stability in LLMs. CCPS applies targeted adversarial perturbations to final hidden states, extracts features reflecting the model's response to these perturbations, and uses a lightweight classifier to predict answer correctness. CCPS was evaluated on LLMs from 8B to 32B parameters (covering Llama, Qwen, and Mistral architectures) using MMLU and MMLU-Pro benchmarks in both multiple-choice and open-ended formats. Our results show that CCPS significantly outperforms current approaches. Across four LLMs and three MMLU variants, CCPS reduces Expected Calibration Error by approximately 55% and Brier score by 21%, while increasing accuracy by 5 percentage points, Area Under the Precision-Recall Curve by 4 percentage points, and Area Under the Receiver Operating Characteristic Curve by 6 percentage points, all relative to the strongest prior method. CCPS delivers an efficient, broadly applicable, and more accurate solution for estimating LLM confidence, thereby improving their trustworthiness.
MoENAS: Mixture-of-Expert based Neural Architecture Search for jointly Accurate, Fair, and Robust Edge Deep Neural Networks
Feb 11, 2025



There has been a surge in optimizing edge Deep Neural Networks (DNNs) for accuracy and efficiency using traditional optimization techniques such as pruning, and more recently, employing automatic design methodologies. However, the focus of these design techniques has often overlooked critical metrics such as fairness, robustness, and generalization. As a result, when evaluating SOTA edge DNNs' performance in image classification using the FACET dataset, we found that they exhibit significant accuracy disparities (14.09%) across 10 different skin tones, alongside issues of non-robustness and poor generalizability. In response to these observations, we introduce Mixture-of-Experts-based Neural Architecture Search (MoENAS), an automatic design technique that navigates through a space of mixture of experts to discover accurate, fair, robust, and general edge DNNs. MoENAS improves the accuracy by 4.02% compared to SOTA edge DNNs and reduces the skin tone accuracy disparities from 14.09% to 5.60%, while enhancing robustness by 3.80% and minimizing overfitting to 0.21%, all while keeping model size close to state-of-the-art models average size (+0.4M). With these improvements, MoENAS establishes a new benchmark for edge DNN design, paving the way for the development of more inclusive and robust edge DNNs.
Online Continual Learning: A Systematic Literature Review of Approaches, Challenges, and Benchmarks
Jan 09, 2025



Online Continual Learning (OCL) is a critical area in machine learning, focusing on enabling models to adapt to evolving data streams in real-time while addressing challenges such as catastrophic forgetting and the stability-plasticity trade-off. This study conducts the first comprehensive Systematic Literature Review (SLR) on OCL, analyzing 81 approaches, extracting over 1,000 features (specific tasks addressed by these approaches), and identifying more than 500 components (sub-models within approaches, including algorithms and tools). We also review 83 datasets spanning applications like image classification, object detection, and multimodal vision-language tasks. Our findings highlight key challenges, including reducing computational overhead, developing domain-agnostic solutions, and improving scalability in resource-constrained environments. Furthermore, we identify promising directions for future research, such as leveraging self-supervised learning for multimodal and sequential data, designing adaptive memory mechanisms that integrate sparse retrieval and generative replay, and creating efficient frameworks for real-world applications with noisy or evolving task boundaries. By providing a rigorous and structured synthesis of the current state of OCL, this review offers a valuable resource for advancing this field and addressing its critical challenges and opportunities. The complete SLR methodology steps and extracted data are publicly available through the provided link: https://github.com/kiyan-rezaee/ Systematic-Literature-Review-on-Online-Continual-Learning
GLoG-CSUnet: Enhancing Vision Transformers with Adaptable Radiomic Features for Medical Image Segmentation
Jan 08, 2025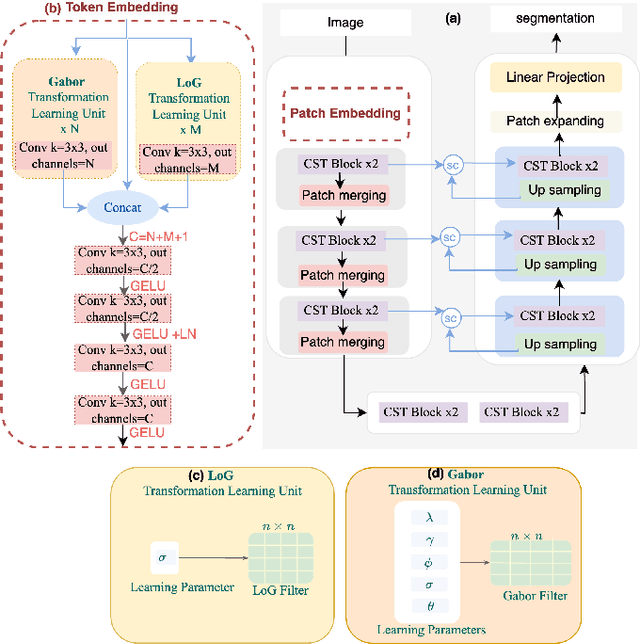
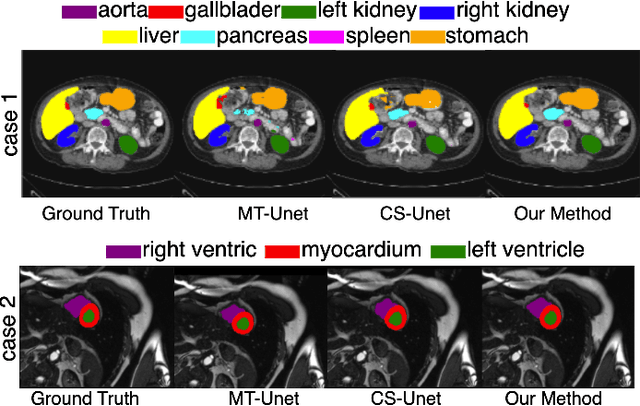
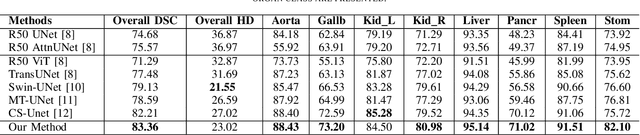
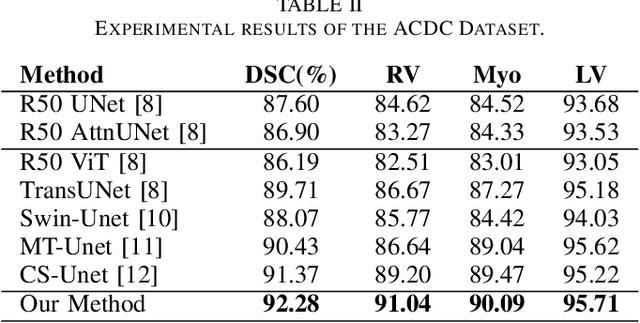
Vision Transformers (ViTs) have shown promise in medical image semantic segmentation (MISS) by capturing long-range correlations. However, ViTs often struggle to model local spatial information effectively, which is essential for accurately segmenting fine anatomical details, particularly when applied to small datasets without extensive pre-training. We introduce Gabor and Laplacian of Gaussian Convolutional Swin Network (GLoG-CSUnet), a novel architecture enhancing Transformer-based models by incorporating learnable radiomic features. This approach integrates dynamically adaptive Gabor and Laplacian of Gaussian (LoG) filters to capture texture, edge, and boundary information, enhancing the feature representation processed by the Transformer model. Our method uniquely combines the long-range dependency modeling of Transformers with the texture analysis capabilities of Gabor and LoG features. Evaluated on the Synapse multi-organ and ACDC cardiac segmentation datasets, GLoG-CSUnet demonstrates significant improvements over state-of-the-art models, achieving a 1.14% increase in Dice score for Synapse and 0.99% for ACDC, with minimal computational overhead (only 15 and 30 additional parameters, respectively). GLoG-CSUnet's flexible design allows integration with various base models, offering a promising approach for incorporating radiomics-inspired feature extraction in Transformer architectures for medical image analysis. The code implementation is available on GitHub at: https://github.com/HAAIL/GLoG-CSUnet.
Hybrid Student-Teacher Large Language Model Refinement for Cancer Toxicity Symptom Extraction
Aug 08, 2024


Large Language Models (LLMs) offer significant potential for clinical symptom extraction, but their deployment in healthcare settings is constrained by privacy concerns, computational limitations, and operational costs. This study investigates the optimization of compact LLMs for cancer toxicity symptom extraction using a novel iterative refinement approach. We employ a student-teacher architecture, utilizing Zephyr-7b-beta and Phi3-mini-128 as student models and GPT-4o as the teacher, to dynamically select between prompt refinement, Retrieval-Augmented Generation (RAG), and fine-tuning strategies. Our experiments on 294 clinical notes covering 12 post-radiotherapy toxicity symptoms demonstrate the effectiveness of this approach. The RAG method proved most efficient, improving average accuracy scores from 0.32 to 0.73 for Zephyr-7b-beta and from 0.40 to 0.87 for Phi3-mini-128 during refinement. In the test set, both models showed an approximate 0.20 increase in accuracy across symptoms. Notably, this improvement was achieved at a cost 45 times lower than GPT-4o for Zephyr and 79 times lower for Phi-3. These results highlight the potential of iterative refinement techniques in enhancing the capabilities of compact LLMs for clinical applications, offering a balance between performance, cost-effectiveness, and privacy preservation in healthcare settings.
An LSTM Feature Imitation Network for Hand Movement Recognition from sEMG Signals
May 23, 2024
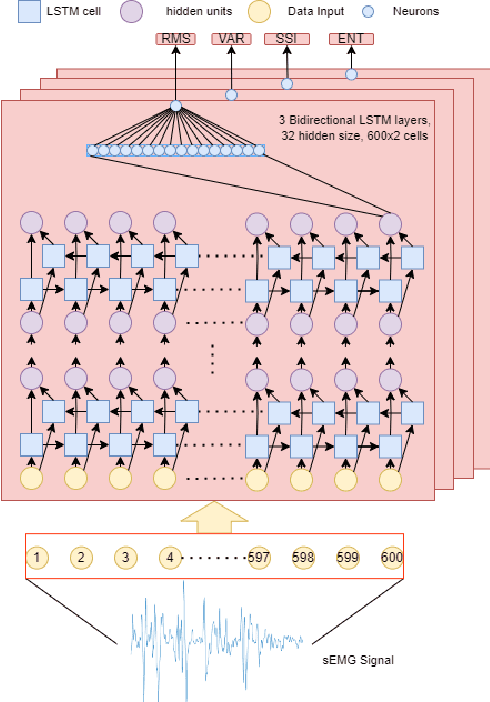
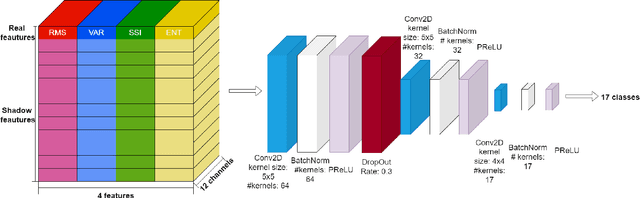
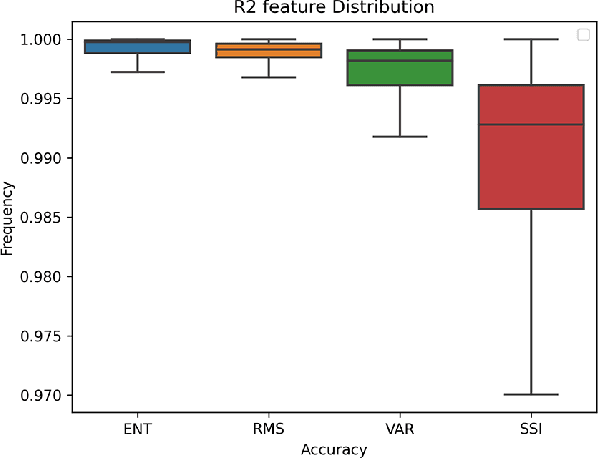
Surface Electromyography (sEMG) is a non-invasive signal that is used in the recognition of hand movement patterns, the diagnosis of diseases, and the robust control of prostheses. Despite the remarkable success of recent end-to-end Deep Learning approaches, they are still limited by the need for large amounts of labeled data. To alleviate the requirement for big data, researchers utilize Feature Engineering, which involves decomposing the sEMG signal into several spatial, temporal, and frequency features. In this paper, we propose utilizing a feature-imitating network (FIN) for closed-form temporal feature learning over a 300ms signal window on Ninapro DB2, and applying it to the task of 17 hand movement recognition. We implement a lightweight LSTM-FIN network to imitate four standard temporal features (entropy, root mean square, variance, simple square integral). We then explore transfer learning capabilities by applying the pre-trained LSTM-FIN for tuning to a downstream hand movement recognition task. We observed that the LSTM network can achieve up to 99\% R2 accuracy in feature reconstruction and 80\% accuracy in hand movement recognition. Our results also showed that the model can be robustly applied for both within- and cross-subject movement recognition, as well as simulated low-latency environments. Overall, our work demonstrates the potential of the FIN modeling paradigm in data-scarce scenarios for sEMG signal processing.
Iterative Prompt Refinement for Radiation Oncology Symptom Extraction Using Teacher-Student Large Language Models
Feb 06, 2024This study introduces a novel teacher-student architecture utilizing Large Language Models (LLMs) to improve prostate cancer radiotherapy symptom extraction from clinical notes. Mixtral, the student model, initially extracts symptoms, followed by GPT-4, the teacher model, which refines prompts based on Mixtral's performance. This iterative process involved 294 single symptom clinical notes across 12 symptoms, with up to 16 rounds of refinement per epoch. Results showed significant improvements in extracting symptoms from both single and multi-symptom notes. For 59 single symptom notes, accuracy increased from 0.51 to 0.71, precision from 0.52 to 0.82, recall from 0.52 to 0.72, and F1 score from 0.49 to 0.73. In 375 multi-symptom notes, accuracy rose from 0.24 to 0.43, precision from 0.6 to 0.76, recall from 0.24 to 0.43, and F1 score from 0.20 to 0.44. These results demonstrate the effectiveness of advanced prompt engineering in LLMs for radiation oncology use.