 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Reliable are Confidence Estimators for Large Reasoning Models? A Systematic Benchmark on High-Stakes Domains
Jan 13, 2026The miscalibration of Large Reasoning Models (LRMs) undermines their reliability in high-stakes domains, necessitating methods to accurately estimate the confidence of their long-form, multi-step outputs. To address this gap, we introduce the Reasoning Model Confidence estimation Benchmark (RMCB), a public resource of 347,496 reasoning traces from six popular LRMs across different architectural families. The benchmark is constructed from a diverse suite of datasets spanning high-stakes domains, including clinical, financial, legal, and mathematical reasoning, alongside complex general reasoning benchmarks, with correctness annotations provided for all samples. Using RMCB, we conduct a large-scale empirical evaluation of over ten distinct representation-based methods, spanning sequential, graph-based, and text-based architectures. Our central finding is a persistent trade-off between discrimination (AUROC) and calibration (ECE): text-based encoders achieve the best AUROC (0.672), while structurally-aware models yield the best ECE (0.148), with no single method dominating both. Furthermore, we find that increased architectural complexity does not reliably outperform simpler sequential baselines, suggesting a performance ceiling for methods relying solely on chunk-level hidden states. This work provides the most comprehensive benchmark for this task to date, establishing rigorous baselines and demonstrating the limitations of current representation-based paradigms.
Calibrating LLM Confidence by Probing Perturbed Representation Stability
May 27, 2025Miscalibration in Large Language Models (LLMs) undermines their reliability, highlighting the need for accurate confidence estimation. We introduce CCPS (Calibrating LLM Confidence by Probing Perturbed Representation Stability), a novel method analyzing internal representational stability in LLMs. CCPS applies targeted adversarial perturbations to final hidden states, extracts features reflecting the model's response to these perturbations, and uses a lightweight classifier to predict answer correctness. CCPS was evaluated on LLMs from 8B to 32B parameters (covering Llama, Qwen, and Mistral architectures) using MMLU and MMLU-Pro benchmarks in both multiple-choice and open-ended formats. Our results show that CCPS significantly outperforms current approaches. Across four LLMs and three MMLU variants, CCPS reduces Expected Calibration Error by approximately 55% and Brier score by 21%, while increasing accuracy by 5 percentage points, Area Under the Precision-Recall Curve by 4 percentage points, and Area Under the Receiver Operating Characteristic Curve by 6 percentage points, all relative to the strongest prior method. CCPS delivers an efficient, broadly applicable, and more accurate solution for estimating LLM confidence, thereby improving their trustworthiness.
Hybrid Student-Teacher Large Language Model Refinement for Cancer Toxicity Symptom Extraction
Aug 08, 2024


Large Language Models (LLMs) offer significant potential for clinical symptom extraction, but their deployment in healthcare settings is constrained by privacy concerns, computational limitations, and operational costs. This study investigates the optimization of compact LLMs for cancer toxicity symptom extraction using a novel iterative refinement approach. We employ a student-teacher architecture, utilizing Zephyr-7b-beta and Phi3-mini-128 as student models and GPT-4o as the teacher, to dynamically select between prompt refinement, Retrieval-Augmented Generation (RAG), and fine-tuning strategies. Our experiments on 294 clinical notes covering 12 post-radiotherapy toxicity symptoms demonstrate the effectiveness of this approach. The RAG method proved most efficient, improving average accuracy scores from 0.32 to 0.73 for Zephyr-7b-beta and from 0.40 to 0.87 for Phi3-mini-128 during refinement. In the test set, both models showed an approximate 0.20 increase in accuracy across symptoms. Notably, this improvement was achieved at a cost 45 times lower than GPT-4o for Zephyr and 79 times lower for Phi-3. These results highlight the potential of iterative refinement techniques in enhancing the capabilities of compact LLMs for clinical applications, offering a balance between performance, cost-effectiveness, and privacy preservation in healthcare settings.
Iterative Prompt Refinement for Radiation Oncology Symptom Extraction Using Teacher-Student Large Language Models
Feb 06, 2024This study introduces a novel teacher-student architecture utilizing Large Language Models (LLMs) to improve prostate cancer radiotherapy symptom extraction from clinical notes. Mixtral, the student model, initially extracts symptoms, followed by GPT-4, the teacher model, which refines prompts based on Mixtral's performance. This iterative process involved 294 single symptom clinical notes across 12 symptoms, with up to 16 rounds of refinement per epoch. Results showed significant improvements in extracting symptoms from both single and multi-symptom notes. For 59 single symptom notes, accuracy increased from 0.51 to 0.71, precision from 0.52 to 0.82, recall from 0.52 to 0.72, and F1 score from 0.49 to 0.73. In 375 multi-symptom notes, accuracy rose from 0.24 to 0.43, precision from 0.6 to 0.76, recall from 0.24 to 0.43, and F1 score from 0.20 to 0.44. These results demonstrate the effectiveness of advanced prompt engineering in LLMs for radiation oncology use.
An Introduction to Natural Language Processing Techniques and Framework for Clinical Implementation in Radiation Oncology
Nov 08, 2023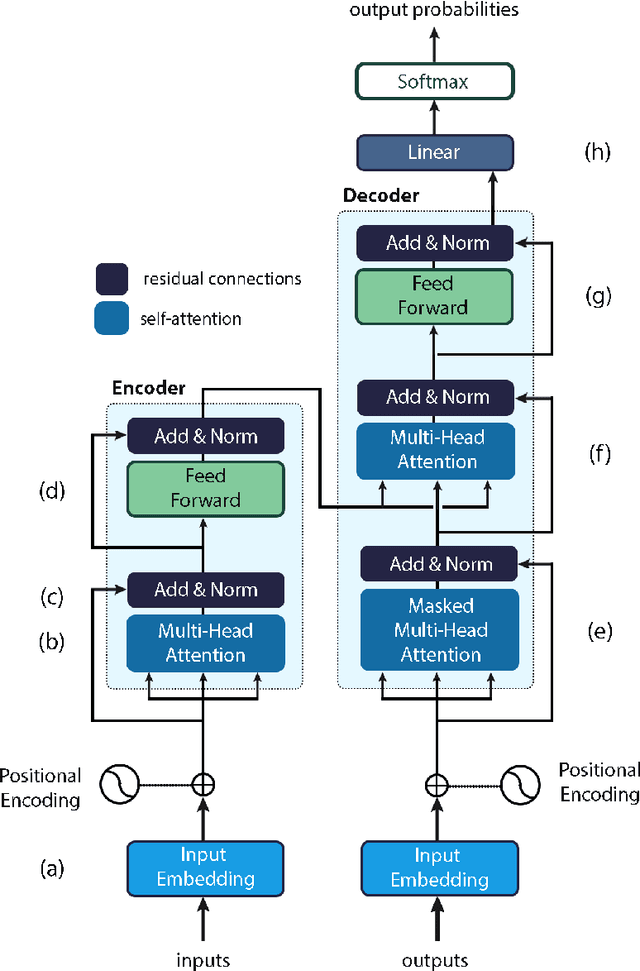

Natural Language Processing (NLP) is a key technique for developing Medical Artificial Intelligence (AI) systems that leverage Electronic Health Record (EHR) data to build diagnostic and prognostic models. NLP enables the conversion of unstructured clinical text into structured data that can be fed into AI algorithms. The emergence of the transformer architecture and large language models (LLMs) has led to remarkable advances in NLP for various healthcare tasks, such as entity recognition, relation extraction, sentence similarity, text summarization, and question answering. In this article, we review the major technical innovations that underpin modern NLP models and present state-of-the-art NLP applications that employ LLMs in radiation oncology research. However, these LLMs are prone to many errors such as hallucinations, biases, and ethical violations, which necessitate rigorous evaluation and validation before clinical deployment. As such, we propose a comprehensive framework for assessing the NLP models based on their purpose and clinical fit, technical performance, bias and trust, legal and ethical implications, and quality assurance, prior to implementation in clinical radiation oncology. Our article aims to provide guidance and insights for researchers and clinicians who are interested in developing and using NLP models in clinical radiation oncology.
The Broad Impact of Feature Imitation: Neural Enhancements Across Financial, Speech, and Physiological Domains
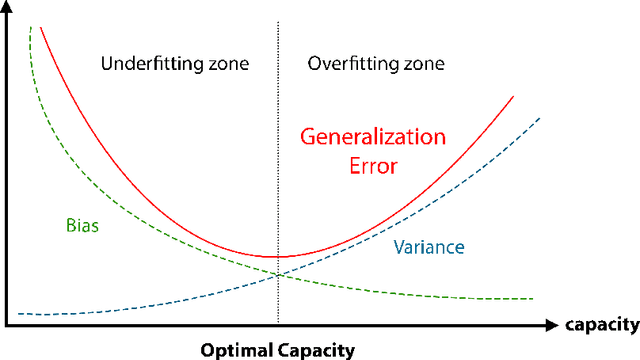
Sep 21, 2023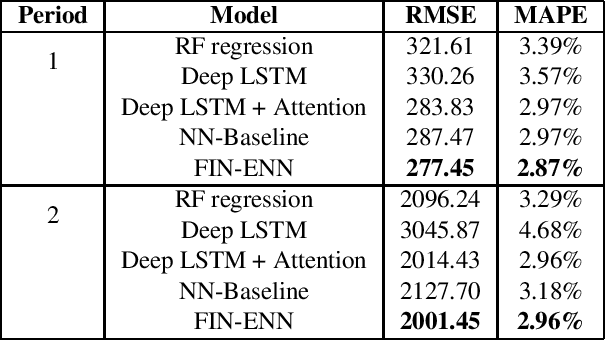

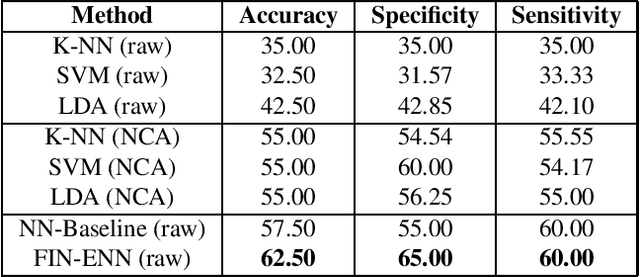
Initialization of neural network weights plays a pivotal role in determining their performance. Feature Imitating Networks (FINs) offer a novel strategy by initializing weights to approximate specific closed-form statistical features, setting a promising foundation for deep learning architectures. While the applicability of FINs has been chiefly tested in biomedical domains, this study extends its exploration into other time series datasets. Three different experiments are conducted in this study to test the applicability of imitating Tsallis entropy for performance enhancement: Bitcoin price prediction, speech emotion recognition, and chronic neck pain detection. For the Bitcoin price prediction, models embedded with FINs reduced the root mean square error by around 1000 compared to the baseline. In the speech emotion recognition task, the FIN-augmented model increased classification accuracy by over 3 percent. Lastly, in the CNP detection experiment, an improvement of about 7 percent was observed compared to established classifiers. These findings validate the broad utility and potency of FINs in diverse applications.
MambaNet: A Hybrid Neural Network for Predicting the NBA Playoffs
Oct 31, 2022



In this paper, we present Mambanet: a hybrid neural network for predicting the outcomes of Basketball games. Contrary to other studies, which focus primarily on season games, this study investigates playoff games. MambaNet is a hybrid neural network architecture that processes a time series of teams' and players' game statistics and generates the probability of a team winning or losing an NBA playoff match. In our approach, we utilize Feature Imitating Networks to provide latent signal-processing feature representations of game statistics to further process with convolutional, recurrent, and dense neural layers. Three experiments using six different datasets are conducted to evaluate the performance and generalizability of our architecture against a wide range of previous studies. Our final method successfully predicted the AUC from 0.72 to 0.82, beating the best-performing baseline models by a considerable margin.
Fetal Gender Identification using Machine and Deep Learning Algorithms on Phonocardiogram Signals
Oct 10, 2021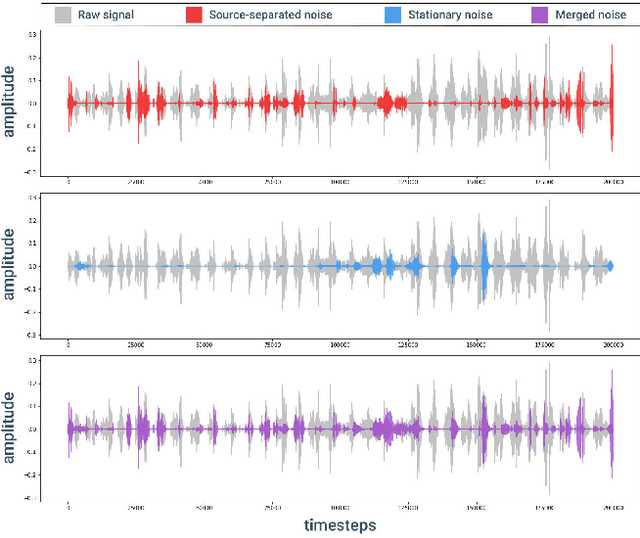


Phonocardiogram (PCG) signal analysis is a critical, widely-studied technology to noninvasively analyze the heart's mechanical activity. Through evaluating heart sounds, this technology has been chiefly leveraged as a preliminary solution to automatically diagnose Cardiovascular diseases among adults; however, prenatal tasks such as fetal gender identification have been relatively less studied using fetal Phonocardiography (FPCG). In this work, we apply common PCG signal processing techniques on the gender-tagged Shiraz University Fetal Heart Sounds Database and study the applicability of previously proposed features in classifying fetal gender using both Machine Learning and Deep Learning models. Even though PCG data acquisition's cost-effectiveness and feasibility make it a convenient method of Fetal Heart Rate (FHR) monitoring, the contaminated nature of PCG signals with the noise of various types makes it a challenging modality. To address this problem, we experimented with both static and adaptive noise reduction techniques such as Low-pass filtering, Denoising Autoencoders, and Source Separators. We apply a wide range of previously proposed classifiers to our dataset and propose a novel ensemble method of Fetal Gender Identification (FGI). Our method substantially outperformed the baseline and reached up to 91% accuracy in classifying fetal gender of unseen subjects.
Prose2Poem: The Blessing of Transformers in Translating Prose to Persian Poetry
Oct 01, 2021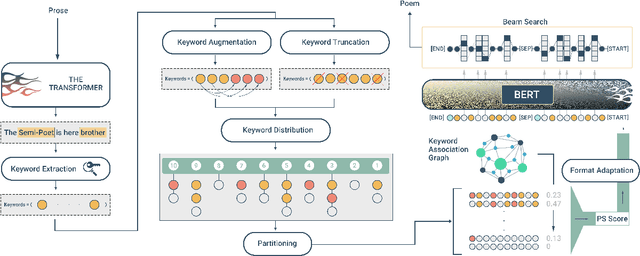

Persian Poetry has consistently expressed its philosophy, wisdom, speech, and rationale on the basis of its couplets, making it an enigmatic language on its own to both native and non-native speakers. Nevertheless, the notice able gap between Persian prose and poem has left the two pieces of literature medium-less. Having curated a parallel corpus of prose and their equivalent poems, we introduce a novel Neural Machine Translation (NMT) approach to translate prose to ancient Persian poetry using transformer-based Language Models in an extremely low-resource setting. More specifically, we trained a Transformer model from scratch to obtain initial translations and pretrained different variations of BERT to obtain final translations. To address the challenge of using masked language modelling under poeticness criteria, we heuristically joined the two models and generated valid poems in terms of automatic and human assessments. Final results demonstrate the eligibility and creativity of our novel heuristically aided approach among Literature professionals and non-professionals in generating novel Persian poems.
COPER: a Query-adaptable Semantics-based Search Engine for Persian COVID-19 Articles
Jul 14, 2021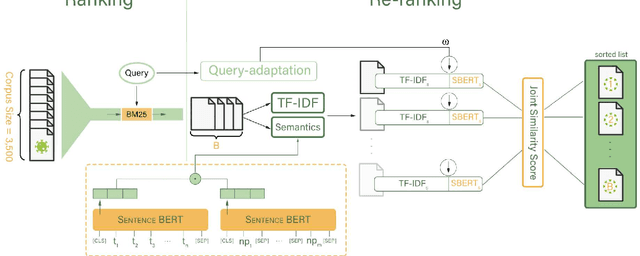
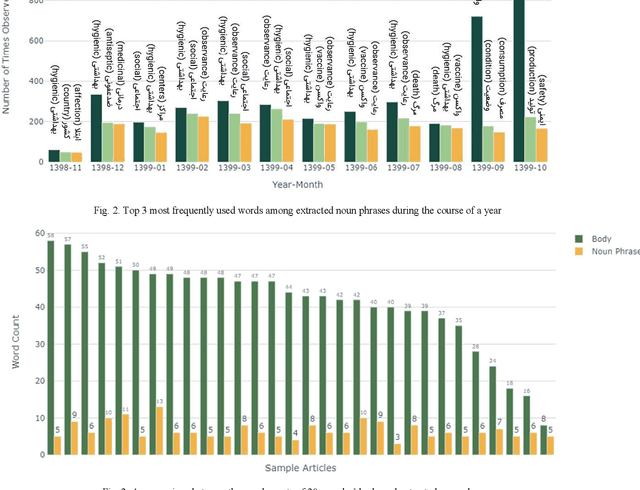
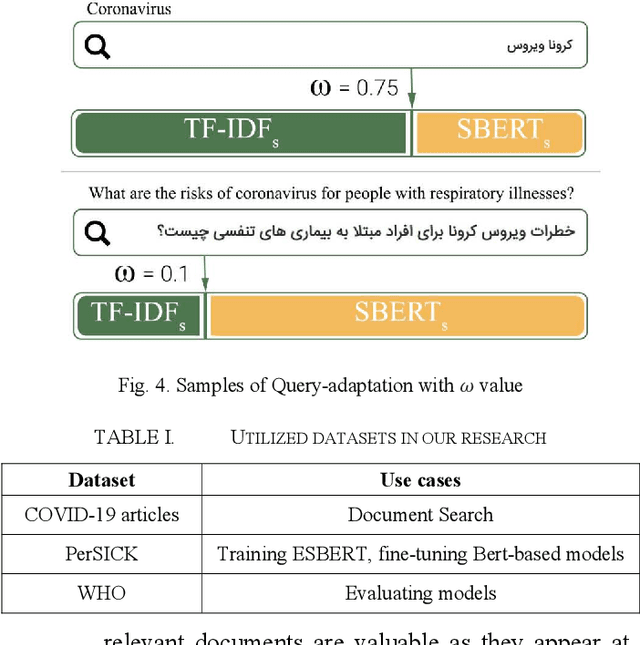
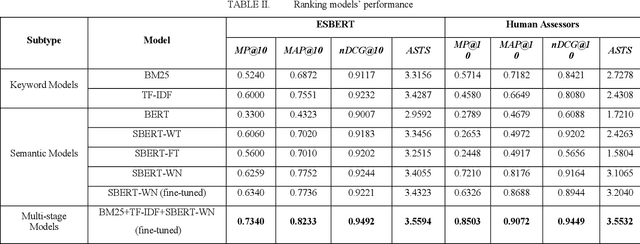
With the surge of pretrained language models, a new pathway has been opened to incorporate Persian text contextual information. Meanwhile, as many other countries, including Iran, are fighting against COVID-19, a plethora of COVID-19 related articles has been published in Iranian Healthcare magazines to better inform the public of the situation. However, finding answers in this sheer volume of information is an extremely difficult task. In this paper, we collected a large dataset of these articles, leveraged different BERT variations as well as other keyword models such as BM25 and TF-IDF, and created a search engine to sift through these documents and rank them, given a user's query. Our final search engine consists of a ranker and a re-ranker, which adapts itself to the query. We fine-tune our models using Semantic Textual Similarity and evaluate them with standard task metrics. Our final method outperforms the rest by a considerable margin.