 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOPER: a Query-adaptable Semantics-based Search Engine for Persian COVID-19 Articles
Paper and Code
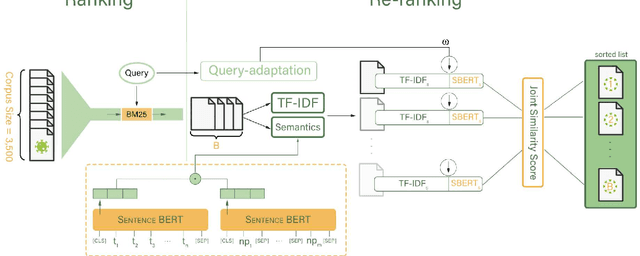
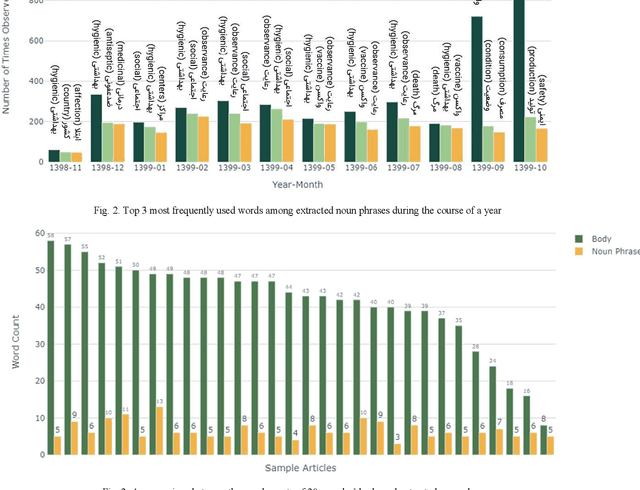
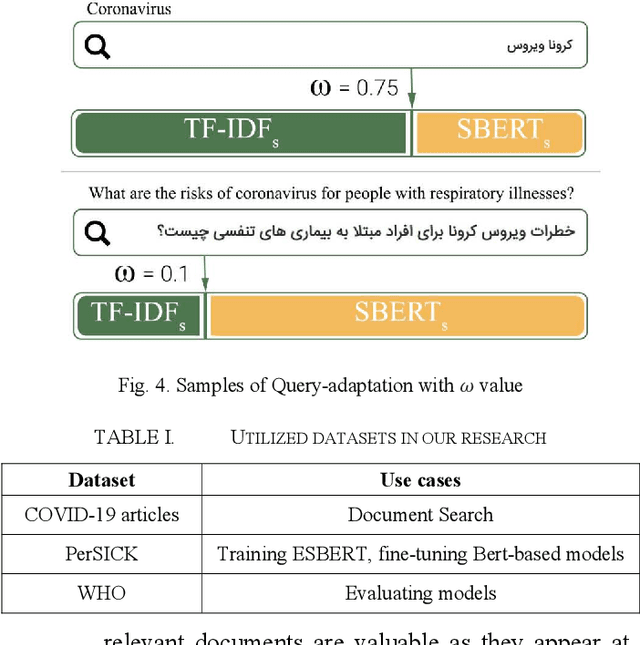
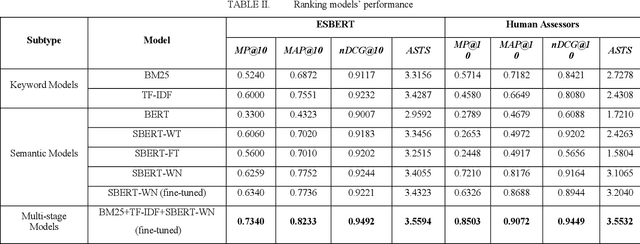
With the surge of pretrained language models, a new pathway has been opened to incorporate Persian text contextual information. Meanwhile, as many other countries, including Iran, are fighting against COVID-19, a plethora of COVID-19 related articles has been published in Iranian Healthcare magazines to better inform the public of the situation. However, finding answers in this sheer volume of information is an extremely difficult task. In this paper, we collected a large dataset of these articles, leveraged different BERT variations as well as other keyword models such as BM25 and TF-IDF, and created a search engine to sift through these documents and rank them, given a user's query. Our final search engine consists of a ranker and a re-ranker, which adapts itself to the query. We fine-tune our models using Semantic Textual Similarity and evaluate them with standard task metrics. Our final method outperforms the rest by a considerable margin.