 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting ML Training under Fully Homomorphic Encryption: Convergence Guarantees, Differential Privacy, and Efficient Algorithms
May 27, 2026We present the first theoretical convergence analysis of machine learning training under fully homomorphic encryption (FHE), combined with a differentially private (DP) training algorithm tailored to encrypted computation. Our approach improves computational efficiency over standard differentially private gradient descent (DP-GD) while achieving comparable utility. In particular, we prove convergence of approximate gradient descent using polynomial approximations of activation and loss functions, which are required for FHE compatibility. To preserve privacy in downstream tasks, we integrate differential privacy without relying on costly per-sample gradient clipping, enabling scalable encrypted learning. We also provide data-independent hyperparameter selection and theoretically grounded strategies for polynomial approximation which can be of independent interest. Together, these contributions advance the feasibility of efficient, private, and secure machine learning on sensitive data.
Grounded or Guessing? LVLM Confidence Estimation via Blind-Image Contrastive Ranking
May 11, 2026Large vision-language models suffer from visual ungroundedness: they can produce a fluent, confident, and even correct response driven entirely by language priors, with the image contributing nothing to the prediction. Existing confidence estimation methods cannot detect this, as they observe model behavior under normal inference with no mechanism to determine whether a prediction was shaped by the image or by text alone. We introduce BICR (Blind-Image Contrastive Ranking), a model-agnostic confidence estimation framework that makes this contrast explicit during training by extracting hidden states from a frozen LVLM twice: once with the real image-question pair, and once with the image blacked out while the question is held fixed. A lightweight probe is trained on the real-image hidden state and regularized by a ranking loss that penalizes higher confidence on the blacked-out view, teaching it to treat visual grounding as a signal of reliability at zero additional inference cost. Evaluated across five modern LVLMs and seven baselines on a benchmark covering visual question answering, object hallucination detection, medical imaging, and financial document understanding, BICR achieves the best cross-LVLM average on both calibration and discrimination simultaneously, with statistically significant discrimination gains robust to cluster-aware analysis at 4-18x fewer parameters than the strongest probing baseline.
The Unseen Threat: Residual Knowledge in Machine Unlearning under Perturbed Samples
Jan 29, 2026Machine unlearning offers a practical alternative to avoid full model re-training by approximately removing the influence of specific user data. While existing methods certify unlearning via statistical indistinguishability from re-trained models, these guarantees do not naturally extend to model outputs when inputs are adversarially perturbed. In particular, slight perturbations of forget samples may still be correctly recognized by the unlearned model - even when a re-trained model fails to do so - revealing a novel privacy risk: information about the forget samples may persist in their local neighborhood. In this work, we formalize this vulnerability as residual knowledge and show that it is inevitable in high-dimensional settings. To mitigate this risk, we propose a fine-tuning strategy, named RURK, that penalizes the model's ability to re-recognize perturbed forget samples. Experiments on vision benchmarks with deep neural networks demonstrate that residual knowledge is prevalent across existing unlearning methods and that our approach effectively prevents residual knowledge.
How Reliable are Confidence Estimators for Large Reasoning Models? A Systematic Benchmark on High-Stakes Domains
Jan 13, 2026The miscalibration of Large Reasoning Models (LRMs) undermines their reliability in high-stakes domains, necessitating methods to accurately estimate the confidence of their long-form, multi-step outputs. To address this gap, we introduce the Reasoning Model Confidence estimation Benchmark (RMCB), a public resource of 347,496 reasoning traces from six popular LRMs across different architectural families. The benchmark is constructed from a diverse suite of datasets spanning high-stakes domains, including clinical, financial, legal, and mathematical reasoning, alongside complex general reasoning benchmarks, with correctness annotations provided for all samples. Using RMCB, we conduct a large-scale empirical evaluation of over ten distinct representation-based methods, spanning sequential, graph-based, and text-based architectures. Our central finding is a persistent trade-off between discrimination (AUROC) and calibration (ECE): text-based encoders achieve the best AUROC (0.672), while structurally-aware models yield the best ECE (0.148), with no single method dominating both. Furthermore, we find that increased architectural complexity does not reliably outperform simpler sequential baselines, suggesting a performance ceiling for methods relying solely on chunk-level hidden states. This work provides the most comprehensive benchmark for this task to date, establishing rigorous baselines and demonstrating the limitations of current representation-based paradigms.
Calibrating LLM Confidence by Probing Perturbed Representation Stability
May 27, 2025Miscalibration in Large Language Models (LLMs) undermines their reliability, highlighting the need for accurate confidence estimation. We introduce CCPS (Calibrating LLM Confidence by Probing Perturbed Representation Stability), a novel method analyzing internal representational stability in LLMs. CCPS applies targeted adversarial perturbations to final hidden states, extracts features reflecting the model's response to these perturbations, and uses a lightweight classifier to predict answer correctness. CCPS was evaluated on LLMs from 8B to 32B parameters (covering Llama, Qwen, and Mistral architectures) using MMLU and MMLU-Pro benchmarks in both multiple-choice and open-ended formats. Our results show that CCPS significantly outperforms current approaches. Across four LLMs and three MMLU variants, CCPS reduces Expected Calibration Error by approximately 55% and Brier score by 21%, while increasing accuracy by 5 percentage points, Area Under the Precision-Recall Curve by 4 percentage points, and Area Under the Receiver Operating Characteristic Curve by 6 percentage points, all relative to the strongest prior method. CCPS delivers an efficient, broadly applicable, and more accurate solution for estimating LLM confidence, thereby improving their trustworthiness.
MAFE: Multi-Agent Fair Environments for Decision-Making Systems
Feb 25, 2025Fairness constraints applied to machine learning (ML) models in static contexts have been shown to potentially produce adverse outcomes among demographic groups over time. To address this issue, emerging research focuses on creating fair solutions that persist over time. While many approaches treat this as a single-agent decision-making problem, real-world systems often consist of multiple interacting entities that influence outcomes. Explicitly modeling these entities as agents enables more flexible analysis of their interventions and the effects they have on a system's underlying dynamics. A significant challenge in conducting research on multi-agent systems is the lack of realistic environments that leverage the limited real-world data available for analysis. To address this gap, we introduce the concept of a Multi-Agent Fair Environment (MAFE) and present and analyze three MAFEs that model distinct social systems. Experimental results demonstrate the utility of our MAFEs as testbeds for developing multi-agent fair algorithms.
Interpretable LLM-based Table Question Answering
Dec 16, 2024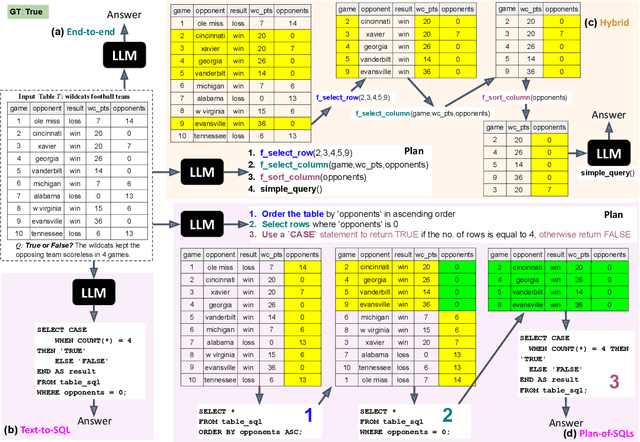

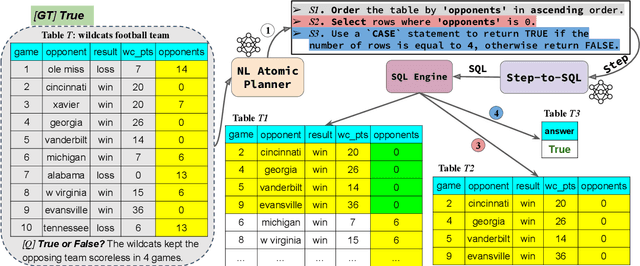
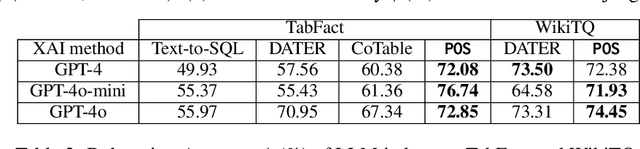
Interpretability for Table Question Answering (Table QA) is critical, particularly in high-stakes industries like finance or healthcare. Although recent approaches using Large Language Models (LLMs) have significantly improved Table QA performance, their explanations for how the answers are generated are ambiguous. To fill this gap, we introduce Plan-of-SQLs ( or POS), an interpretable, effective, and efficient approach to Table QA that answers an input query solely with SQL executions. Through qualitative and quantitative evaluations with human and LLM judges, we show that POS is most preferred among explanation methods, helps human users understand model decision boundaries, and facilitates model success and error identification. Furthermore, when evaluated in standard benchmarks (TabFact, WikiTQ, and FetaQA), POS achieves competitive or superior accuracy compared to existing methods, while maintaining greater efficiency by requiring significantly fewer LLM calls and database queries.
Cross-Domain Graph Data Scaling: A Showcase with Diffusion Models
Jun 04, 2024Models for natural language and images benefit from data scaling behavior: the more data fed into the model, the better they perform. This 'better with more' phenomenon enables the effectiveness of large-scale pre-training on vast amounts of data. However, current graph pre-training methods struggle to scale up data due to heterogeneity across graphs. To achieve effective data scaling, we aim to develop a general model that is able to capture diverse data patterns of graphs and can be utilized to adaptively help the downstream tasks. To this end, we propose UniAug, a universal graph structure augmentor built on a diffusion model. We first pre-train a discrete diffusion model on thousands of graphs across domains to learn the graph structural patterns. In the downstream phase, we provide adaptive enhancement by conducting graph structure augmentation with the help of the pre-trained diffusion model via guided generation. By leveraging the pre-trained diffusion model for structure augmentation, we consistently achieve performance improvements across various downstream tasks in a plug-and-play manner. To the best of our knowledge, this study represents the first demonstration of a data-scaling graph structure augmentor on graphs across domains.
BuDDIE: A Business Document Dataset for Multi-task Information Extraction
Apr 05, 2024The field of visually rich document understanding (VRDU) aims to solve a multitude of well-researched NLP tasks in a multi-modal domain. Several datasets exist for research on specific tasks of VRDU such as document classification (DC), key entity extraction (KEE), entity linking, visual question answering (VQA), inter alia. These datasets cover documents like invoices and receipts with sparse annotations such that they support one or two co-related tasks (e.g., entity extraction and entity linking). Unfortunately, only focusing on a single specific of documents or task is not representative of how documents often need to be processed in the wild - where variety in style and requirements is expected. In this paper, we introduce BuDDIE (Business Document Dataset for Information Extraction), the first multi-task dataset of 1,665 real-world business documents that contains rich and dense annotations for DC, KEE, and VQA. Our dataset consists of publicly available business entity documents from US state government websites. The documents are structured and vary in their style and layout across states and types (e.g., forms, certificates, reports, etc.). We provide data variety and quality metrics for BuDDIE as well as a series of baselines for each task. Our baselines cover traditional textual, multi-modal, and large language model approaches to VRDU.
Balancing Fairness and Accuracy in Data-Restricted Binary Classification
Mar 12, 2024Applications that deal with sensitive information may have restrictions placed on the data available to a machine learning (ML) classifier. For example, in some applications, a classifier may not have direct access to sensitive attributes, affecting its ability to produce accurate and fair decisions. This paper proposes a framework that models the trade-off between accuracy and fairness under four practical scenarios that dictate the type of data available for analysis. Prior works examine this trade-off by analyzing the outputs of a scoring function that has been trained to implicitly learn the underlying distribution of the feature vector, class label, and sensitive attribute of a dataset. In contrast, our framework directly analyzes the behavior of the optimal Bayesian classifier on this underlying distribution by constructing a discrete approximation it from the dataset itself. This approach enables us to formulate multiple convex optimization problems, which allow us to answer the question: How is the accuracy of a Bayesian classifier affected in different data restricting scenarios when constrained to be fair? Analysis is performed on a set of fairness definitions that include group and individual fairness. Experiments on three datasets demonstrate the utility of the proposed framework as a tool for quantifying the trade-offs among different fairness notions and their distributional dependencies.