 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Apples to Oranges: Learning Similarity Functions for Data Produced by Different Distributions
Paper and Code
Aug 26, 2022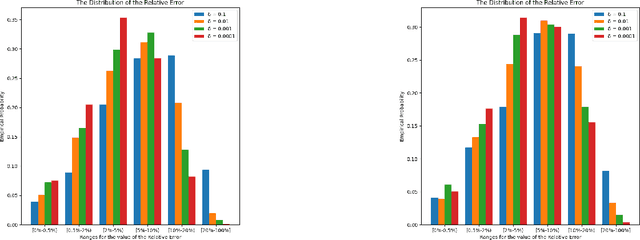
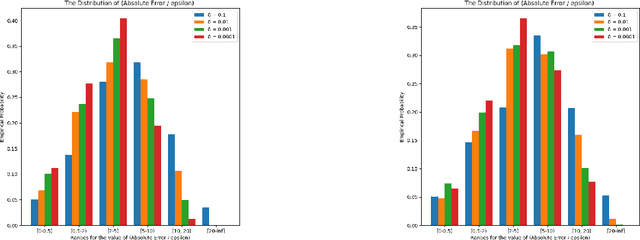
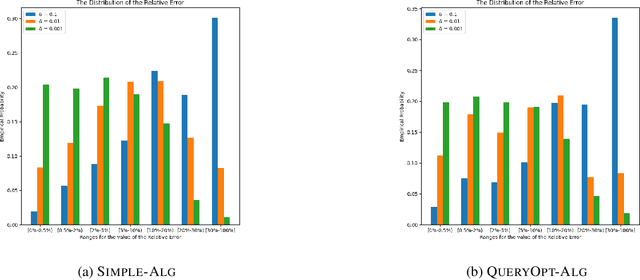
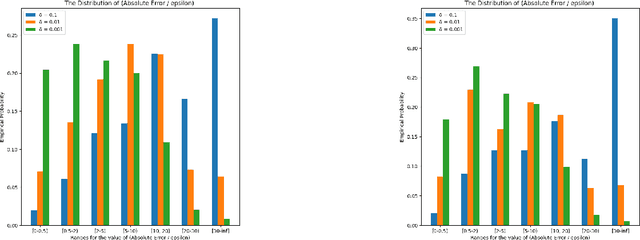
Similarity functions measure how comparable pairs of elements are, and play a key role in a wide variety of applications, e.g., Clustering problems and considerations of Individual Fairness. However, access to an accurate similarity function should not always be considered guaranteed. Specifically, when the elements to be compared are produced by different distributions, or in other words belong to different ``demographic'' groups, knowledge of their true similarity might be very difficult to obtain. In this work, we present a sampling framework that learns these across-groups similarity functions, using only a limited amount of experts' feedback. We show analytical results with rigorous bounds, and empirically validate our algorithms via a large suite of experiments.