 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting ML Training under Fully Homomorphic Encryption: Convergence Guarantees, Differential Privacy, and Efficient Algorithms
May 27, 2026We present the first theoretical convergence analysis of machine learning training under fully homomorphic encryption (FHE), combined with a differentially private (DP) training algorithm tailored to encrypted computation. Our approach improves computational efficiency over standard differentially private gradient descent (DP-GD) while achieving comparable utility. In particular, we prove convergence of approximate gradient descent using polynomial approximations of activation and loss functions, which are required for FHE compatibility. To preserve privacy in downstream tasks, we integrate differential privacy without relying on costly per-sample gradient clipping, enabling scalable encrypted learning. We also provide data-independent hyperparameter selection and theoretically grounded strategies for polynomial approximation which can be of independent interest. Together, these contributions advance the feasibility of efficient, private, and secure machine learning on sensitive data.
MAFE: Multi-Agent Fair Environments for Decision-Making Systems
Feb 25, 2025Fairness constraints applied to machine learning (ML) models in static contexts have been shown to potentially produce adverse outcomes among demographic groups over time. To address this issue, emerging research focuses on creating fair solutions that persist over time. While many approaches treat this as a single-agent decision-making problem, real-world systems often consist of multiple interacting entities that influence outcomes. Explicitly modeling these entities as agents enables more flexible analysis of their interventions and the effects they have on a system's underlying dynamics. A significant challenge in conducting research on multi-agent systems is the lack of realistic environments that leverage the limited real-world data available for analysis. To address this gap, we introduce the concept of a Multi-Agent Fair Environment (MAFE) and present and analyze three MAFEs that model distinct social systems. Experimental results demonstrate the utility of our MAFEs as testbeds for developing multi-agent fair algorithms.
Balancing Fairness and Accuracy in Data-Restricted Binary Classification
Mar 12, 2024Applications that deal with sensitive information may have restrictions placed on the data available to a machine learning (ML) classifier. For example, in some applications, a classifier may not have direct access to sensitive attributes, affecting its ability to produce accurate and fair decisions. This paper proposes a framework that models the trade-off between accuracy and fairness under four practical scenarios that dictate the type of data available for analysis. Prior works examine this trade-off by analyzing the outputs of a scoring function that has been trained to implicitly learn the underlying distribution of the feature vector, class label, and sensitive attribute of a dataset. In contrast, our framework directly analyzes the behavior of the optimal Bayesian classifier on this underlying distribution by constructing a discrete approximation it from the dataset itself. This approach enables us to formulate multiple convex optimization problems, which allow us to answer the question: How is the accuracy of a Bayesian classifier affected in different data restricting scenarios when constrained to be fair? Analysis is performed on a set of fairness definitions that include group and individual fairness. Experiments on three datasets demonstrate the utility of the proposed framework as a tool for quantifying the trade-offs among different fairness notions and their distributional dependencies.
Bounding the Excess Risk for Linear Models Trained on Marginal-Preserving, Differentially-Private, Synthetic Data
Feb 06, 2024The growing use of machine learning (ML) has raised concerns that an ML model may reveal private information about an individual who has contributed to the training dataset. To prevent leakage of sensitive data, we consider using differentially-private (DP), synthetic training data instead of real training data to train an ML model. A key desirable property of synthetic data is its ability to preserve the low-order marginals of the original distribution. Our main contribution comprises novel upper and lower bounds on the excess empirical risk of linear models trained on such synthetic data, for continuous and Lipschitz loss functions. We perform extensive experimentation alongside our theoretical results.
A Canonical Data Transformation for Achieving Inter- and Within-group Fairness
Oct 23, 2023



Increases in the deployment of machine learning algorithms for applications that deal with sensitive data have brought attention to the issue of fairness in machine learning. Many works have been devoted to applications that require different demographic groups to be treated fairly. However, algorithms that aim to satisfy inter-group fairness (also called group fairness) may inadvertently treat individuals within the same demographic group unfairly. To address this issue, we introduce a formal definition of within-group fairness that maintains fairness among individuals from within the same group. We propose a pre-processing framework to meet both inter- and within-group fairness criteria with little compromise in accuracy. The framework maps the feature vectors of members from different groups to an inter-group-fair canonical domain before feeding them into a scoring function. The mapping is constructed to preserve the relative relationship between the scores obtained from the unprocessed feature vectors of individuals from the same demographic group, guaranteeing within-group fairness. We apply this framework to the COMPAS risk assessment and Law School datasets and compare its performance in achieving inter-group and within-group fairness to two regularization-based methods.
Transparency Tools for Fairness in AI (Luskin)
Jul 09, 2020
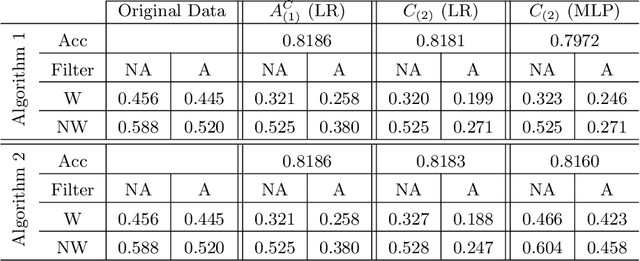
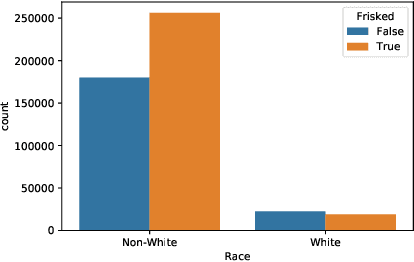
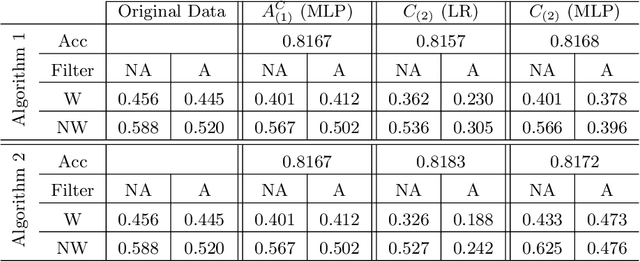
We propose new tools for policy-makers to use when assessing and correcting fairness and bias in AI algorithms. The three tools are: - A new definition of fairness called "controlled fairness" with respect to choices of protected features and filters. The definition provides a simple test of fairness of an algorithm with respect to a dataset. This notion of fairness is suitable in cases where fairness is prioritized over accuracy, such as in cases where there is no "ground truth" data, only data labeled with past decisions (which may have been biased). - Algorithms for retraining a given classifier to achieve "controlled fairness" with respect to a choice of features and filters. Two algorithms are presented, implemented and tested. These algorithms require training two different models in two stages. We experiment with combinations of various types of models for the first and second stage and report on which combinations perform best in terms of fairness and accuracy. - Algorithms for adjusting model parameters to achieve a notion of fairness called "classification parity". This notion of fairness is suitable in cases where accuracy is prioritized. Two algorithms are presented, one which assumes that protected features are accessible to the model during testing, and one which assumes protected features are not accessible during testing. We evaluate our tools on three different publicly available datasets. We find that the tools are useful for understanding various dimensions of bias, and that in practice the algorithms are effective in starkly reducing a given observed bias when tested on new data.
How to 0wn NAS in Your Spare Time
Feb 17, 2020


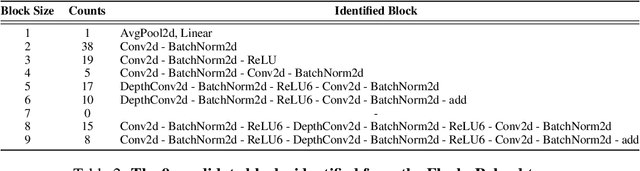
New data processing pipelines and novel network architectures increasingly drive the success of deep learning. In consequence, the industry considers top-performing architectures as intellectual property and devotes considerable computational resources to discovering such architectures through neural architecture search (NAS). This provides an incentive for adversaries to steal these novel architectures; when used in the cloud, to provide Machine Learning as a Service, the adversaries also have an opportunity to reconstruct the architectures by exploiting a range of hardware side channels. However, it is challenging to reconstruct novel architectures and pipelines without knowing the computational graph (e.g., the layers, branches or skip connections), the architectural parameters (e.g., the number of filters in a convolutional layer) or the specific pre-processing steps (e.g. embeddings). In this paper, we design an algorithm that reconstructs the key components of a novel deep learning system by exploiting a small amount of information leakage from a cache side-channel attack, Flush+Reload. We use Flush+Reload to infer the trace of computations and the timing for each computation. Our algorithm then generates candidate computational graphs from the trace and eliminates incompatible candidates through a parameter estimation process. We implement our algorithm in PyTorch and Tensorflow. We demonstrate experimentally that we can reconstruct MalConv, a novel data pre-processing pipeline for malware detection, and ProxylessNAS- CPU, a novel network architecture for the ImageNet classification optimized to run on CPUs, without knowing the architecture family. In both cases, we achieve 0% error. These results suggest hardware side channels are a practical attack vector against MLaaS, and more efforts should be devoted to understanding their impact on the security of deep learning systems.
Security Analysis of Deep Neural Networks Operating in the Presence of Cache Side-Channel Attacks
Oct 08, 2018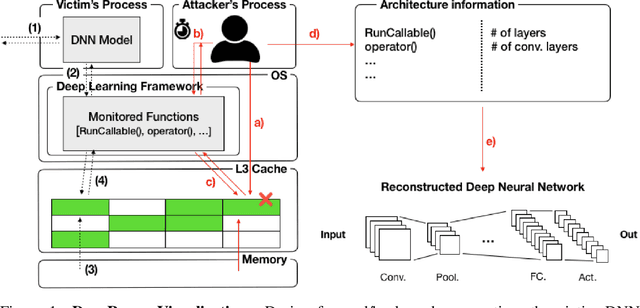
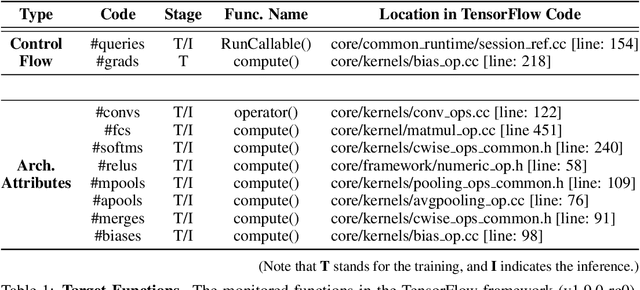
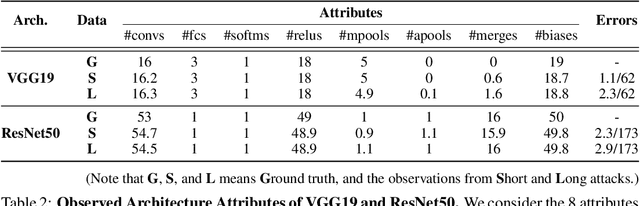
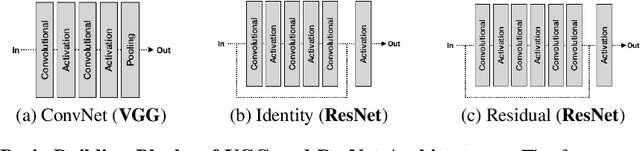
Recent work has introduced attacks that extract the architecture information of deep neural networks (DNN), as this knowledge enhances an adversary's capability to conduct black-box attacks against the model. This paper presents the first in-depth security analysis of DNN fingerprinting attacks that exploit cache side-channels. First, we define the threat model for these attacks: our adversary does not need the ability to query the victim model; instead, she runs a co-located process on the host machine victim's deep learning (DL) system is running and passively monitors the accesses of the target functions in the shared framework. Second, we introduce DeepRecon, an attack that reconstructs the architecture of the victim network by using the internal information extracted via Flush+Reload, a cache side-channel technique. Once the attacker observes function invocations that map directly to architecture attributes of the victim network, the attacker can reconstruct the victim's entire network architecture. In our evaluation, we demonstrate that an attacker can accurately reconstruct two complex networks (VGG19 and ResNet50) having observed only one forward propagation. Based on the extracted architecture attributes, we also demonstrate that an attacker can build a meta-model that accurately fingerprints the architecture and family of the pre-trained model in a transfer learning setting. From this meta-model, we evaluate the importance of the observed attributes in the fingerprinting process. Third, we propose and evaluate new framework-level defense techniques that obfuscate our attacker's observations. Our empirical security analysis represents a step toward understanding the DNNs' vulnerability to cache side-channel attacks.
Approximate resilience, monotonicity, and the complexity of agnostic learning
Jul 09, 2014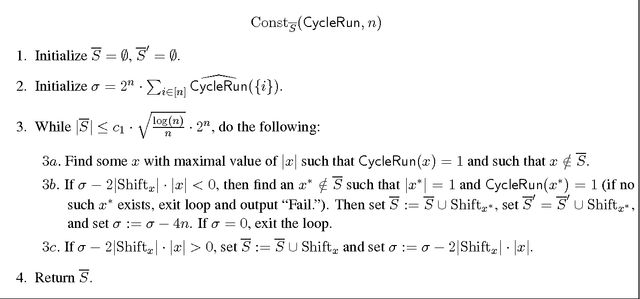
A function $f$ is $d$-resilient if all its Fourier coefficients of degree at most $d$ are zero, i.e., $f$ is uncorrelated with all low-degree parities. We study the notion of $\mathit{approximate}$ $\mathit{resilience}$ of Boolean functions, where we say that $f$ is $\alpha$-approximately $d$-resilient if $f$ is $\alpha$-close to a $[-1,1]$-valued $d$-resilient function in $\ell_1$ distance. We show that approximate resilience essentially characterizes the complexity of agnostic learning of a concept class $C$ over the uniform distribution. Roughly speaking, if all functions in a class $C$ are far from being $d$-resilient then $C$ can be learned agnostically in time $n^{O(d)}$ and conversely, if $C$ contains a function close to being $d$-resilient then agnostic learning of $C$ in the statistical query (SQ) framework of Kearns has complexity of at least $n^{\Omega(d)}$. This characterization is based on the duality between $\ell_1$ approximation by degree-$d$ polynomials and approximate $d$-resilience that we establish. In particular, it implies that $\ell_1$ approximation by low-degree polynomials, known to be sufficient for agnostic learning over product distributions, is in fact necessary. Focusing on monotone Boolean functions, we exhibit the existence of near-optimal $\alpha$-approximately $\widetilde{\Omega}(\alpha\sqrt{n})$-resilient monotone functions for all $\alpha>0$. Prior to our work, it was conceivable even that every monotone function is $\Omega(1)$-far from any $1$-resilient function. Furthermore, we construct simple, explicit monotone functions based on ${\sf Tribes}$ and ${\sf CycleRun}$ that are close to highly resilient functions. Our constructions are based on a fairly general resilience analysis and amplification. These structural results, together with the characterization, imply nearly optimal lower bounds for agnostic learning of monotone juntas.