 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQu-ANTI-zation: Exploiting Quantization Artifacts for Achieving Adversarial Outcomes
Nov 11, 2021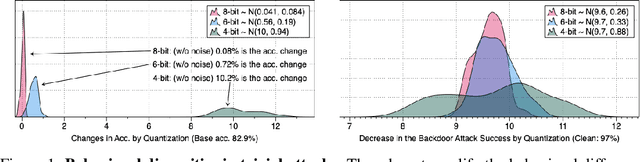
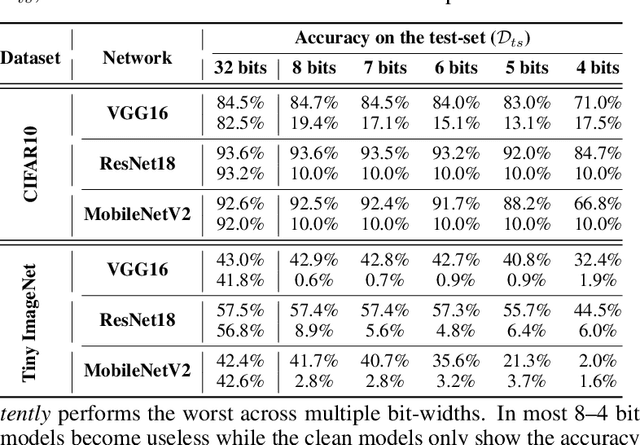
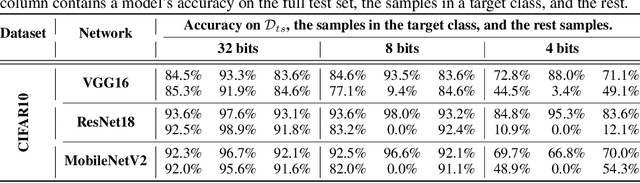
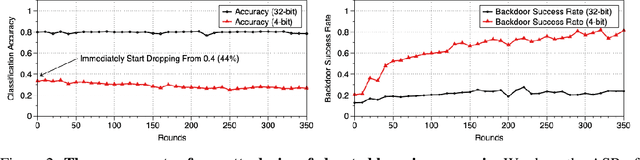
Quantization is a popular technique that $transforms$ the parameter representation of a neural network from floating-point numbers into lower-precision ones ($e.g.$, 8-bit integers). It reduces the memory footprint and the computational cost at inference, facilitating the deployment of resource-hungry models. However, the parameter perturbations caused by this transformation result in $behavioral$ $disparities$ between the model before and after quantization. For example, a quantized model can misclassify some test-time samples that are otherwise classified correctly. It is not known whether such differences lead to a new security vulnerability. We hypothesize that an adversary may control this disparity to introduce specific behaviors that activate upon quantization. To study this hypothesis, we weaponize quantization-aware training and propose a new training framework to implement adversarial quantization outcomes. Following this framework, we present three attacks we carry out with quantization: (i) an indiscriminate attack for significant accuracy loss; (ii) a targeted attack against specific samples; and (iii) a backdoor attack for controlling the model with an input trigger. We further show that a single compromised model defeats multiple quantization schemes, including robust quantization techniques. Moreover, in a federated learning scenario, we demonstrate that a set of malicious participants who conspire can inject our quantization-activated backdoor. Lastly, we discuss potential counter-measures and show that only re-training consistently removes the attack artifacts. Our code is available at https://github.com/Secure-AI-Systems-Group/Qu-ANTI-zation
A Panda? No, It's a Sloth: Slowdown Attacks on Adaptive Multi-Exit Neural Network Inference
Oct 06, 2020

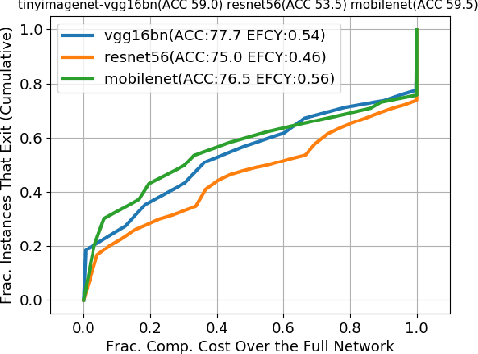
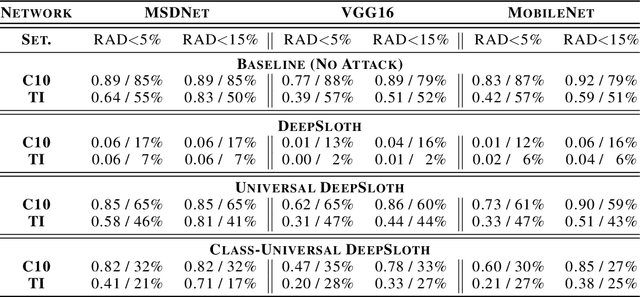
Recent increases in the computational demands of deep neural networks (DNNs), combined with the observation that most input samples require only simple models, have sparked interest in $input$-$adaptive$ multi-exit architectures, such as MSDNets or Shallow-Deep Networks. These architectures enable faster inferences and could bring DNNs to low-power devices, e.g. in the Internet of Things (IoT). However, it is unknown if the computational savings provided by this approach are robust against adversarial pressure. In particular, an adversary may aim to slow down adaptive DNNs by increasing their average inference time$-$a threat analogous to the $denial$-$of$-$service$ attacks from the Internet. In this paper, we conduct a systematic evaluation of this threat by experimenting with three generic multi-exit DNNs (based on VGG16, MobileNet, and ResNet56) and a custom multi-exit architecture, on two popular image classification benchmarks (CIFAR-10 and Tiny ImageNet). To this end, we show that adversarial sample-crafting techniques can be modified to cause slowdown, and we propose a metric for comparing their impact on different architectures. We show that a slowdown attack reduces the efficacy of multi-exit DNNs by 90%-100%, and it amplifies the latency by 1.5-5$\times$ in a typical IoT deployment. We also show that it is possible to craft universal, reusable perturbations and that the attack can be effective in realistic black-box scenarios, where the attacker has limited knowledge about the victim. Finally, we show that adversarial training provides limited protection against slowdowns. These results suggest that further research is needed for defending multi-exit architectures against this emerging threat.
On the Effectiveness of Mitigating Data Poisoning Attacks with Gradient Shaping
Feb 27, 2020
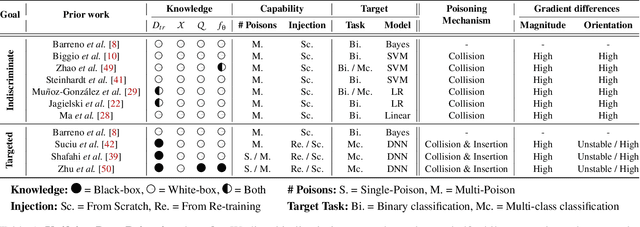

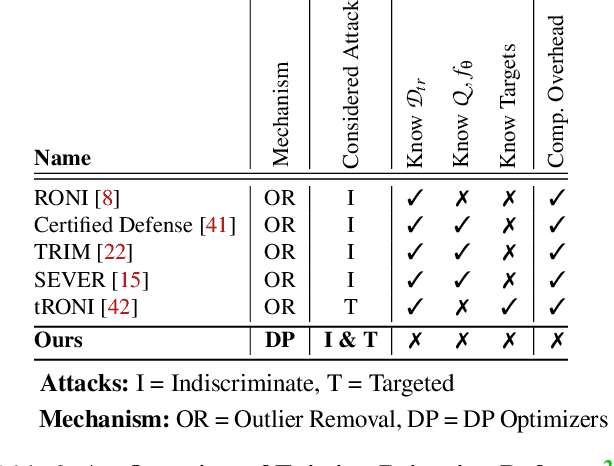
Machine learning algorithms are vulnerable to data poisoning attacks. Prior taxonomies that focus on specific scenarios, e.g., indiscriminate or targeted, have enabled defenses for the corresponding subset of known attacks. Yet, this introduces an inevitable arms race between adversaries and defenders. In this work, we study the feasibility of an attack-agnostic defense relying on artifacts that are common to all poisoning attacks. Specifically, we focus on a common element between all attacks: they modify gradients computed to train the model. We identify two main artifacts of gradients computed in the presence of poison: (1) their $\ell_2$ norms have significantly higher magnitudes than those of clean gradients, and (2) their orientation differs from clean gradients. Based on these observations, we propose the prerequisite for a generic poisoning defense: it must bound gradient magnitudes and minimize differences in orientation. We call this gradient shaping. As an exemplar tool to evaluate the feasibility of gradient shaping, we use differentially private stochastic gradient descent (DP-SGD), which clips and perturbs individual gradients during training to obtain privacy guarantees. We find that DP-SGD, even in configurations that do not result in meaningful privacy guarantees, increases the model's robustness to indiscriminate attacks. It also mitigates worst-case targeted attacks and increases the adversary's cost in multi-poison scenarios. The only attack we find DP-SGD to be ineffective against is a strong, yet unrealistic, indiscriminate attack. Our results suggest that, while we currently lack a generic poisoning defense, gradient shaping is a promising direction for future research.
How to 0wn NAS in Your Spare Time
Feb 17, 2020


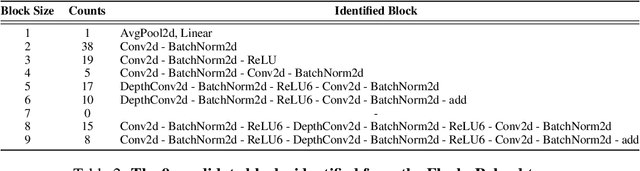
New data processing pipelines and novel network architectures increasingly drive the success of deep learning. In consequence, the industry considers top-performing architectures as intellectual property and devotes considerable computational resources to discovering such architectures through neural architecture search (NAS). This provides an incentive for adversaries to steal these novel architectures; when used in the cloud, to provide Machine Learning as a Service, the adversaries also have an opportunity to reconstruct the architectures by exploiting a range of hardware side channels. However, it is challenging to reconstruct novel architectures and pipelines without knowing the computational graph (e.g., the layers, branches or skip connections), the architectural parameters (e.g., the number of filters in a convolutional layer) or the specific pre-processing steps (e.g. embeddings). In this paper, we design an algorithm that reconstructs the key components of a novel deep learning system by exploiting a small amount of information leakage from a cache side-channel attack, Flush+Reload. We use Flush+Reload to infer the trace of computations and the timing for each computation. Our algorithm then generates candidate computational graphs from the trace and eliminates incompatible candidates through a parameter estimation process. We implement our algorithm in PyTorch and Tensorflow. We demonstrate experimentally that we can reconstruct MalConv, a novel data pre-processing pipeline for malware detection, and ProxylessNAS- CPU, a novel network architecture for the ImageNet classification optimized to run on CPUs, without knowing the architecture family. In both cases, we achieve 0% error. These results suggest hardware side channels are a practical attack vector against MLaaS, and more efforts should be devoted to understanding their impact on the security of deep learning systems.
Terminal Brain Damage: Exposing the Graceless Degradation in Deep Neural Networks Under Hardware Fault Attacks
Jun 03, 2019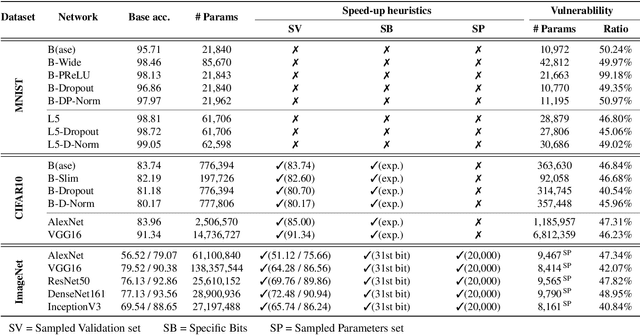
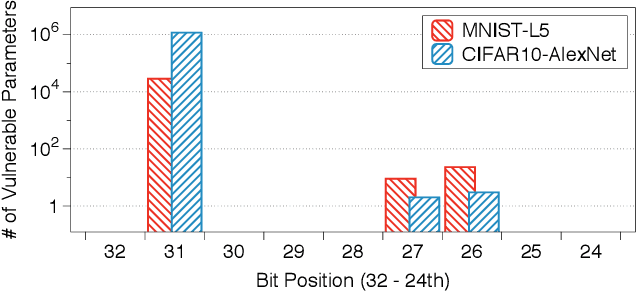
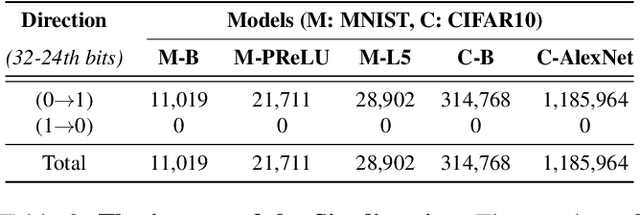
Deep neural networks (DNNs) have been shown to tolerate "brain damage": cumulative changes to the network's parameters (e.g., pruning, numerical perturbations) typically result in a graceful degradation of classification accuracy. However, the limits of this natural resilience are not well understood in the presence of small adversarial changes to the DNN parameters' underlying memory representation, such as bit-flips that may be induced by hardware fault attacks. We study the effects of bitwise corruptions on 19 DNN models---six architectures on three image classification tasks---and we show that most models have at least one parameter that, after a specific bit-flip in their bitwise representation, causes an accuracy loss of over 90%. We employ simple heuristics to efficiently identify the parameters likely to be vulnerable. We estimate that 40-50% of the parameters in a model might lead to an accuracy drop greater than 10% when individually subjected to such single-bit perturbations. To demonstrate how an adversary could take advantage of this vulnerability, we study the impact of an exemplary hardware fault attack, Rowhammer, on DNNs. Specifically, we show that a Rowhammer enabled attacker co-located in the same physical machine can inflict significant accuracy drops (up to 99%) even with single bit-flip corruptions and no knowledge of the model. Our results expose the limits of DNNs' resilience against parameter perturbations induced by real-world fault attacks. We conclude by discussing possible mitigations and future research directions towards fault attack-resilient DNNs.
Security Analysis of Deep Neural Networks Operating in the Presence of Cache Side-Channel Attacks
Oct 08, 2018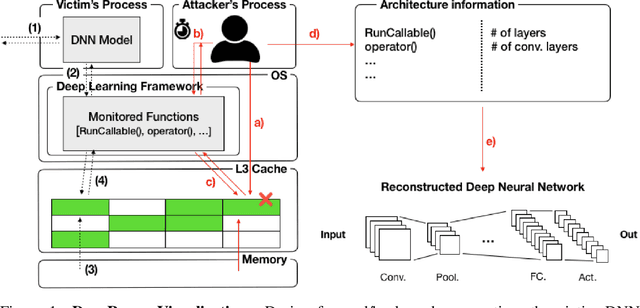
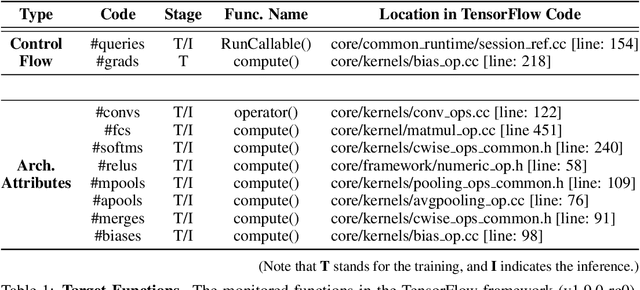
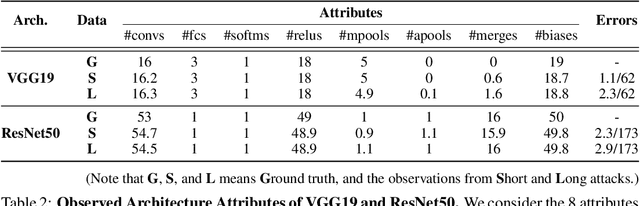
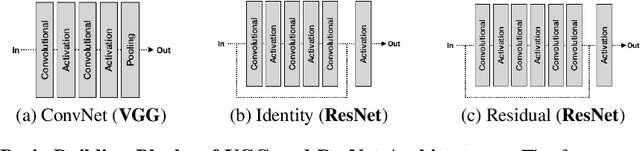
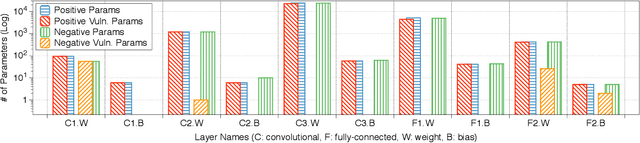
Recent work has introduced attacks that extract the architecture information of deep neural networks (DNN), as this knowledge enhances an adversary's capability to conduct black-box attacks against the model. This paper presents the first in-depth security analysis of DNN fingerprinting attacks that exploit cache side-channels. First, we define the threat model for these attacks: our adversary does not need the ability to query the victim model; instead, she runs a co-located process on the host machine victim's deep learning (DL) system is running and passively monitors the accesses of the target functions in the shared framework. Second, we introduce DeepRecon, an attack that reconstructs the architecture of the victim network by using the internal information extracted via Flush+Reload, a cache side-channel technique. Once the attacker observes function invocations that map directly to architecture attributes of the victim network, the attacker can reconstruct the victim's entire network architecture. In our evaluation, we demonstrate that an attacker can accurately reconstruct two complex networks (VGG19 and ResNet50) having observed only one forward propagation. Based on the extracted architecture attributes, we also demonstrate that an attacker can build a meta-model that accurately fingerprints the architecture and family of the pre-trained model in a transfer learning setting. From this meta-model, we evaluate the importance of the observed attributes in the fingerprinting process. Third, we propose and evaluate new framework-level defense techniques that obfuscate our attacker's observations. Our empirical security analysis represents a step toward understanding the DNNs' vulnerability to cache side-channel attacks.
When Does Machine Learning FAIL? Generalized Transferability for Evasion and Poisoning Attacks
Mar 19, 2018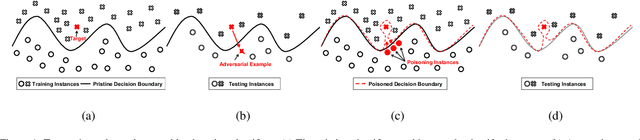
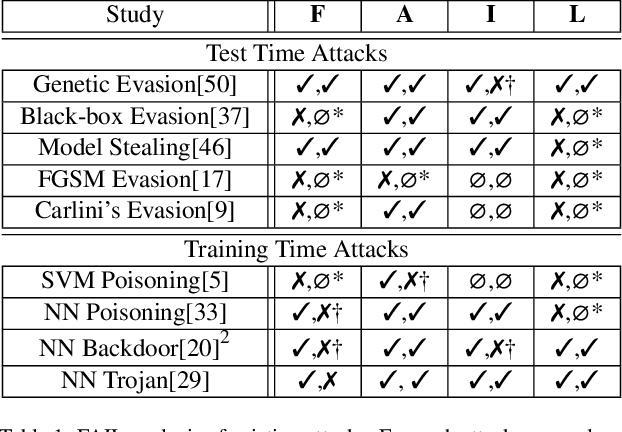


Attacks against machine learning systems represent a growing threat as highlighted by the abundance of attacks proposed lately. However, attacks often make unrealistic assumptions about the knowledge and capabilities of adversaries. To evaluate this threat systematically, we propose the FAIL attacker model, which describes the adversary's knowledge and control along four dimensions. The FAIL model allows us to consider a wide range of weaker adversaries that have limited control and incomplete knowledge of the features, learning algorithms and training instances utilized. Within this framework, we evaluate the generalized transferability of a known evasion attack and we design StingRay, a targeted poisoning attack that is broadly applicable---it is practical against 4 machine learning applications, which use 3 different learning algorithms, and it can bypass 2 existing defenses. Our evaluation provides deeper insights into the transferability of poison and evasion samples across models and suggests promising directions for investigating defenses against this threat.
Summoning Demons: The Pursuit of Exploitable Bugs in Machine Learning
Jan 17, 2017

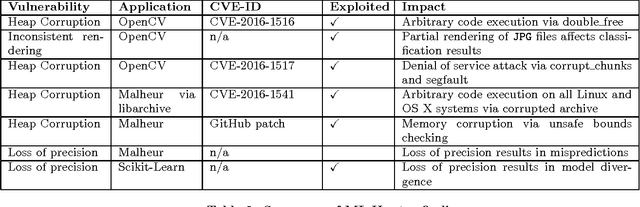

Governments and businesses increasingly rely on data analytics and machine learning (ML) for improving their competitive edge in areas such as consumer satisfaction, threat intelligence, decision making, and product efficiency. However, by cleverly corrupting a subset of data used as input to a target's ML algorithms, an adversary can perturb outcomes and compromise the effectiveness of ML technology. While prior work in the field of adversarial machine learning has studied the impact of input manipulation on correct ML algorithms, we consider the exploitation of bugs in ML implementations. In this paper, we characterize the attack surface of ML programs, and we show that malicious inputs exploiting implementation bugs enable strictly more powerful attacks than the classic adversarial machine learning techniques. We propose a semi-automated technique, called steered fuzzing, for exploring this attack surface and for discovering exploitable bugs in machine learning programs, in order to demonstrate the magnitude of this threat. As a result of our work, we responsibly disclosed five vulnerabilities, established three new CVE-IDs, and illuminated a common insecure practice across many machine learning systems. Finally, we outline several research directions for further understanding and mitigating this threat.