 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummoning Demons: The Pursuit of Exploitable Bugs in Machine Learning
Jan 17, 2017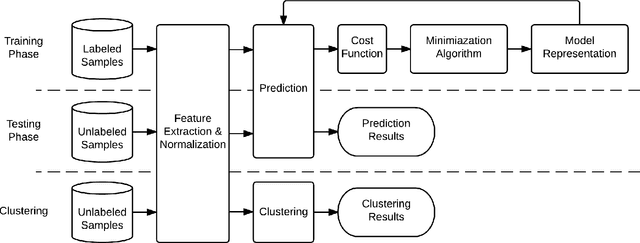

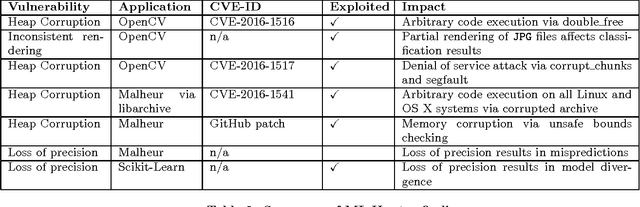

Governments and businesses increasingly rely on data analytics and machine learning (ML) for improving their competitive edge in areas such as consumer satisfaction, threat intelligence, decision making, and product efficiency. However, by cleverly corrupting a subset of data used as input to a target's ML algorithms, an adversary can perturb outcomes and compromise the effectiveness of ML technology. While prior work in the field of adversarial machine learning has studied the impact of input manipulation on correct ML algorithms, we consider the exploitation of bugs in ML implementations. In this paper, we characterize the attack surface of ML programs, and we show that malicious inputs exploiting implementation bugs enable strictly more powerful attacks than the classic adversarial machine learning techniques. We propose a semi-automated technique, called steered fuzzing, for exploring this attack surface and for discovering exploitable bugs in machine learning programs, in order to demonstrate the magnitude of this threat. As a result of our work, we responsibly disclosed five vulnerabilities, established three new CVE-IDs, and illuminated a common insecure practice across many machine learning systems. Finally, we outline several research directions for further understanding and mitigating this threat.