 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Reasoning in Ambiguous Contexts
Jun 13, 2025We study the ability of language models to reason about appropriate information disclosure - a central aspect of the evolving field of agentic privacy. Whereas previous works have focused on evaluating a model's ability to align with human decisions, we examine the role of ambiguity and missing context on model performance when making information-sharing decisions. We identify context ambiguity as a crucial barrier for high performance in privacy assessments. By designing Camber, a framework for context disambiguation, we show that model-generated decision rationales can reveal ambiguities and that systematically disambiguating context based on these rationales leads to significant accuracy improvements (up to 13.3\% in precision and up to 22.3\% in recall) as well as reductions in prompt sensitivity. Overall, our results indicate that approaches for context disambiguation are a promising way forward to enhance agentic privacy reasoning.
Exploring Adversarial Examples in Malware Detection
Oct 18, 2018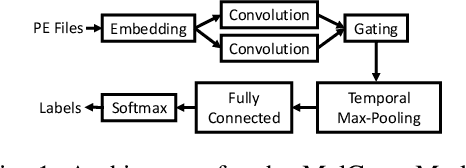

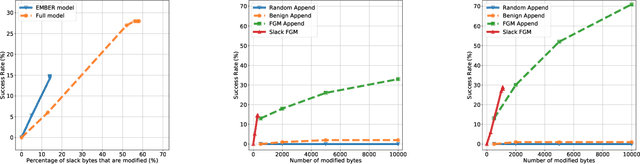

The Convolutional Neural Network (CNN) architecture is increasingly being applied to new domains, such as malware detection, where it is able to learn malicious behavior from raw bytes extracted from executables. These architectures reach impressive performance with no feature engineering effort involved, but their robustness against active attackers is yet to be understood. Such malware detectors could face a new attack vector in the form of adversarial interference with the classification model. Existing evasion attacks intended to cause misclassification on test-time instances, which have been extensively studied for image classifiers, are not applicable because of the input semantics that prevents arbitrary changes to the binaries. This paper explores the area of adversarial examples for malware detection. By training an existing model on a production-scale dataset, we show that some previous attacks are less effective than initially reported, while simultaneously highlighting architectural weaknesses that facilitate new attack strategies for malware classification. Finally, we explore more generalizable attack strategies that increase the potential effectiveness of evasion attacks.
Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks
Apr 03, 2018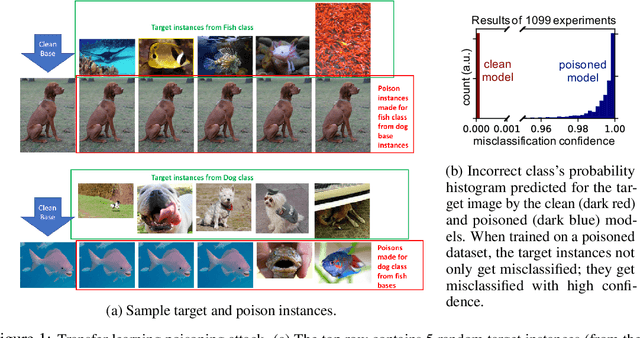
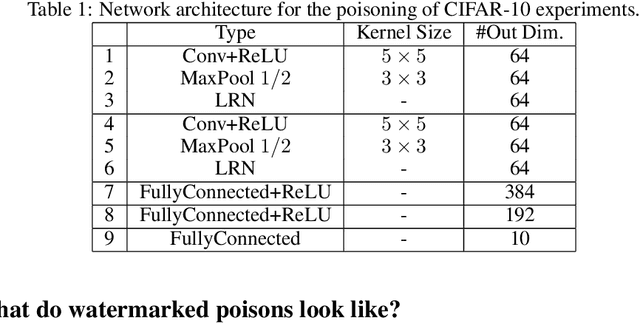
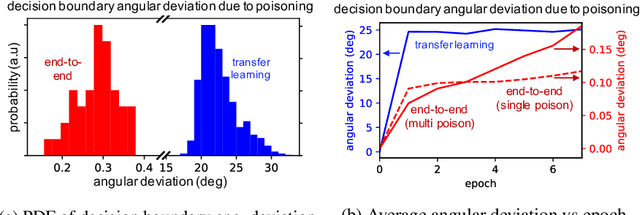
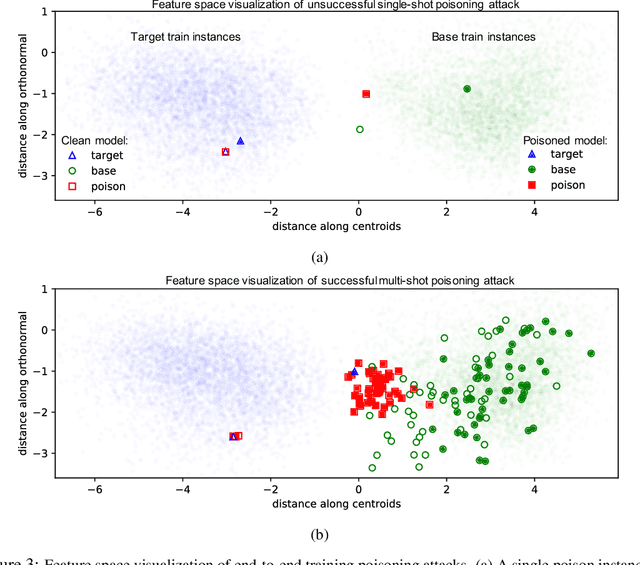
Data poisoning is a type of adversarial attack on machine learning models wherein the attacker adds examples to the training set to manipulate the behavior of the model at test time. This paper explores a broad class of poisoning attacks on neural nets. The proposed attacks use "clean-labels"; they don't require the attacker to have any control over the labeling of training data. They are also targeted; they control the behavior of the classifier on a specific test instance without noticeably degrading classifier performance on other instances. For example, an attacker could add a seemingly innocuous image (that is properly labeled) to a training set for a face recognition engine, and control the identity of a chosen person at test time. Because the attacker does not need to control the labeling function, poisons could be entered into the training set simply by putting them online and waiting for them to be scraped by a data collection bot. We present an optimization-based method for crafting poisons, and show that just one single poison image can control classifier behavior when transfer learning is used. For full end-to-end training, we present a "watermarking" strategy that makes poisoning reliable using multiple (~50) poisoned training instances. We demonstrate our method by generating poisoned frog images from the CIFAR dataset and using them to manipulate image classifiers.
When Does Machine Learning FAIL? Generalized Transferability for Evasion and Poisoning Attacks
Mar 19, 2018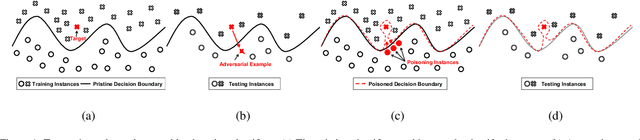
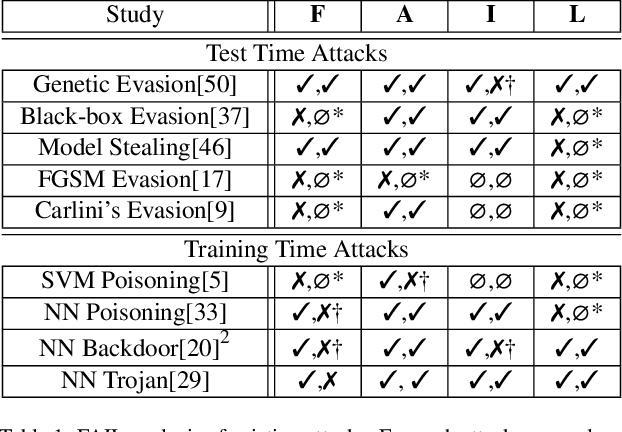


Attacks against machine learning systems represent a growing threat as highlighted by the abundance of attacks proposed lately. However, attacks often make unrealistic assumptions about the knowledge and capabilities of adversaries. To evaluate this threat systematically, we propose the FAIL attacker model, which describes the adversary's knowledge and control along four dimensions. The FAIL model allows us to consider a wide range of weaker adversaries that have limited control and incomplete knowledge of the features, learning algorithms and training instances utilized. Within this framework, we evaluate the generalized transferability of a known evasion attack and we design StingRay, a targeted poisoning attack that is broadly applicable---it is practical against 4 machine learning applications, which use 3 different learning algorithms, and it can bypass 2 existing defenses. Our evaluation provides deeper insights into the transferability of poison and evasion samples across models and suggests promising directions for investigating defenses against this threat.
Summoning Demons: The Pursuit of Exploitable Bugs in Machine Learning
Jan 17, 2017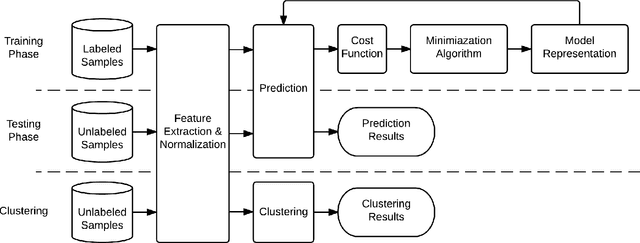

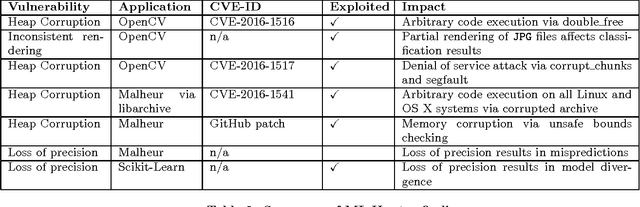

Governments and businesses increasingly rely on data analytics and machine learning (ML) for improving their competitive edge in areas such as consumer satisfaction, threat intelligence, decision making, and product efficiency. However, by cleverly corrupting a subset of data used as input to a target's ML algorithms, an adversary can perturb outcomes and compromise the effectiveness of ML technology. While prior work in the field of adversarial machine learning has studied the impact of input manipulation on correct ML algorithms, we consider the exploitation of bugs in ML implementations. In this paper, we characterize the attack surface of ML programs, and we show that malicious inputs exploiting implementation bugs enable strictly more powerful attacks than the classic adversarial machine learning techniques. We propose a semi-automated technique, called steered fuzzing, for exploring this attack surface and for discovering exploitable bugs in machine learning programs, in order to demonstrate the magnitude of this threat. As a result of our work, we responsibly disclosed five vulnerabilities, established three new CVE-IDs, and illuminated a common insecure practice across many machine learning systems. Finally, we outline several research directions for further understanding and mitigating this threat.