 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Diffusion Models are Secretly Good at Visual In-Context Learning
Aug 13, 2025Large language models (LLM) in natural language processing (NLP) have demonstrated great potential for in-context learning (ICL) -- the ability to leverage a few sets of example prompts to adapt to various tasks without having to explicitly update the model weights. ICL has recently been explored for computer vision tasks with promising early outcomes. These approaches involve specialized training and/or additional data that complicate the process and limit its generalizability. In this work, we show that off-the-shelf Stable Diffusion models can be repurposed for visual in-context learning (V-ICL). Specifically, we formulate an in-place attention re-computation within the self-attention layers of the Stable Diffusion architecture that explicitly incorporates context between the query and example prompts. Without any additional fine-tuning, we show that this repurposed Stable Diffusion model is able to adapt to six different tasks: foreground segmentation, single object detection, semantic segmentation, keypoint detection, edge detection, and colorization. For example, the proposed approach improves the mean intersection over union (mIoU) for the foreground segmentation task on Pascal-5i dataset by 8.9% and 3.2% over recent methods such as Visual Prompting and IMProv, respectively. Additionally, we show that the proposed method is able to effectively leverage multiple prompts through ensembling to infer the task better and further improve the performance.
Adaptive Weight Decay: On The Fly Weight Decay Tuning for Improving Robustness
Sep 30, 2022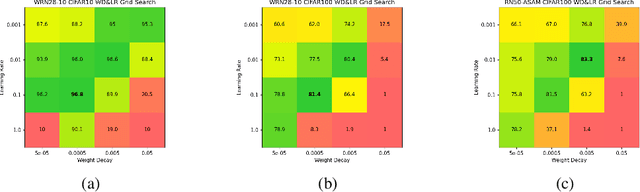

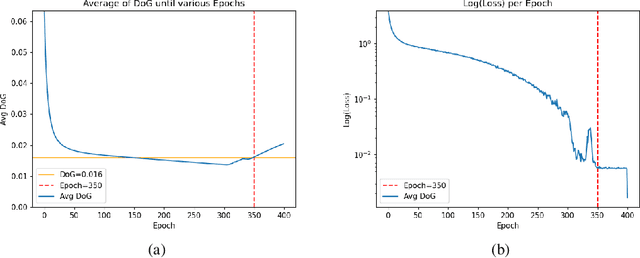

We introduce adaptive weight decay, which automatically tunes the hyper-parameter for weight decay during each training iteration. For classification problems, we propose changing the value of the weight decay hyper-parameter on the fly based on the strength of updates from the classification loss (i.e., gradient of cross-entropy), and the regularization loss (i.e., $\ell_2$-norm of the weights). We show that this simple modification can result in large improvements in adversarial robustness -- an area which suffers from robust overfitting -- without requiring extra data. Specifically, our reformulation results in 20% relative robustness improvement for CIFAR-100, and 10% relative robustness improvement on CIFAR-10 comparing to traditional weight decay. In addition, this method has other desirable properties, such as less sensitivity to learning rate, and smaller weight norms, which the latter contributes to robustness to overfitting to label noise, and pruning.
Towards Accurate Quantization and Pruning via Data-free Knowledge Transfer
Oct 14, 2020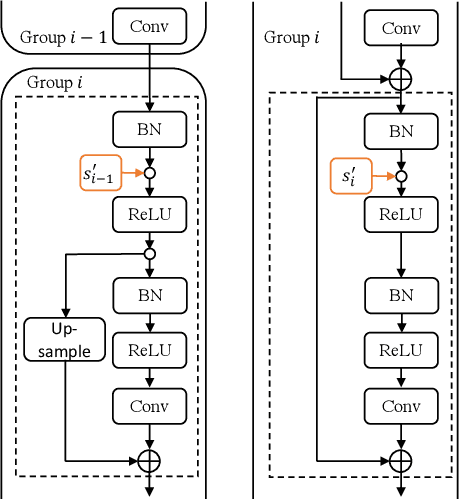
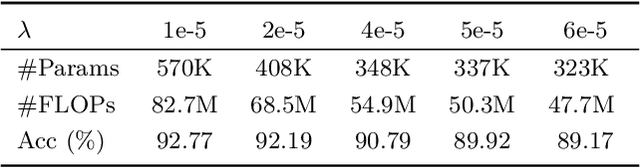
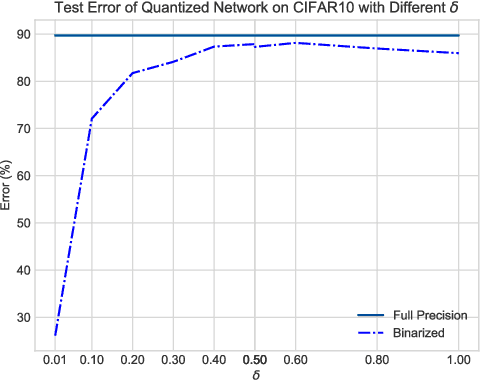
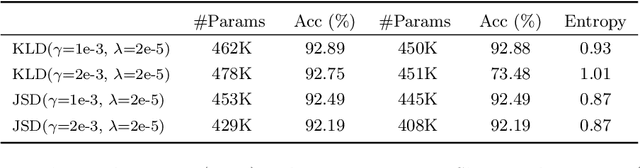
When large scale training data is available, one can obtain compact and accurate networks to be deployed in resource-constrained environments effectively through quantization and pruning. However, training data are often protected due to privacy concerns and it is challenging to obtain compact networks without data. We study data-free quantization and pruning by transferring knowledge from trained large networks to compact networks. Auxiliary generators are simultaneously and adversarially trained with the targeted compact networks to generate synthetic inputs that maximize the discrepancy between the given large network and its quantized or pruned version. We show theoretically that the alternating optimization for the underlying minimax problem converges under mild conditions for pruning and quantization. Our data-free compact networks achieve competitive accuracy to networks trained and fine-tuned with training data. Our quantized and pruned networks achieve good performance while being more compact and lightweight. Further, we demonstrate that the compact structure and corresponding initialization from the Lottery Ticket Hypothesis can also help in data-free training.
Exploring Model Robustness with Adaptive Networks and Improved Adversarial Training
May 30, 2020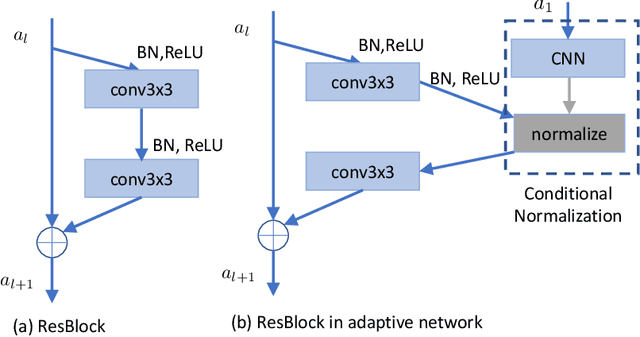
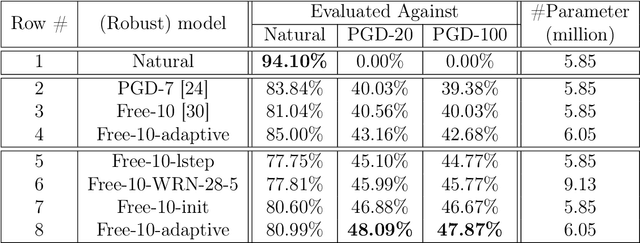
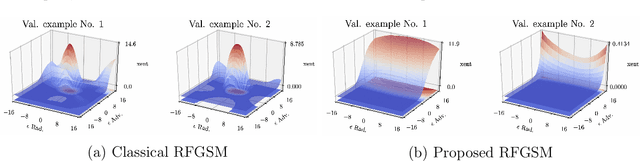
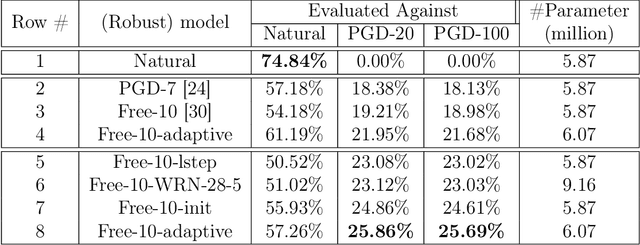
Adversarial training has proven to be effective in hardening networks against adversarial examples. However, the gained robustness is limited by network capacity and number of training samples. Consequently, to build more robust models, it is common practice to train on widened networks with more parameters. To boost robustness, we propose a conditional normalization module to adapt networks when conditioned on input samples. Our adaptive networks, once adversarially trained, can outperform their non-adaptive counterparts on both clean validation accuracy and robustness. Our method is objective agnostic and consistently improves both the conventional adversarial training objective and the TRADES objective. Our adaptive networks also outperform larger widened non-adaptive architectures that have 1.5 times more parameters. We further introduce several practical ``tricks'' in adversarial training to improve robustness and empirically verify their efficiency.
Breaking certified defenses: Semantic adversarial examples with spoofed robustness certificates
Mar 19, 2020

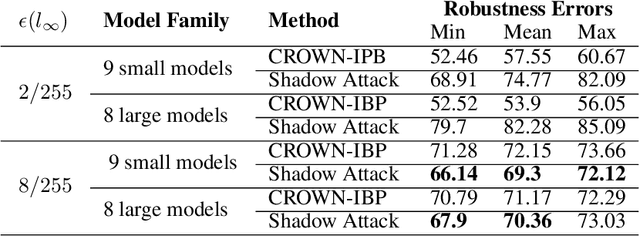

To deflect adversarial attacks, a range of "certified" classifiers have been proposed. In addition to labeling an image, certified classifiers produce (when possible) a certificate guaranteeing that the input image is not an $\ell_p$-bounded adversarial example. We present a new attack that exploits not only the labelling function of a classifier, but also the certificate generator. The proposed method applies large perturbations that place images far from a class boundary while maintaining the imperceptibility property of adversarial examples. The proposed "Shadow Attack" causes certifiably robust networks to mislabel an image and simultaneously produce a "spoofed" certificate of robustness.
WITCHcraft: Efficient PGD attacks with random step size
Nov 18, 2019



State-of-the-art adversarial attacks on neural networks use expensive iterative methods and numerous random restarts from different initial points. Iterative FGSM-based methods without restarts trade off performance for computational efficiency because they do not adequately explore the image space and are highly sensitive to the choice of step size. We propose a variant of Projected Gradient Descent (PGD) that uses a random step size to improve performance without resorting to expensive random restarts. Our method, Wide Iterative Stochastic crafting (WITCHcraft), achieves results superior to the classical PGD attack on the CIFAR-10 and MNIST data sets but without additional computational cost. This simple modification of PGD makes crafting attacks more economical, which is important in situations like adversarial training where attacks need to be crafted in real time.
Label Smoothing and Logit Squeezing: A Replacement for Adversarial Training?
Oct 25, 2019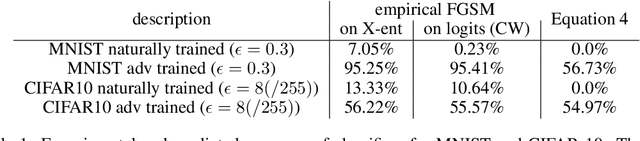
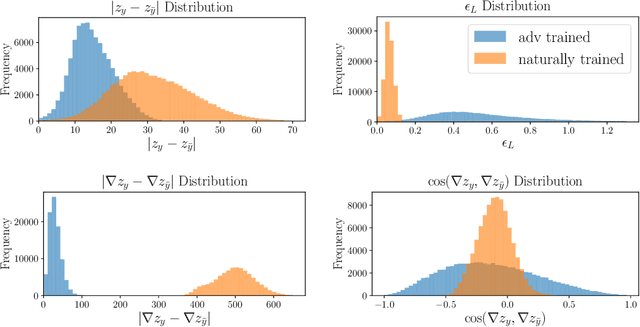
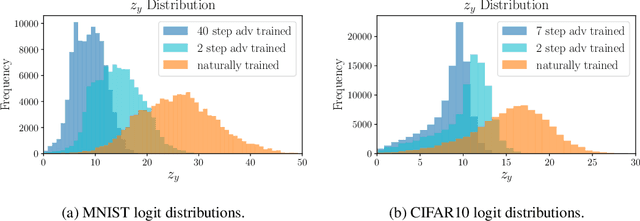
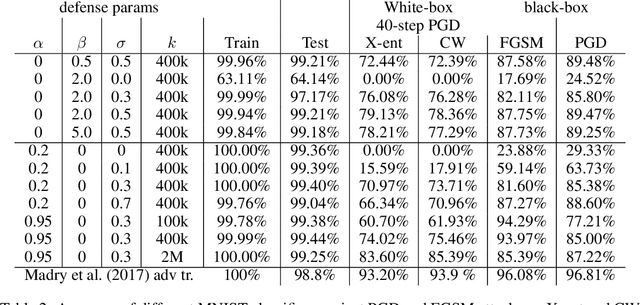
Adversarial training is one of the strongest defenses against adversarial attacks, but it requires adversarial examples to be generated for every mini-batch during optimization. The expense of producing these examples during training often precludes adversarial training from use on complex image datasets. In this study, we explore the mechanisms by which adversarial training improves classifier robustness, and show that these mechanisms can be effectively mimicked using simple regularization methods, including label smoothing and logit squeezing. Remarkably, using these simple regularization methods in combination with Gaussian noise injection, we are able to achieve strong adversarial robustness -- often exceeding that of adversarial training -- using no adversarial examples.
Adversarial attacks on Copyright Detection Systems
Jun 20, 2019


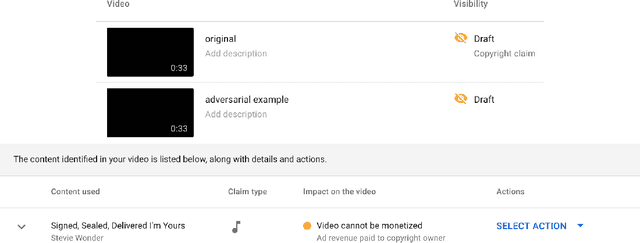
It is well-known that many machine learning models are susceptible to adversarial attacks, in which an attacker evades a classifier by making small perturbations to inputs. This paper discusses how industrial copyright detection tools, which serve a central role on the web, are susceptible to adversarial attacks. We discuss a range of copyright detection systems, and why they are particularly vulnerable to attacks. These vulnerabilities are especially apparent for neural network based systems. As a proof of concept, we describe a well-known music identification method, and implement this system in the form of a neural net. We then attack this system using simple gradient methods. Adversarial music created this way successfully fools industrial systems, including the AudioTag copyright detector and YouTube's Content ID system. Our goal is to raise awareness of the threats posed by adversarial examples in this space, and to highlight the importance of hardening copyright detection systems to attacks.
Adversarially robust transfer learning
May 20, 2019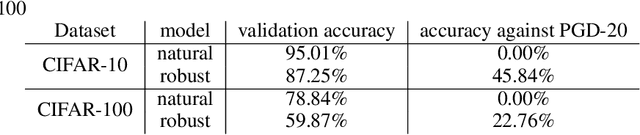
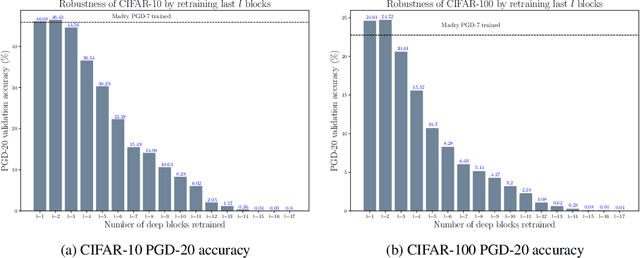
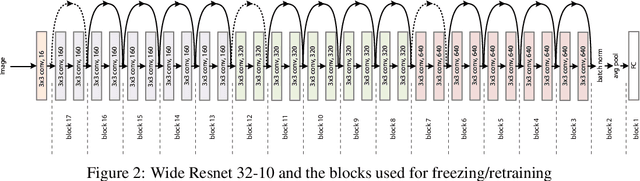
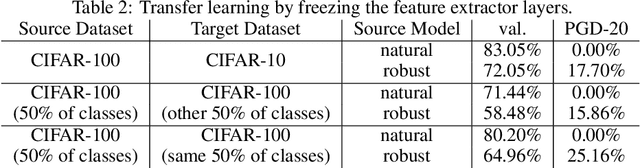
Transfer learning, in which a network is trained on one task and re-purposed on another, is often used to produce neural network classifiers when data is scarce or full-scale training is too costly. When the goal is to produce a model that is not only accurate but also adversarially robust, data scarcity and computational limitations become even more cumbersome. We consider robust transfer learning, in which we transfer not only performance but also robustness from a source model to a target domain. We start by observing that robust networks contain robust feature extractors. By training classifiers on top of these feature extractors, we produce new models that inherit the robustness of their parent networks. We then consider the case of fine-tuning a network by re-training end-to-end in the target domain. When using lifelong learning strategies, this process preserves the robustness of the source network while achieving high accuracy. By using such strategies, it is possible to produce accurate and robust models with little data, and without the cost of adversarial training.
Transferable Clean-Label Poisoning Attacks on Deep Neural Nets
May 16, 2019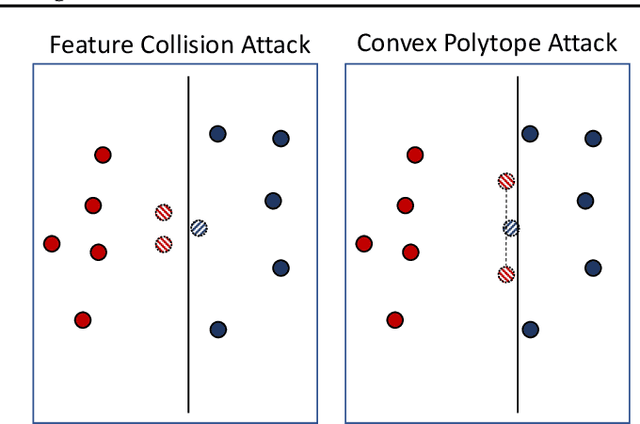

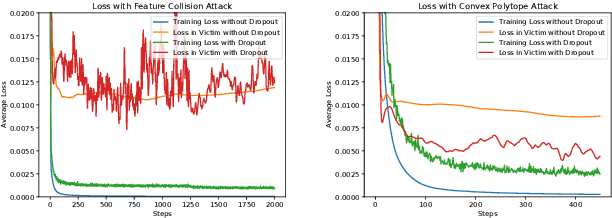

Clean-label poisoning attacks inject innocuous looking (and "correctly" labeled) poison images into training data, causing a model to misclassify a targeted image after being trained on this data. We consider transferable poisoning attacks that succeed without access to the victim network's outputs, architecture, or (in some cases) training data. To achieve this, we propose a new "polytope attack" in which poison images are designed to surround the targeted image in feature space. We also demonstrate that using Dropout during poison creation helps to enhance transferability of this attack. We achieve transferable attack success rates of over 50% while poisoning only 1% of the training set.