 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Scaling Agent Learning via Experience Synthesis
Nov 10, 2025



While reinforcement learning (RL) can empower autonomous agents by enabling self-improvement through interaction, its practical adoption remains challenging due to costly rollouts, limited task diversity, unreliable reward signals, and infrastructure complexity, all of which obstruct the collection of scalable experience data. To address these challenges, we introduce DreamGym, the first unified framework designed to synthesize diverse experiences with scalability in mind to enable effective online RL training for autonomous agents. Rather than relying on expensive real-environment rollouts, DreamGym distills environment dynamics into a reasoning-based experience model that derives consistent state transitions and feedback signals through step-by-step reasoning, enabling scalable agent rollout collection for RL. To improve the stability and quality of transitions, DreamGym leverages an experience replay buffer initialized with offline real-world data and continuously enriched with fresh interactions to actively support agent training. To improve knowledge acquisition, DreamGym adaptively generates new tasks that challenge the current agent policy, enabling more effective online curriculum learning. Experiments across diverse environments and agent backbones demonstrate that DreamGym substantially improves RL training, both in fully synthetic settings and in sim-to-real transfer scenarios. On non-RL-ready tasks like WebArena, DreamGym outperforms all baselines by over 30%. And in RL-ready but costly settings, it matches GRPO and PPO performance using only synthetic interactions. When transferring a policy trained purely on synthetic experiences to real-environment RL, DreamGym yields significant additional performance gains while requiring far fewer real-world interactions, providing a scalable warm-start strategy for general-purpose RL.
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Apr 08, 2024



With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
Object Recognition as Next Token Prediction
Dec 04, 2023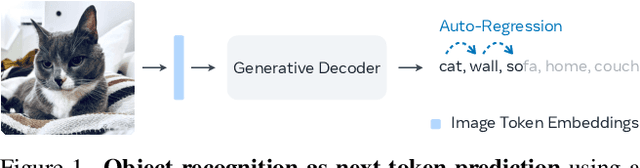
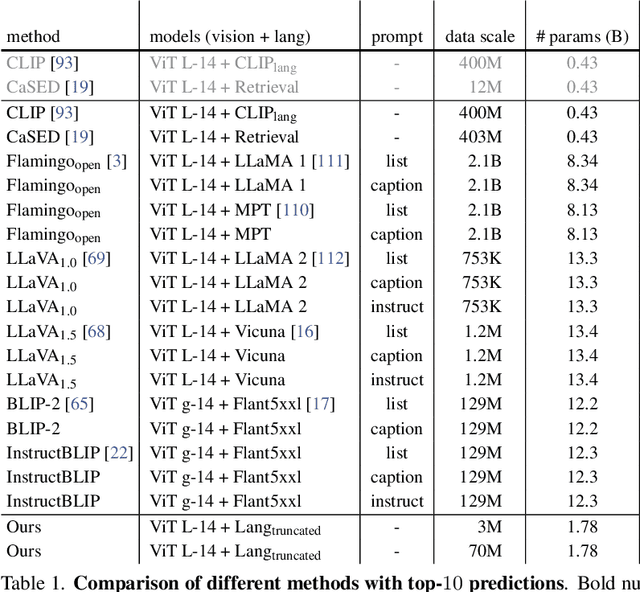
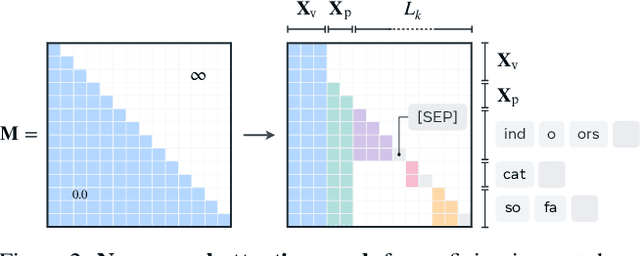

We present an approach to pose object recognition as next token prediction. The idea is to apply a language decoder that auto-regressively predicts the text tokens from image embeddings to form labels. To ground this prediction process in auto-regression, we customize a non-causal attention mask for the decoder, incorporating two key features: modeling tokens from different labels to be independent, and treating image tokens as a prefix. This masking mechanism inspires an efficient method - one-shot sampling - to simultaneously sample tokens of multiple labels in parallel and rank generated labels by their probabilities during inference. To further enhance the efficiency, we propose a simple strategy to construct a compact decoder by simply discarding the intermediate blocks of a pretrained language model. This approach yields a decoder that matches the full model's performance while being notably more efficient. The code is available at https://github.com/kaiyuyue/nxtp
SEGIC: Unleashing the Emergent Correspondence for In-Context Segmentation
Nov 24, 2023



In-context segmentation aims at segmenting novel images using a few labeled example images, termed as "in-context examples", exploring content similarities between examples and the target. The resulting models can be generalized seamlessly to novel segmentation tasks, significantly reducing the labeling and training costs compared with conventional pipelines. However, in-context segmentation is more challenging than classic ones due to its meta-learning nature, requiring the model to learn segmentation rules conditioned on a few samples, not just the segmentation. Unlike previous work with ad-hoc or non-end-to-end designs, we propose SEGIC, an end-to-end segment-in-context framework built upon a single vision foundation model (VFM). In particular, SEGIC leverages the emergent correspondence within VFM to capture dense relationships between target images and in-context samples. As such, information from in-context samples is then extracted into three types of instructions, i.e. geometric, visual, and meta instructions, serving as explicit conditions for the final mask prediction. SEGIC is a straightforward yet effective approach that yields state-of-the-art performance on one-shot segmentation benchmarks. Notably, SEGIC can be easily generalized to diverse tasks, including video object segmentation and open-vocabulary segmentation. Code will be available at \url{https://github.com/MengLcool/SEGIC}.
BMB: Balanced Memory Bank for Imbalanced Semi-supervised Learning
May 22, 2023Exploring a substantial amount of unlabeled data, semi-supervised learning (SSL) boosts the recognition performance when only a limited number of labels are provided. However, traditional methods assume that the data distribution is class-balanced, which is difficult to achieve in reality due to the long-tailed nature of real-world data. While the data imbalance problem has been extensively studied in supervised learning (SL) paradigms, directly transferring existing approaches to SSL is nontrivial, as prior knowledge about data distribution remains unknown in SSL. In light of this, we propose Balanced Memory Bank (BMB), a semi-supervised framework for long-tailed recognition. The core of BMB is an online-updated memory bank that caches historical features with their corresponding pseudo labels, and the memory is also carefully maintained to ensure the data therein are class-rebalanced. Additionally, an adaptive weighting module is introduced to work jointly with the memory bank so as to further re-calibrate the biased training process. We conduct experiments on multiple datasets and demonstrate, among other things, that BMB surpasses state-of-the-art approaches by clear margins, for example 8.2$\%$ on the 1$\%$ labeled subset of ImageNet127 (with a resolution of 64$\times$64) and 4.3$\%$ on the 50$\%$ labeled subset of ImageNet-LT.
Semi-Supervised Single-View 3D Reconstruction via Prototype Shape Priors
Sep 30, 2022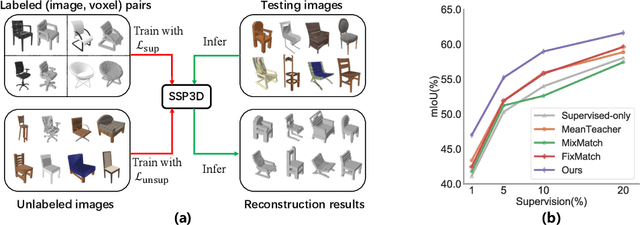
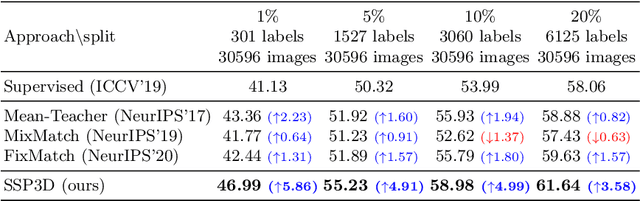

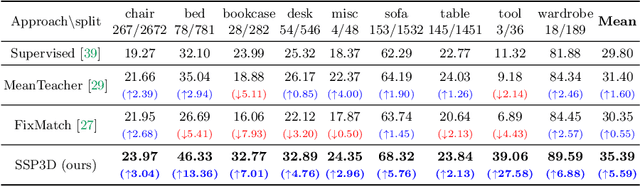
The performance of existing single-view 3D reconstruction methods heavily relies on large-scale 3D annotations. However, such annotations are tedious and expensive to collect. Semi-supervised learning serves as an alternative way to mitigate the need for manual labels, but remains unexplored in 3D reconstruction. Inspired by the recent success of semi-supervised image classification tasks, we propose SSP3D, a semi-supervised framework for 3D reconstruction. In particular, we introduce an attention-guided prototype shape prior module for guiding realistic object reconstruction. We further introduce a discriminator-guided module to incentivize better shape generation, as well as a regularizer to tolerate noisy training samples. On the ShapeNet benchmark, the proposed approach outperforms previous supervised methods by clear margins under various labeling ratios, (i.e., 1%, 5% , 10% and 20%). Moreover, our approach also performs well when transferring to real-world Pix3D datasets under labeling ratios of 10%. We also demonstrate our method could transfer to novel categories with few novel supervised data. Experiments on the popular ShapeNet dataset show that our method outperforms the zero-shot baseline by over 12% and we also perform rigorous ablations and analysis to validate our approach.
AdaViT: Adaptive Vision Transformers for Efficient Image Recognition
Nov 30, 2021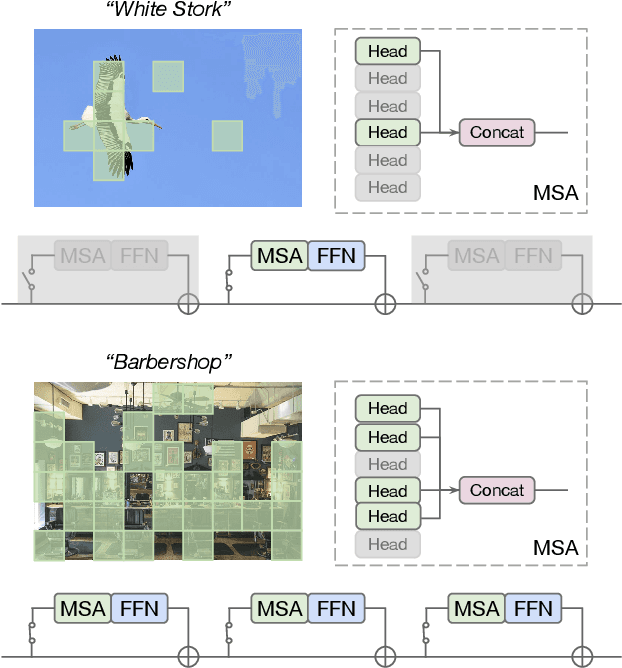
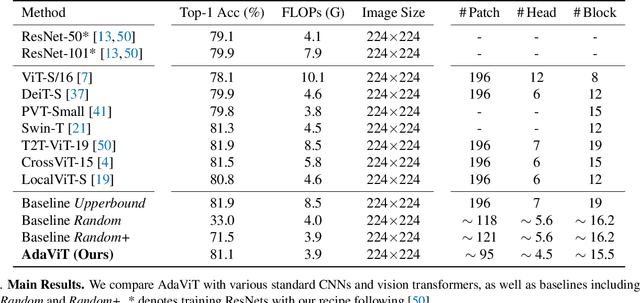
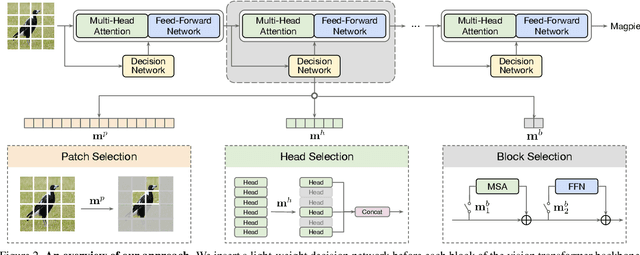

Built on top of self-attention mechanisms, vision transformers have demonstrated remarkable performance on a variety of vision tasks recently. While achieving excellent performance, they still require relatively intensive computational cost that scales up drastically as the numbers of patches, self-attention heads and transformer blocks increase. In this paper, we argue that due to the large variations among images, their need for modeling long-range dependencies between patches differ. To this end, we introduce AdaViT, an adaptive computation framework that learns to derive usage policies on which patches, self-attention heads and transformer blocks to use throughout the backbone on a per-input basis, aiming to improve inference efficiency of vision transformers with a minimal drop of accuracy for image recognition. Optimized jointly with a transformer backbone in an end-to-end manner, a light-weight decision network is attached to the backbone to produce decisions on-the-fly. Extensive experiments on ImageNet demonstrate that our method obtains more than 2x improvement on efficiency compared to state-of-the-art vision transformers with only 0.8% drop of accuracy, achieving good efficiency/accuracy trade-offs conditioned on different computational budgets. We further conduct quantitative and qualitative analysis on learned usage polices and provide more insights on the redundancy in vision transformers.
Efficient Video Transformers with Spatial-Temporal Token Selection
Nov 23, 2021
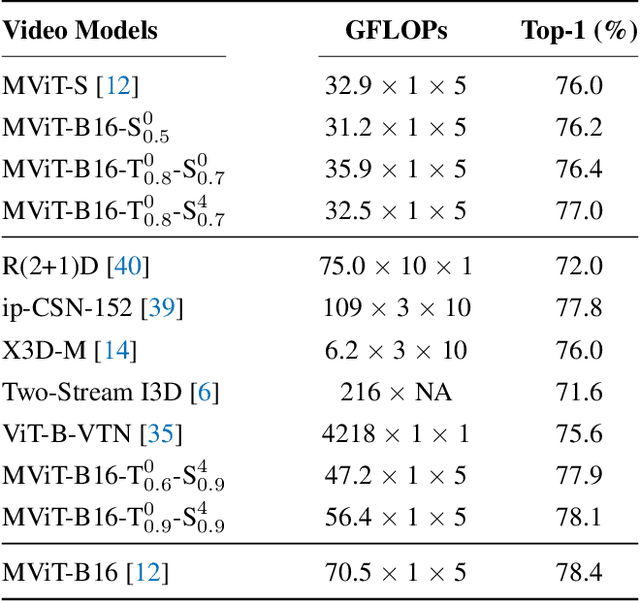
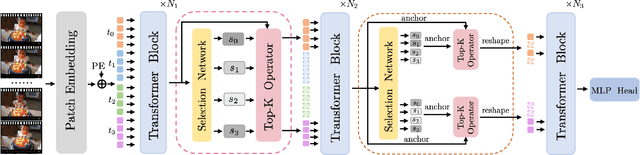
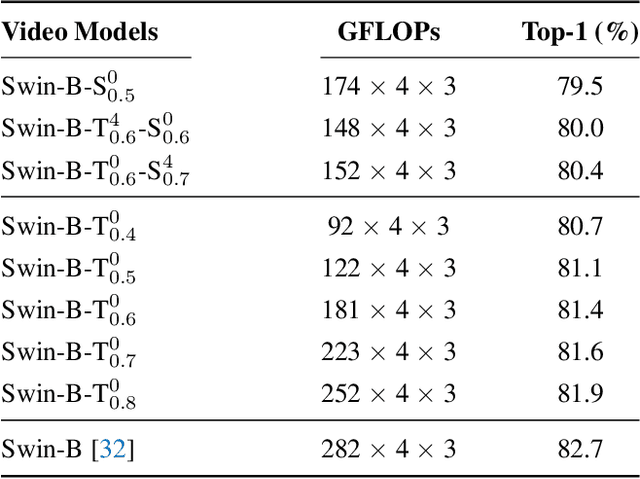
Video transformers have achieved impressive results on major video recognition benchmarks, however they suffer from high computational cost. In this paper, we present STTS, a token selection framework that dynamically selects a few informative tokens in both temporal and spatial dimensions conditioned on input video samples. Specifically, we formulate token selection as a ranking problem, which estimates the importance of each token through a lightweight selection network and only those with top scores will be used for downstream evaluation. In the temporal dimension, we keep the frames that are most relevant for recognizing action categories, while in the spatial dimension, we identify the most discriminative region in feature maps without affecting spatial context used in a hierarchical way in most video transformers. Since the decision of token selection is non-differentiable, we employ a perturbed-maximum based differentiable Top-K operator for end-to-end training. We conduct extensive experiments on Kinetics-400 with a recently introduced video transformer backbone, MViT. Our framework achieves similar results while requiring 20% less computation. We also demonstrate that our approach is compatible with other transformer architectures.
Rethinking Pseudo Labels for Semi-Supervised Object Detection
Jun 01, 2021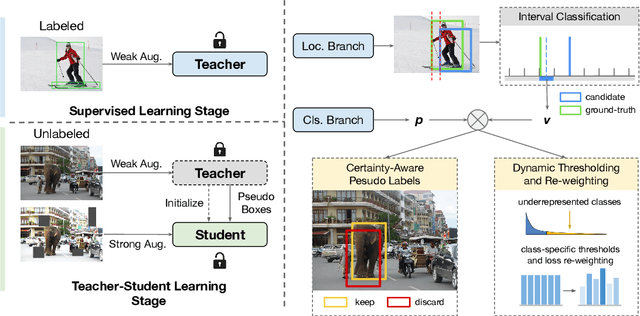
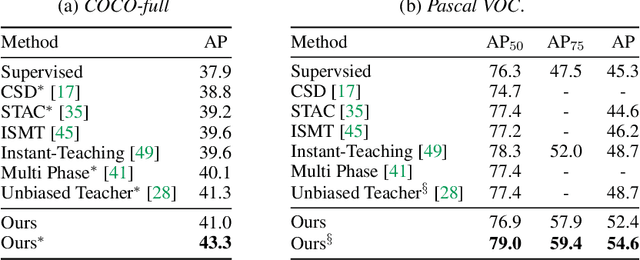
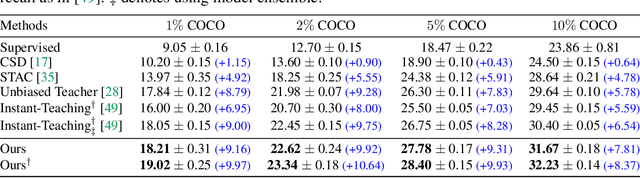
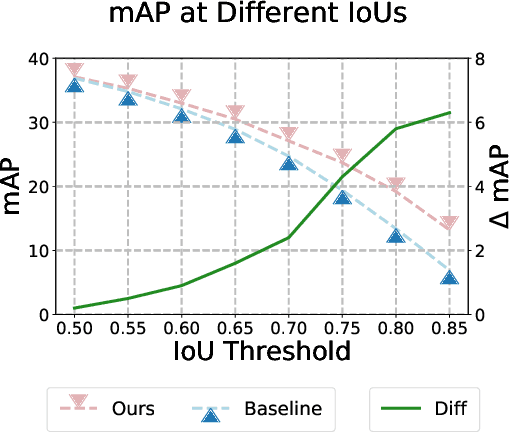
Recent advances in semi-supervised object detection (SSOD) are largely driven by consistency-based pseudo-labeling methods for image classification tasks, producing pseudo labels as supervisory signals. However, when using pseudo labels, there is a lack of consideration in localization precision and amplified class imbalance, both of which are critical for detection tasks. In this paper, we introduce certainty-aware pseudo labels tailored for object detection, which can effectively estimate the classification and localization quality of derived pseudo labels. This is achieved by converting conventional localization as a classification task followed by refinement. Conditioned on classification and localization quality scores, we dynamically adjust the thresholds used to generate pseudo labels and reweight loss functions for each category to alleviate the class imbalance problem. Extensive experiments demonstrate that our method improves state-of-the-art SSOD performance by 1-2% and 4-6% AP on COCO and PASCAL VOC, respectively. In the limited-annotation regime, our approach improves supervised baselines by up to 10% AP using only 1-10% labeled data from COCO.