 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMBGuard: Constructing Hazard-Aware Guardrails for Safe Planning in Embodied Agents
May 29, 2026MLLM-powered embodied agents deployed in real-world environments encounter physical hazards. However, existing approaches lack explicit mechanisms for identifying hazards and reasoning about action-conditioned risks, leading agents to either miss risky interactions or over-identify risks. To address this, we propose EMBGuard, the first MLLM-based safety guardrail for embodied agents designed to decouple physical risk reasoning from agent policy. By evaluating a (visual observation, action) pair, EMBGuard identifies hazardous configurations and provides natural language explanations of potential risks. Alongside EMBGuard, we contribute EMBHazard, a training dataset of 15.1K action-conditioned pairs, and EMBGuardTest, a benchmark of 329 manually curated real-world scenarios spanning seven physical risk categories. Through compositional variation of hazards and actions, we generate diverse risky and benign scenarios that agents may encounter during planning. Despite its compact size (2B, 4B), EMBGuard achieves performance competitive with proprietary MLLMs (e.g., GPT-5.1, Gemini-2.5-Pro) while significantly reducing the false-positive rates that hinder real-time deployment. We make the code, data, and models publicly available at https://github.com/dongwxxkchoi/EMBGuard
FAST-GOAL: Fast and Efficient Global-local Object Alignment Learning
May 26, 2026Vision-language models such as CLIP have shown impressive capabilities in aligning images and text, but they often struggle with lengthy and detailed text descriptions due to pre-training on short and concise captions. We present FAST-GOAL (Fast and Efficient Global-local Object Alignment Learning), an efficient fine-tuning method that enhances ability of CLIP to handle lengthy text through global-local semantic alignment. Our method consists of two key components. First, Fast Local Image-Sentence Matching (FLISM) efficiently extracts local image regions through object detection and spatial division, then matches them with corresponding sentences. Second, Token Similarity-based Learning (TSL) maximizes the similarity between patch tokens from specific regions in the image and their corresponding region embeddings, applying the same principle to text, which enhances the ability of the model to capture detailed correspondences. Additionally, we introduce GLIT100k, a dataset that provides both global image-lengthy caption pairs and context-derived local pairs, where local descriptions are extracted from global captions to maintain semantic coherence. Through extensive experiments on long caption datasets (DOCCI, DCI) and short caption datasets (MSCOCO, Flickr30k), we demonstrate that FAST-GOAL achieves significant improvements over baselines, enabling effective adaptation of CLIP to detailed textual descriptions while maintaining computational efficiency.
CoVA: Text-Guided Composed Video Retrieval for Audio-Visual Content
Jan 30, 2026Composed Video Retrieval (CoVR) aims to retrieve a target video from a large gallery using a reference video and a textual query specifying visual modifications. However, existing benchmarks consider only visual changes, ignoring videos that differ in audio despite visual similarity. To address this limitation, we introduce Composed retrieval for Video with its Audio CoVA, a new retrieval task that accounts for both visual and auditory variations. To support this, we construct AV-Comp, a benchmark consisting of video pairs with cross-modal changes and corresponding textual queries that describe the differences. We also propose AVT Compositional Fusion (AVT), which integrates video, audio, and text features by selectively aligning the query to the most relevant modality. AVT outperforms traditional unimodal fusion and serves as a strong baseline for CoVA. Examples from the proposed dataset, including both visual and auditory information, are available at https://perceptualai-lab.github.io/CoVA/.
Distilling Vision-Language Pretraining for Efficient Cross-Modal Retrieval
May 23, 2024

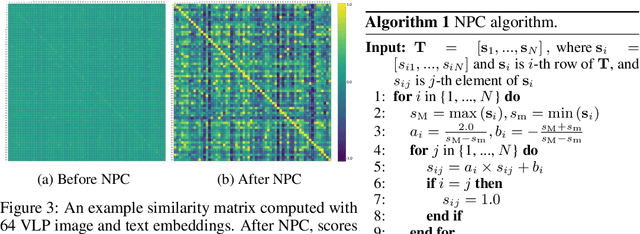
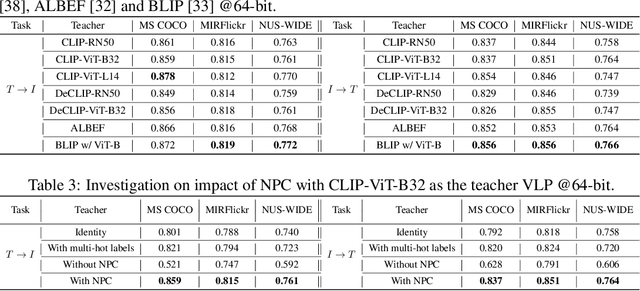
``Learning to hash'' is a practical solution for efficient retrieval, offering fast search speed and low storage cost. It is widely applied in various applications, such as image-text cross-modal search. In this paper, we explore the potential of enhancing the performance of learning to hash with the proliferation of powerful large pre-trained models, such as Vision-Language Pre-training (VLP) models. We introduce a novel method named Distillation for Cross-Modal Quantization (DCMQ), which leverages the rich semantic knowledge of VLP models to improve hash representation learning. Specifically, we use the VLP as a `teacher' to distill knowledge into a `student' hashing model equipped with codebooks. This process involves the replacement of supervised labels, which are composed of multi-hot vectors and lack semantics, with the rich semantics of VLP. In the end, we apply a transformation termed Normalization with Paired Consistency (NPC) to achieve a discriminative target for distillation. Further, we introduce a new quantization method, Product Quantization with Gumbel (PQG) that promotes balanced codebook learning, thereby improving the retrieval performance. Extensive benchmark testing demonstrates that DCMQ consistently outperforms existing supervised cross-modal hashing approaches, showcasing its significant potential.
Towards Cross-modal Backward-compatible Representation Learning for Vision-Language Models
May 23, 2024Modern retrieval systems often struggle with upgrading to new and more powerful models due to the incompatibility of embeddings between the old and new models. This necessitates a costly process known as backfilling, which involves re-computing the embeddings for a large number of data samples. In vision, Backward-compatible Training (BT) has been proposed to ensure that the new model aligns with the old model's embeddings. This paper extends the concept of vision-only BT to the field of cross-modal retrieval, marking the first attempt to address Cross-modal BT (XBT). Our goal is to achieve backward-compatibility between Vision-Language Pretraining (VLP) models, such as CLIP, for the cross-modal retrieval task. To address XBT challenges, we propose an efficient solution: a projection module that maps the new model's embeddings to those of the old model. This module, pretrained solely with text data, significantly reduces the number of image-text pairs required for XBT learning, and, once it is pretrained, it avoids using the old model during training. Furthermore, we utilize parameter-efficient training strategies that improve efficiency and preserve the off-the-shelf new model's knowledge by avoiding any modifications. Experimental results on cross-modal retrieval datasets demonstrate the effectiveness of XBT and its potential to enable backfill-free upgrades when a new VLP model emerges.
Spherical Linear Interpolation and Text-Anchoring for Zero-shot Composed Image Retrieval
May 01, 2024Composed Image Retrieval (CIR) is a complex task that retrieves images using a query, which is configured with an image and a caption that describes desired modifications to that image. Supervised CIR approaches have shown strong performance, but their reliance on expensive manually-annotated datasets restricts their scalability and broader applicability. To address these issues, previous studies have proposed pseudo-word token-based Zero-Shot CIR (ZS-CIR) methods, which utilize a projection module to map images to word tokens. However, we conjecture that this approach has a downside: the projection module distorts the original image representation and confines the resulting composed embeddings to the text-side. In order to resolve this, we introduce a novel ZS-CIR method that uses Spherical Linear Interpolation (Slerp) to directly merge image and text representations by identifying an intermediate embedding of both. Furthermore, we introduce Text-Anchored-Tuning (TAT), a method that fine-tunes the image encoder while keeping the text encoder fixed. TAT closes the modality gap between images and text, making the Slerp process much more effective. Notably, the TAT method is not only efficient in terms of the scale of the training dataset and training time, but it also serves as an excellent initial checkpoint for training supervised CIR models, thereby highlighting its wider potential. The integration of the Slerp-based ZS-CIR with a TAT-tuned model enables our approach to deliver state-of-the-art retrieval performance across CIR benchmarks.
Visual Delta Generator with Large Multi-modal Models for Semi-supervised Composed Image Retrieval
Apr 23, 2024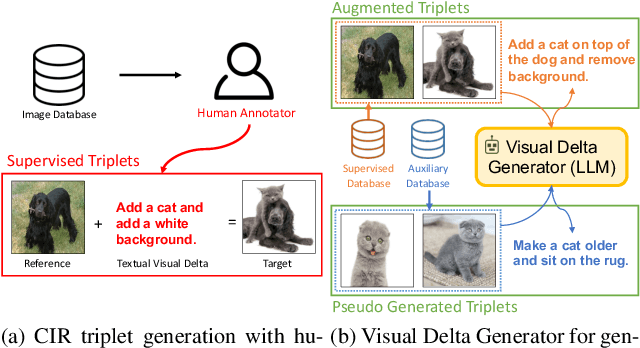
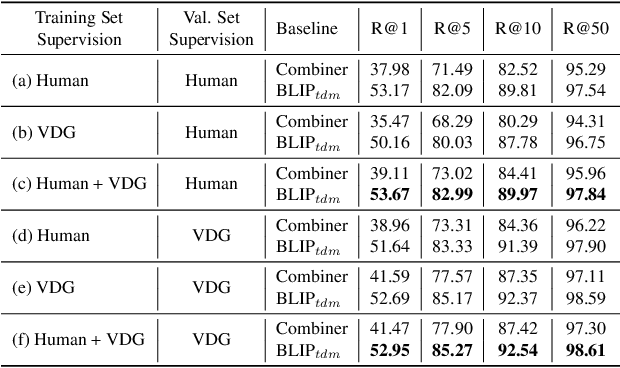
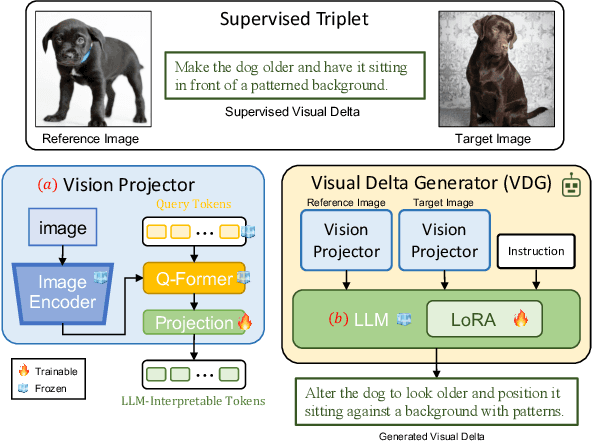
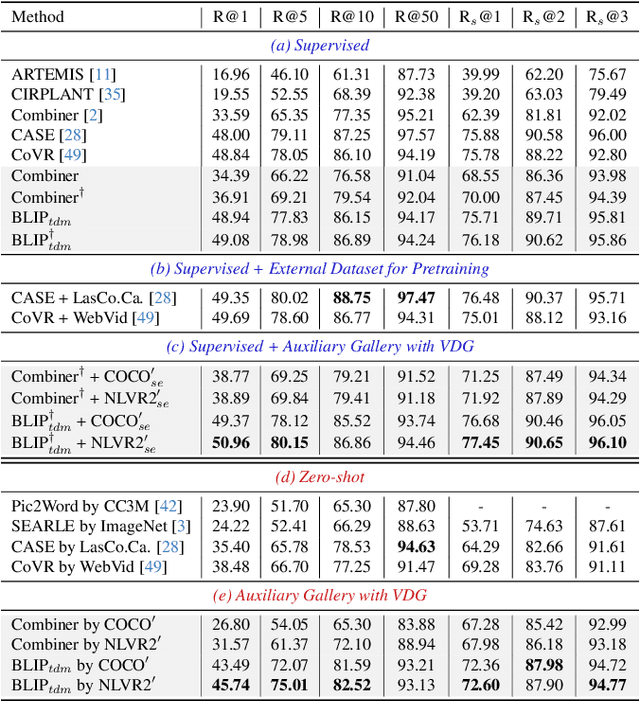
Composed Image Retrieval (CIR) is a task that retrieves images similar to a query, based on a provided textual modification. Current techniques rely on supervised learning for CIR models using labeled triplets of the reference image, text, target image. These specific triplets are not as commonly available as simple image-text pairs, limiting the widespread use of CIR and its scalability. On the other hand, zero-shot CIR can be relatively easily trained with image-caption pairs without considering the image-to-image relation, but this approach tends to yield lower accuracy. We propose a new semi-supervised CIR approach where we search for a reference and its related target images in auxiliary data and learn our large language model-based Visual Delta Generator (VDG) to generate text describing the visual difference (i.e., visual delta) between the two. VDG, equipped with fluent language knowledge and being model agnostic, can generate pseudo triplets to boost the performance of CIR models. Our approach significantly improves the existing supervised learning approaches and achieves state-of-the-art results on the CIR benchmarks.
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Apr 08, 2024



With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
On the Robustness of Large Multimodal Models Against Image Adversarial Attacks
Dec 08, 2023Recent advances in instruction tuning have led to the development of State-of-the-Art Large Multimodal Models (LMMs). Given the novelty of these models, the impact of visual adversarial attacks on LMMs has not been thoroughly examined. We conduct a comprehensive study of the robustness of various LMMs against different adversarial attacks, evaluated across tasks including image classification, image captioning, and Visual Question Answer (VQA). We find that in general LMMs are not robust to visual adversarial inputs. However, our findings suggest that context provided to the model via prompts, such as questions in a QA pair helps to mitigate the effects of visual adversarial inputs. Notably, the LMMs evaluated demonstrated remarkable resilience to such attacks on the ScienceQA task with only an 8.10% drop in performance compared to their visual counterparts which dropped 99.73%. We also propose a new approach to real-world image classification which we term query decomposition. By incorporating existence queries into our input prompt we observe diminished attack effectiveness and improvements in image classification accuracy. This research highlights a previously under-explored facet of LMM robustness and sets the stage for future work aimed at strengthening the resilience of multimodal systems in adversarial environments.
Self-Distilled Hashing for Deep Image Retrieval
Dec 16, 2021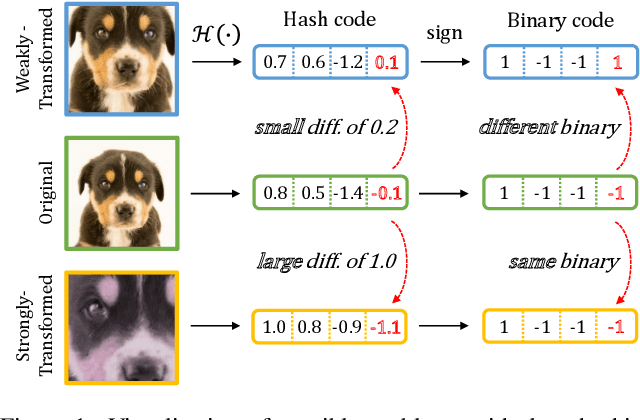

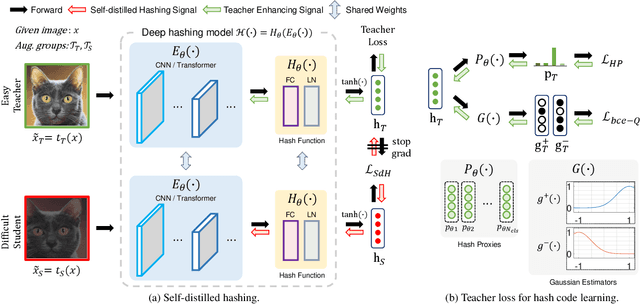

In hash-based image retrieval systems, the transformed input from the original usually generates different codes, deteriorating the retrieval accuracy. To mitigate this issue, data augmentation can be applied during training. However, even if the augmented samples of one content are similar in real space, the quantization can scatter them far away in Hamming space. This results in representation discrepancies that can impede training and degrade performance. In this work, we propose a novel self-distilled hashing scheme to minimize the discrepancy while exploiting the potential of augmented data. By transferring the hash knowledge of the weakly-transformed samples to the strong ones, we make the hash code insensitive to various transformations. We also introduce hash proxy-based similarity learning and binary cross entropy-based quantization loss to provide fine quality hash codes. Ultimately, we construct a deep hashing framework that generates discriminative hash codes. Extensive experiments on benchmarks verify that our self-distillation improves the existing deep hashing approaches, and our framework achieves state-of-the-art retrieval results. The code will be released soon.