 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntriguing Properties of Large Language and Vision Models
Oct 07, 2024Recently, large language and vision models (LLVMs) have received significant attention and development efforts due to their remarkable generalization performance across a wide range of tasks requiring perception and cognitive abilities. A key factor behind their success is their simple architecture, which consists of a vision encoder, a projector, and a large language model (LLM). Despite their achievements in advanced reasoning tasks, their performance on fundamental perception-related tasks (e.g., MMVP) remains surprisingly low. This discrepancy raises the question of how LLVMs truly perceive images and exploit the advantages of the vision encoder. To address this, we systematically investigate this question regarding several aspects: permutation invariance, robustness, math reasoning, alignment preserving and importance, by evaluating the most common LLVM's families (i.e., LLaVA) across 10 evaluation benchmarks. Our extensive experiments reveal several intriguing properties of current LLVMs: (1) they internally process the image in a global manner, even when the order of visual patch sequences is randomly permuted; (2) they are sometimes able to solve math problems without fully perceiving detailed numerical information; (3) the cross-modal alignment is overfitted to complex reasoning tasks, thereby, causing them to lose some of the original perceptual capabilities of their vision encoder; (4) the representation space in the lower layers (<25%) plays a crucial role in determining performance and enhancing visual understanding. Lastly, based on the above observations, we suggest potential future directions for building better LLVMs and constructing more challenging evaluation benchmarks.
Stark: Social Long-Term Multi-Modal Conversation with Persona Commonsense Knowledge
Jul 04, 2024



Humans share a wide variety of images related to their personal experiences within conversations via instant messaging tools. However, existing works focus on (1) image-sharing behavior in singular sessions, leading to limited long-term social interaction, and (2) a lack of personalized image-sharing behavior. In this work, we introduce Stark, a large-scale long-term multi-modal conversation dataset that covers a wide range of social personas in a multi-modality format, time intervals, and images. To construct Stark automatically, we propose a novel multi-modal contextualization framework, Mcu, that generates long-term multi-modal dialogue distilled from ChatGPT and our proposed Plan-and-Execute image aligner. Using our Stark, we train a multi-modal conversation model, Ultron 7B, which demonstrates impressive visual imagination ability. Furthermore, we demonstrate the effectiveness of our dataset in human evaluation. We make our source code and dataset publicly available.
VVS: Video-to-Video Retrieval with Irrelevant Frame Suppression
Mar 15, 2023In content-based video retrieval (CBVR), dealing with large-scale collections, efficiency is as important as accuracy. For this reason, several video-level feature-based studies have actively been conducted; nevertheless, owing to the severe difficulty of embedding a lengthy and untrimmed video into a single feature, these studies have shown insufficient for accurate retrieval compared to frame-level feature-based studies. In this paper, we show an insight that appropriate suppression of irrelevant frames can be a clue to overcome the current obstacles of the video-level feature-based approaches. Furthermore, we propose a Video-to-Video Suppression network (VVS) as a solution. The VVS is an end-to-end framework that consists of an easy distractor elimination stage for identifying which frames to remove and a suppression weight generation stage for determining how much to suppress the remaining frames. This structure is intended to effectively describe an untrimmed video with varying content and meaningless information. Its efficacy is proved via extensive experiments, and we show that our approach is not only state-of-the-art in video-level feature-based approaches but also has a fast inference time despite possessing retrieval capabilities close to those of frame-level feature-based approaches.
Group Generalized Mean Pooling for Vision Transformer
Dec 08, 2022



Vision Transformer (ViT) extracts the final representation from either class token or an average of all patch tokens, following the architecture of Transformer in Natural Language Processing (NLP) or Convolutional Neural Networks (CNNs) in computer vision. However, studies for the best way of aggregating the patch tokens are still limited to average pooling, while widely-used pooling strategies, such as max and GeM pooling, can be considered. Despite their effectiveness, the existing pooling strategies do not consider the architecture of ViT and the channel-wise difference in the activation maps, aggregating the crucial and trivial channels with the same importance. In this paper, we present Group Generalized Mean (GGeM) pooling as a simple yet powerful pooling strategy for ViT. GGeM divides the channels into groups and computes GeM pooling with a shared pooling parameter per group. As ViT groups the channels via a multi-head attention mechanism, grouping the channels by GGeM leads to lower head-wise dependence while amplifying important channels on the activation maps. Exploiting GGeM shows 0.1%p to 0.7%p performance boosts compared to the baselines and achieves state-of-the-art performance for ViT-Base and ViT-Large models in ImageNet-1K classification task. Moreover, GGeM outperforms the existing pooling strategies on image retrieval and multi-modal representation learning tasks, demonstrating the superiority of GGeM for a variety of tasks. GGeM is a simple algorithm in that only a few lines of code are necessary for implementation.
DialogCC: Large-Scale Multi-Modal Dialogue Dataset
Dec 08, 2022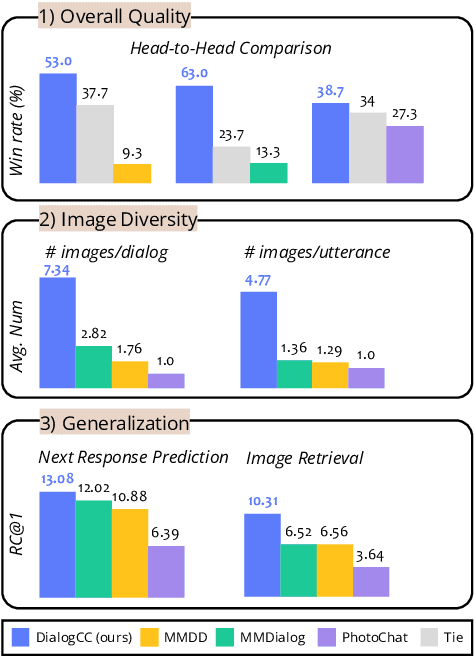



As sharing images in an instant message is a crucial factor, there has been active research on learning a image-text multi-modal dialogue model. However, training a well-generalized multi-modal dialogue model is challenging because existing multi-modal dialogue datasets contain a small number of data, limited topics, and a restricted variety of images per dialogue. In this paper, we present a multi-modal dialogue dataset creation pipeline that involves matching large-scale images to dialogues based on CLIP similarity. Using this automatic pipeline, we propose a large-scale multi-modal dialogue dataset, DialogCC, which covers diverse real-world topics and various images per dialogue. With extensive experiments, we demonstrate that training a multi-modal dialogue model with our dataset can improve generalization performance. Additionally, existing models trained with our dataset achieve state-of-the-art performance on image and text retrieval tasks. The source code and the dataset will be released after publication.
Granularity-aware Adaptation for Image Retrieval over Multiple Tasks
Oct 05, 2022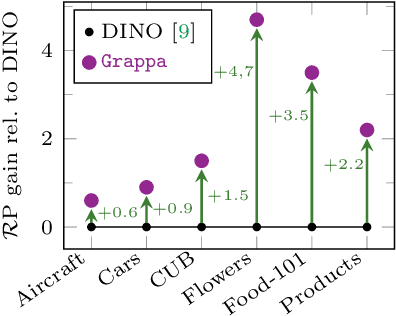
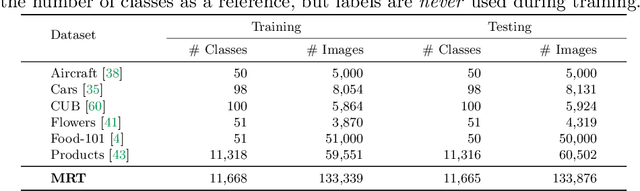
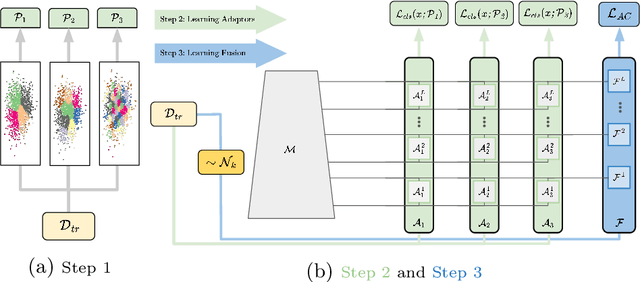
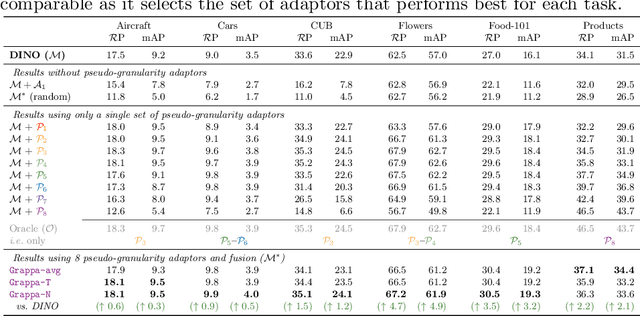
Strong image search models can be learned for a specific domain, ie. set of labels, provided that some labeled images of that domain are available. A practical visual search model, however, should be versatile enough to solve multiple retrieval tasks simultaneously, even if those cover very different specialized domains. Additionally, it should be able to benefit from even unlabeled images from these various retrieval tasks. This is the more practical scenario that we consider in this paper. We address it with the proposed Grappa, an approach that starts from a strong pretrained model, and adapts it to tackle multiple retrieval tasks concurrently, using only unlabeled images from the different task domains. We extend the pretrained model with multiple independently trained sets of adaptors that use pseudo-label sets of different sizes, effectively mimicking different pseudo-granularities. We reconcile all adaptor sets into a single unified model suited for all retrieval tasks by learning fusion layers that we guide by propagating pseudo-granularity attentions across neighbors in the feature space. Results on a benchmark composed of six heterogeneous retrieval tasks show that the unsupervised Grappa model improves the zero-shot performance of a state-of-the-art self-supervised learning model, and in some places reaches or improves over a task label-aware oracle that selects the most fitting pseudo-granularity per task.
Large-scale Bilingual Language-Image Contrastive Learning
Apr 15, 2022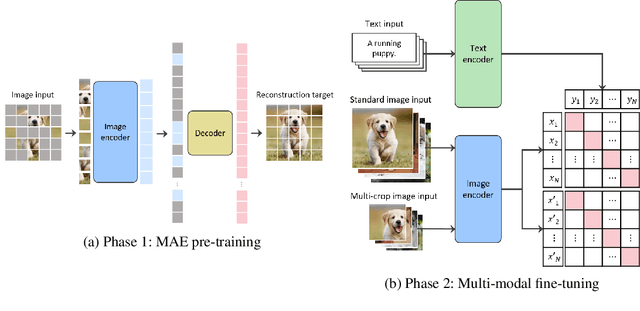

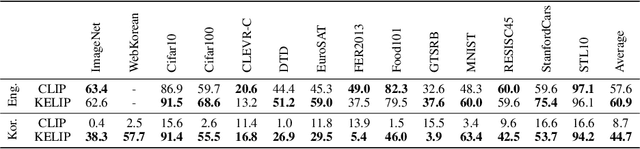
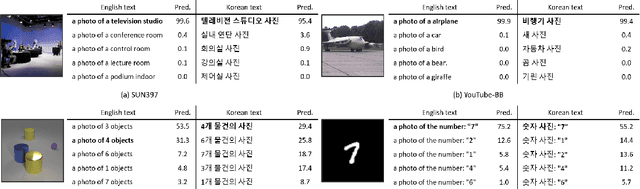
This paper is a technical report to share our experience and findings building a Korean and English bilingual multimodal model. While many of the multimodal datasets focus on English and multilingual multimodal research uses machine-translated texts, employing such machine-translated texts is limited to describing unique expressions, cultural information, and proper noun in languages other than English. In this work, we collect 1.1 billion image-text pairs (708 million Korean and 476 million English) and train a bilingual multimodal model named KELIP. We introduce simple yet effective training schemes, including MAE pre-training and multi-crop augmentation. Extensive experiments demonstrate that a model trained with such training schemes shows competitive performance in both languages. Moreover, we discuss multimodal-related research questions: 1) strong augmentation-based methods can distract the model from learning proper multimodal relations; 2) training multimodal model without cross-lingual relation can learn the relation via visual semantics; 3) our bilingual KELIP can capture cultural differences of visual semantics for the same meaning of words; 4) a large-scale multimodal model can be used for multimodal feature analogy. We hope that this work will provide helpful experience and findings for future research. We provide an open-source pre-trained KELIP.
Self-Distilled Hashing for Deep Image Retrieval
Dec 16, 2021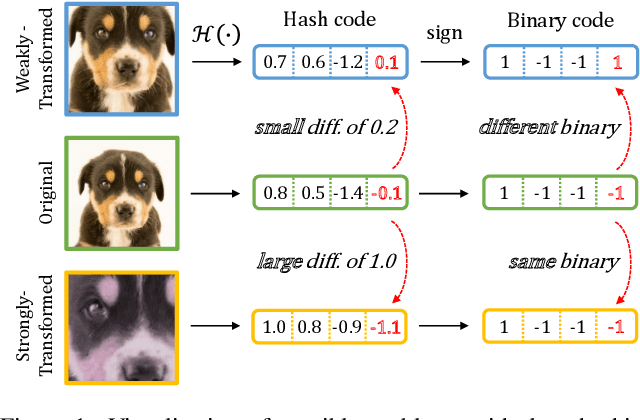

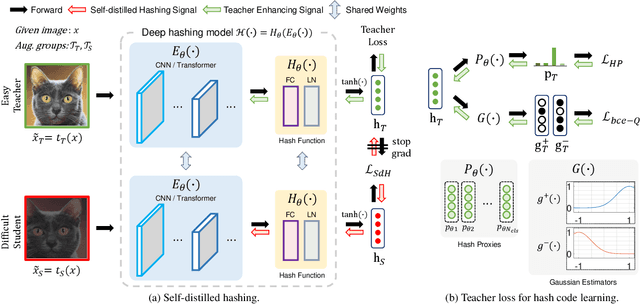

In hash-based image retrieval systems, the transformed input from the original usually generates different codes, deteriorating the retrieval accuracy. To mitigate this issue, data augmentation can be applied during training. However, even if the augmented samples of one content are similar in real space, the quantization can scatter them far away in Hamming space. This results in representation discrepancies that can impede training and degrade performance. In this work, we propose a novel self-distilled hashing scheme to minimize the discrepancy while exploiting the potential of augmented data. By transferring the hash knowledge of the weakly-transformed samples to the strong ones, we make the hash code insensitive to various transformations. We also introduce hash proxy-based similarity learning and binary cross entropy-based quantization loss to provide fine quality hash codes. Ultimately, we construct a deep hashing framework that generates discriminative hash codes. Extensive experiments on benchmarks verify that our self-distillation improves the existing deep hashing approaches, and our framework achieves state-of-the-art retrieval results. The code will be released soon.
Towards Real-time and Light-weight Line Segment Detection
Jun 01, 2021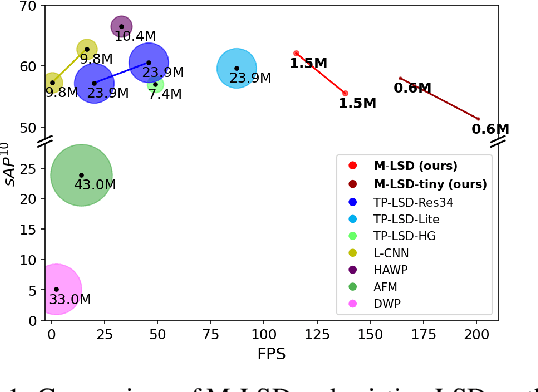
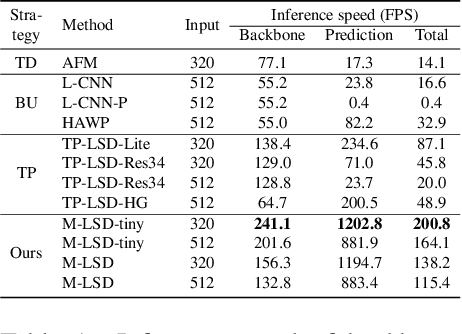
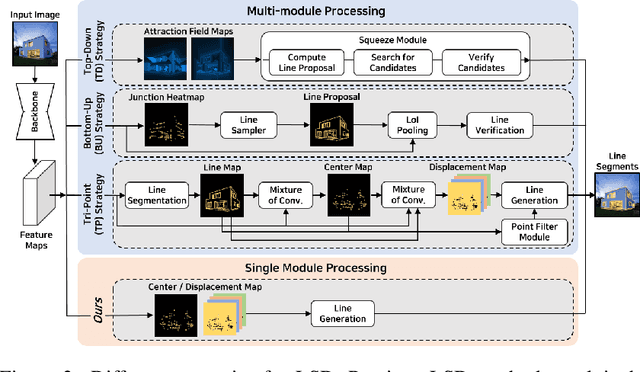
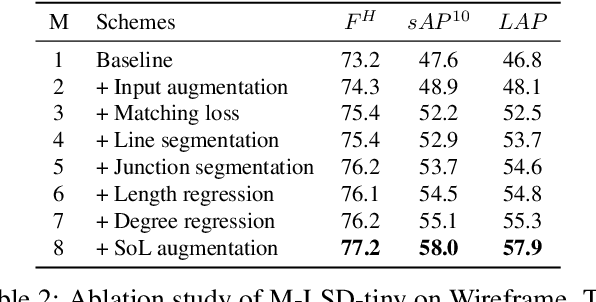
Previous deep learning-based line segment detection (LSD) suffer from the immense model size and high computational cost for line prediction. This constrains them from real-time inference on computationally restricted environments. In this paper, we propose a real-time and light-weight line segment detector for resource-constrained environments named Mobile LSD (M-LSD). We design an extremely efficient LSD architecture by minimizing the backbone network and removing the typical multi-module process for line prediction in previous methods. To maintain competitive performance with such a light-weight network, we present novel training schemes: Segments of Line segment (SoL) augmentation and geometric learning scheme. SoL augmentation splits a line segment into multiple subparts, which are used to provide auxiliary line data during the training process. Moreover, the geometric learning scheme allows a model to capture additional geometry cues from matching loss, junction and line segmentation, length and degree regression. Compared with TP-LSD-Lite, previously the best real-time LSD method, our model (M-LSD-tiny) achieves competitive performance with 2.5% of model size and an increase of 130.5% in inference speed on GPU when evaluated with Wireframe and YorkUrban datasets. Furthermore, our model runs at 56.8 FPS and 48.6 FPS on Android and iPhone mobile devices, respectively. To the best of our knowledge, this is the first real-time deep LSD method available on mobile devices.
RTIC: Residual Learning for Text and Image Composition using Graph Convolutional Network
Apr 08, 2021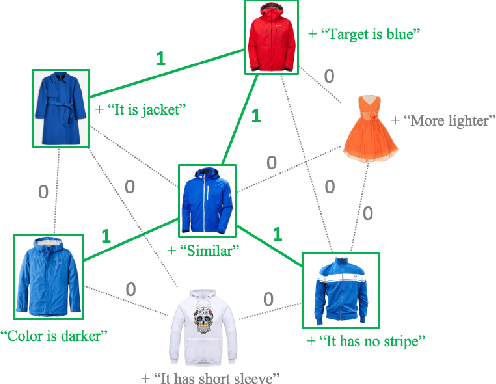
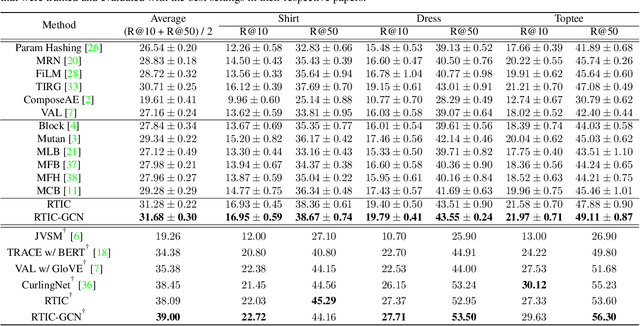
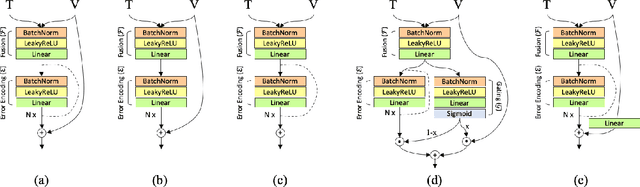

In this paper, we study the compositional learning of images and texts for image retrieval. The query is given in the form of an image and text that describes the desired modifications to the image; the goal is to retrieve the target image that satisfies the given modifications and resembles the query by composing information in both the text and image modalities. To accomplish this task, we propose a simple new architecture using skip connections that can effectively encode the errors between the source and target images in the latent space. Furthermore, we introduce a novel method that combines the graph convolutional network (GCN) with existing composition methods. We find that the combination consistently improves the performance in a plug-and-play manner. We perform thorough and exhaustive experiments on several widely used datasets, and achieve state-of-the-art scores on the task with our model. To ensure fairness in comparison, we suggest a strict standard for the evaluation because a small difference in the training conditions can significantly affect the final performance. We release our implementation, including that of all the compared methods, for reproducibility.