 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTIC: Residual Learning for Text and Image Composition using Graph Convolutional Network
Paper and Code
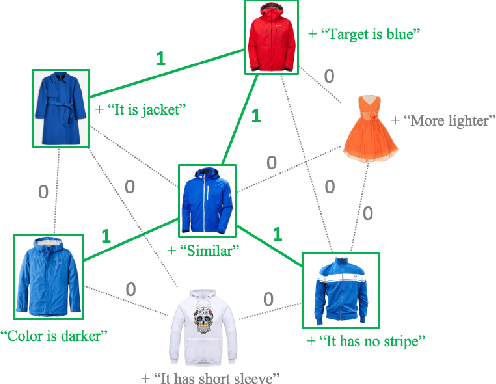
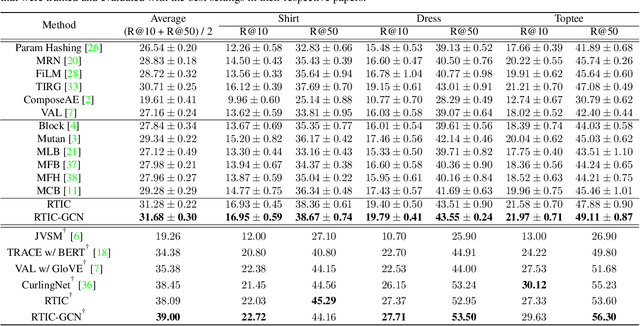
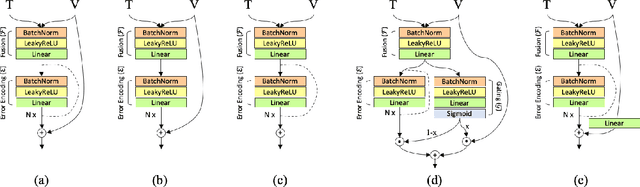

In this paper, we study the compositional learning of images and texts for image retrieval. The query is given in the form of an image and text that describes the desired modifications to the image; the goal is to retrieve the target image that satisfies the given modifications and resembles the query by composing information in both the text and image modalities. To accomplish this task, we propose a simple new architecture using skip connections that can effectively encode the errors between the source and target images in the latent space. Furthermore, we introduce a novel method that combines the graph convolutional network (GCN) with existing composition methods. We find that the combination consistently improves the performance in a plug-and-play manner. We perform thorough and exhaustive experiments on several widely used datasets, and achieve state-of-the-art scores on the task with our model. To ensure fairness in comparison, we suggest a strict standard for the evaluation because a small difference in the training conditions can significantly affect the final performance. We release our implementation, including that of all the compared methods, for reproducibility.