 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Gibbs Sampler for Efficient Bayesian Inference in Sign-Identified SVARs
May 29, 2025We develop a new algorithm for inference based on SVARs identified with sign restrictions. The key insight of our algorithm is to break apart from the accept-reject tradition associated with sign-identified SVARs. We show that embedding an elliptical slice sampling within a Gibbs sampler approach can deliver dramatic gains in speed and turn previously infeasible applications into feasible ones. We provide a tractable example to illustrate the power of the elliptical slice sampling applied to sign-identified SVARs. We demonstrate the usefulness of our algorithm by applying it to a well-known small-SVAR model of the oil market featuring a tight identified set as well as to large SVAR model with more than 100 sign restrictions.
MSTR: Multi-Scale Transformer for End-to-End Human-Object Interaction Detection
Mar 28, 2022
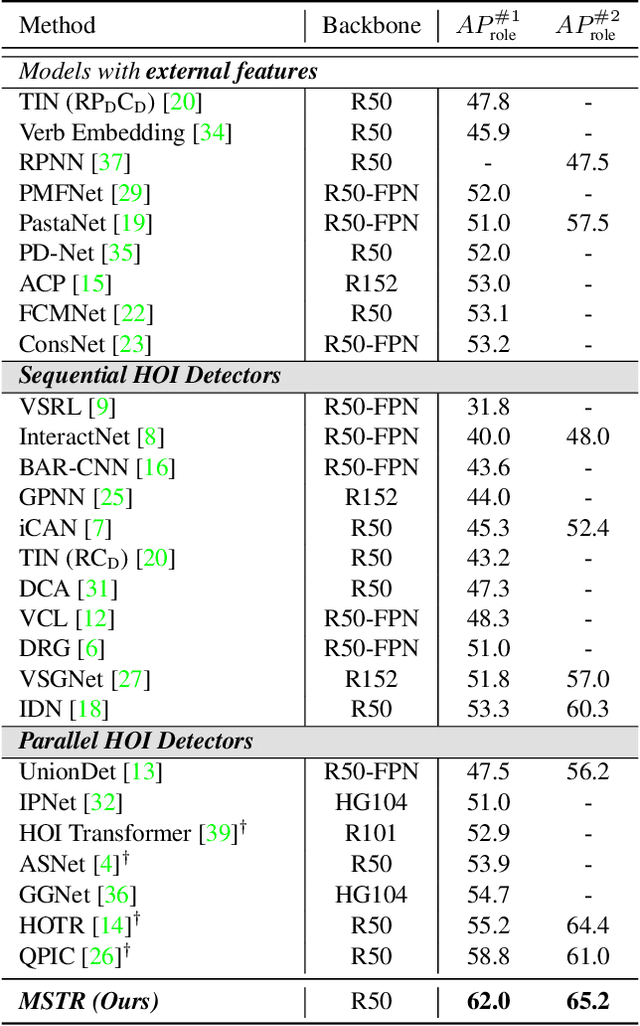
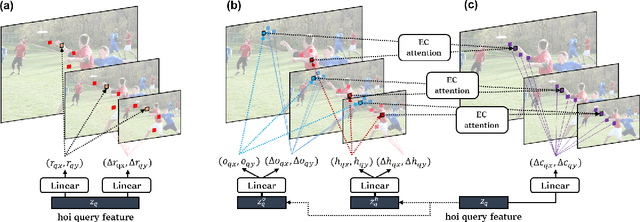
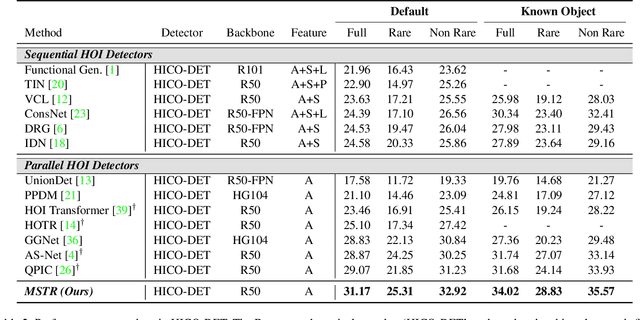
Human-Object Interaction (HOI) detection is the task of identifying a set of <human, object, interaction> triplets from an image. Recent work proposed transformer encoder-decoder architectures that successfully eliminated the need for many hand-designed components in HOI detection through end-to-end training. However, they are limited to single-scale feature resolution, providing suboptimal performance in scenes containing humans, objects and their interactions with vastly different scales and distances. To tackle this problem, we propose a Multi-Scale TRansformer (MSTR) for HOI detection powered by two novel HOI-aware deformable attention modules called Dual-Entity attention and Entity-conditioned Context attention. While existing deformable attention comes at a huge cost in HOI detection performance, our proposed attention modules of MSTR learn to effectively attend to sampling points that are essential to identify interactions. In experiments, we achieve the new state-of-the-art performance on two HOI detection benchmarks.
Multi-Modal Mixup for Robust Fine-tuning
Mar 08, 2022
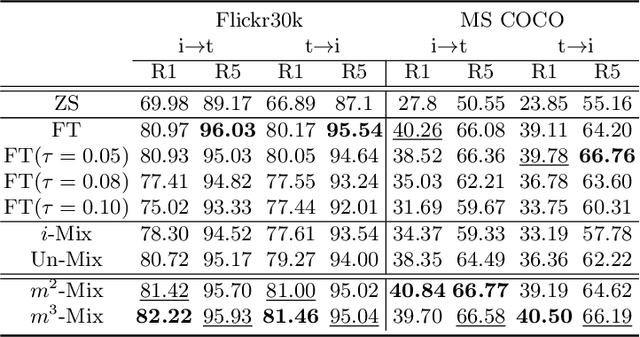


Pre-trained large-scale models provide a transferable embedding, and they show comparable performance on the diverse downstream task. However, the transferability of multi-modal learning is restricted, and the analysis of learned embedding has not been explored well. This paper provides a perspective to understand the multi-modal embedding in terms of uniformity and alignment. We newly find that the representation learned by multi-modal learning models such as CLIP has a two separated representation space for each heterogeneous dataset with less alignment. Besides, there are unexplored large intermediate areas between two modalities with less uniformity. Less robust embedding might restrict the transferability of the representation for the downstream task. This paper provides a new end-to-end fine-tuning method for robust representation that encourages better uniformity and alignment score. First, we propose a multi-modal Mixup, $m^{2}$-Mix that mixes the representation of image and text to generate the hard negative samples. Second, we fine-tune the multi-modal model on a hard negative sample as well as normal negative and positive samples with contrastive learning. Our multi-modal Mixup provides a robust representation, and we validate our methods on classification, retrieval, and structure-awareness task.
Boundary-aware Self-supervised Learning for Video Scene Segmentation
Jan 14, 2022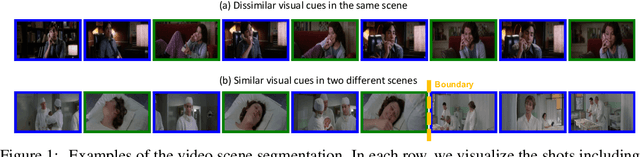
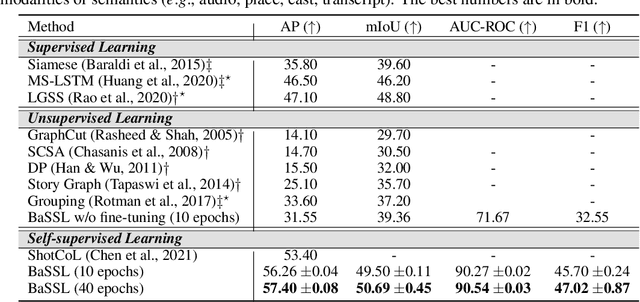
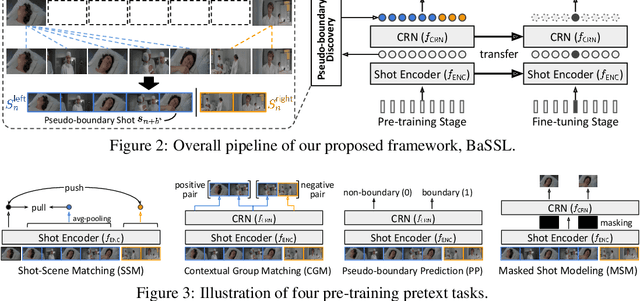
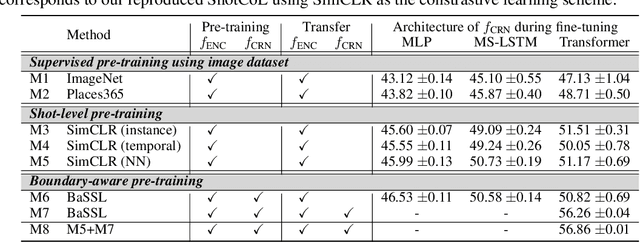
Self-supervised learning has drawn attention through its effectiveness in learning in-domain representations with no ground-truth annotations; in particular, it is shown that properly designed pretext tasks (e.g., contrastive prediction task) bring significant performance gains for downstream tasks (e.g., classification task). Inspired from this, we tackle video scene segmentation, which is a task of temporally localizing scene boundaries in a video, with a self-supervised learning framework where we mainly focus on designing effective pretext tasks. In our framework, we discover a pseudo-boundary from a sequence of shots by splitting it into two continuous, non-overlapping sub-sequences and leverage the pseudo-boundary to facilitate the pre-training. Based on this, we introduce three novel boundary-aware pretext tasks: 1) Shot-Scene Matching (SSM), 2) Contextual Group Matching (CGM) and 3) Pseudo-boundary Prediction (PP); SSM and CGM guide the model to maximize intra-scene similarity and inter-scene discrimination while PP encourages the model to identify transitional moments. Through comprehensive analysis, we empirically show that pre-training and transferring contextual representation are both critical to improving the video scene segmentation performance. Lastly, we achieve the new state-of-the-art on the MovieNet-SSeg benchmark. The code is available at https://github.com/kakaobrain/bassl.
Winning the ICCV'2021 VALUE Challenge: Task-aware Ensemble and Transfer Learning with Visual Concepts
Oct 13, 2021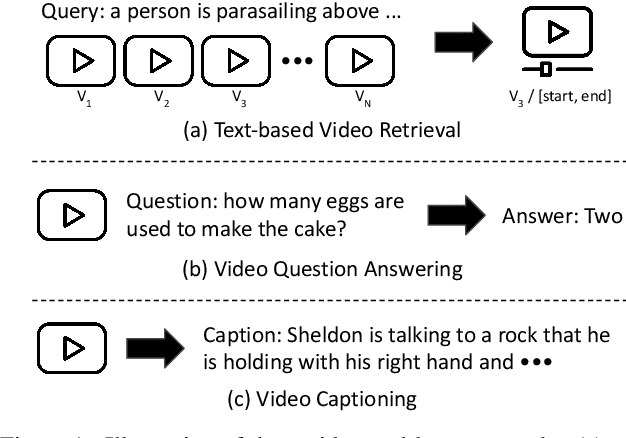

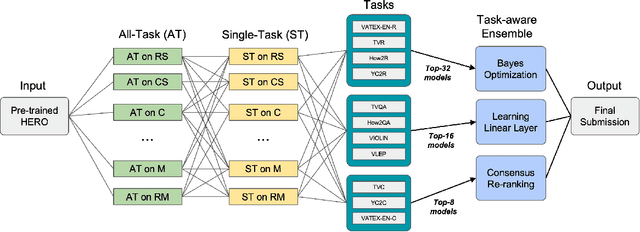
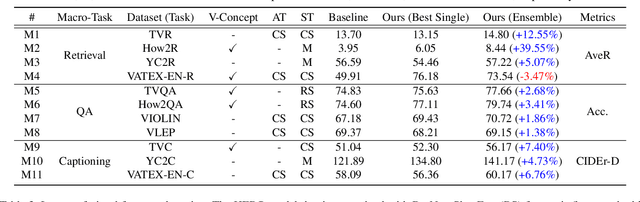
The VALUE (Video-And-Language Understanding Evaluation) benchmark is newly introduced to evaluate and analyze multi-modal representation learning algorithms on three video-and-language tasks: Retrieval, QA, and Captioning. The main objective of the VALUE challenge is to train a task-agnostic model that is simultaneously applicable for various tasks with different characteristics. This technical report describes our winning strategies for the VALUE challenge: 1) single model optimization, 2) transfer learning with visual concepts, and 3) task-aware ensemble. The first and third strategies are designed to address heterogeneous characteristics of each task, and the second one is to leverage rich and fine-grained visual information. We provide a detailed and comprehensive analysis with extensive experimental results. Based on our approach, we ranked first place on the VALUE and QA phases for the competition.
Towards Real-time and Light-weight Line Segment Detection
Jun 01, 2021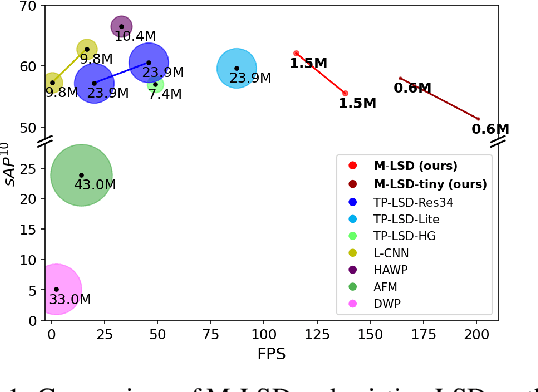
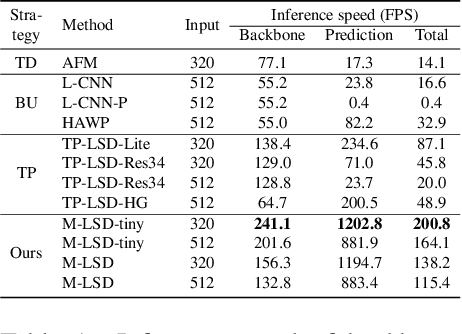
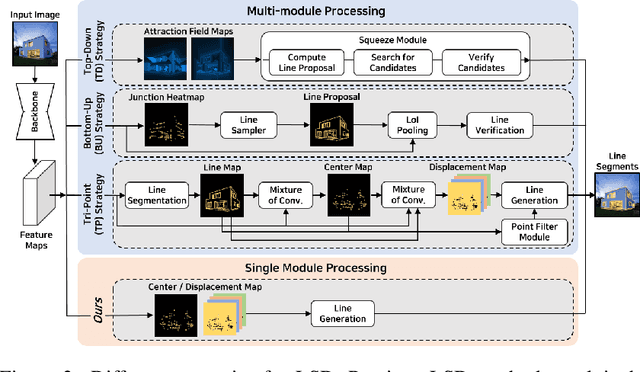
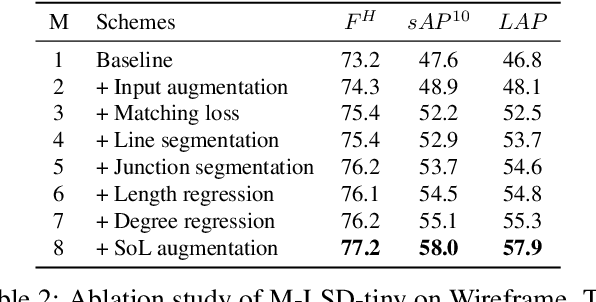
Previous deep learning-based line segment detection (LSD) suffer from the immense model size and high computational cost for line prediction. This constrains them from real-time inference on computationally restricted environments. In this paper, we propose a real-time and light-weight line segment detector for resource-constrained environments named Mobile LSD (M-LSD). We design an extremely efficient LSD architecture by minimizing the backbone network and removing the typical multi-module process for line prediction in previous methods. To maintain competitive performance with such a light-weight network, we present novel training schemes: Segments of Line segment (SoL) augmentation and geometric learning scheme. SoL augmentation splits a line segment into multiple subparts, which are used to provide auxiliary line data during the training process. Moreover, the geometric learning scheme allows a model to capture additional geometry cues from matching loss, junction and line segmentation, length and degree regression. Compared with TP-LSD-Lite, previously the best real-time LSD method, our model (M-LSD-tiny) achieves competitive performance with 2.5% of model size and an increase of 130.5% in inference speed on GPU when evaluated with Wireframe and YorkUrban datasets. Furthermore, our model runs at 56.8 FPS and 48.6 FPS on Android and iPhone mobile devices, respectively. To the best of our knowledge, this is the first real-time deep LSD method available on mobile devices.
RTIC: Residual Learning for Text and Image Composition using Graph Convolutional Network
Apr 08, 2021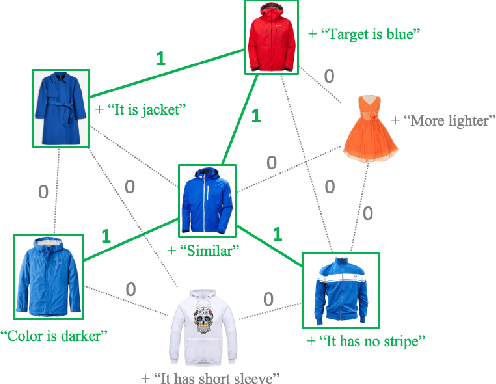
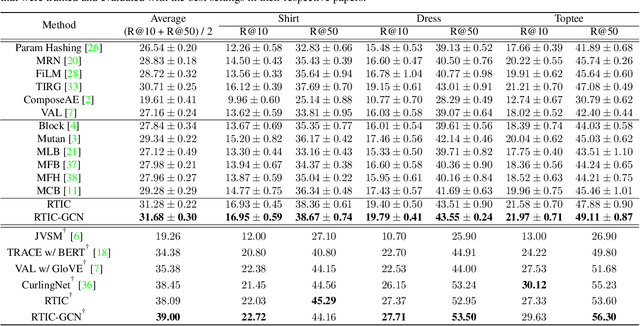
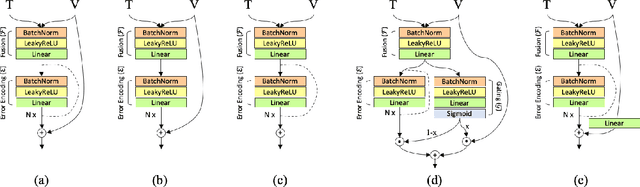

In this paper, we study the compositional learning of images and texts for image retrieval. The query is given in the form of an image and text that describes the desired modifications to the image; the goal is to retrieve the target image that satisfies the given modifications and resembles the query by composing information in both the text and image modalities. To accomplish this task, we propose a simple new architecture using skip connections that can effectively encode the errors between the source and target images in the latent space. Furthermore, we introduce a novel method that combines the graph convolutional network (GCN) with existing composition methods. We find that the combination consistently improves the performance in a plug-and-play manner. We perform thorough and exhaustive experiments on several widely used datasets, and achieve state-of-the-art scores on the task with our model. To ensure fairness in comparison, we suggest a strict standard for the evaluation because a small difference in the training conditions can significantly affect the final performance. We release our implementation, including that of all the compared methods, for reproducibility.
Semi-supervised Learning with a Teacher-student Network for Generalized Attribute Prediction
Jul 14, 2020



This paper presents a study on semi-supervised learning to solve the visual attribute prediction problem. In many applications of vision algorithms, the precise recognition of visual attributes of objects is important but still challenging. This is because defining a class hierarchy of attributes is ambiguous, so training data inevitably suffer from class imbalance and label sparsity, leading to a lack of effective annotations. An intuitive solution is to find a method to effectively learn image representations by utilizing unlabeled images. With that in mind, we propose a multi-teacher-single-student (MTSS) approach inspired by the multi-task learning and the distillation of semi-supervised learning. Our MTSS learns task-specific domain experts called teacher networks using the label embedding technique and learns a unified model called a student network by forcing a model to mimic the distributions learned by domain experts. Our experiments demonstrate that our method not only achieves competitive performance on various benchmarks for fashion attribute prediction, but also improves robustness and cross-domain adaptability for unseen domains.
Fashion-IQ 2020 Challenge 2nd Place Team's Solution
Jul 13, 2020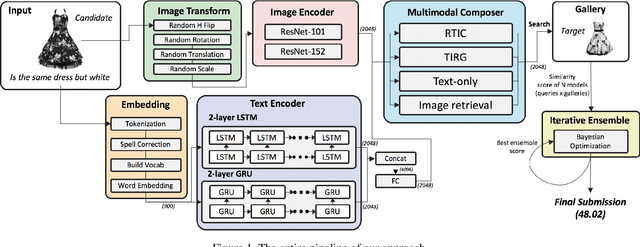
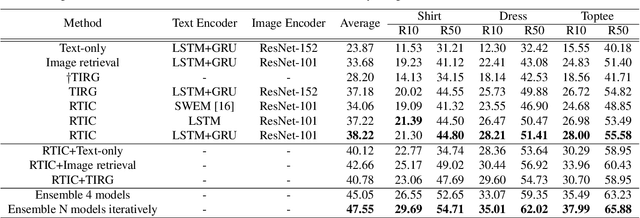
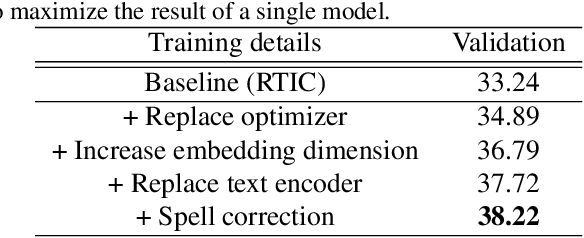

This paper is dedicated to team VAA's approach submitted to the Fashion-IQ challenge in CVPR 2020. Given a pair of the image and the text, we present a novel multimodal composition method, RTIC, that can effectively combine the text and the image modalities into a semantic space. We extract the image and the text features that are encoded by the CNNs and the sequential models (e.g., LSTM or GRU), respectively. To emphasize the meaning of the residual of the feature between the target and candidate, the RTIC is composed of N-blocks with channel-wise attention modules. Then, we add the encoded residual to the feature of the candidate image to obtain a synthesized feature. We also explored an ensemble strategy with variants of models and achieved a significant boost in performance comparing to the best single model. Finally, our approach achieved 2nd place in the Fashion-IQ 2020 Challenge with a test score of 48.02 on the leaderboard.
A Benchmark on Tricks for Large-scale Image Retrieval
Jul 27, 2019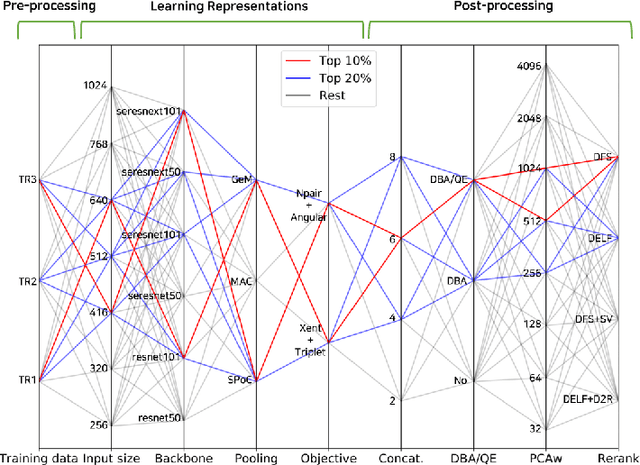
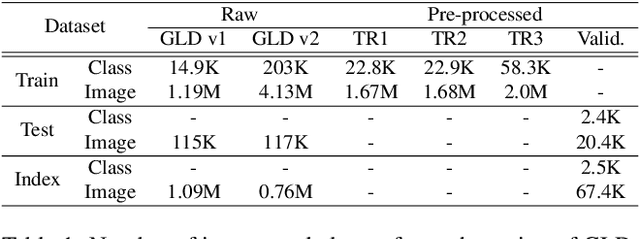

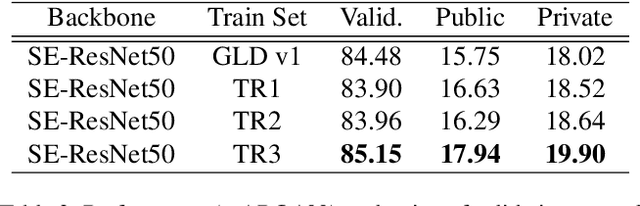
Many studies have been performed on metric learning, which has become a key ingredient in top-performing methods of instance-level image retrieval. Meanwhile, less attention has been paid to pre-processing and post-processing tricks that can significantly boost performance. Furthermore, we found that most previous studies used small scale datasets to simplify processing. Because the behavior of a feature representation in a deep learning model depends on both domain and data, it is important to understand how model behave in large-scale environments when a proper combination of retrieval tricks is used. In this paper, we extensively analyze the effect of well-known pre-processing, post-processing tricks, and their combination for large-scale image retrieval. We found that proper use of these tricks can significantly improve model performance without necessitating complex architecture or introducing loss, as confirmed by achieving a competitive result on the Google Landmark Retrieval Challenge 2019.