 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark on Tricks for Large-scale Image Retrieval
Paper and Code
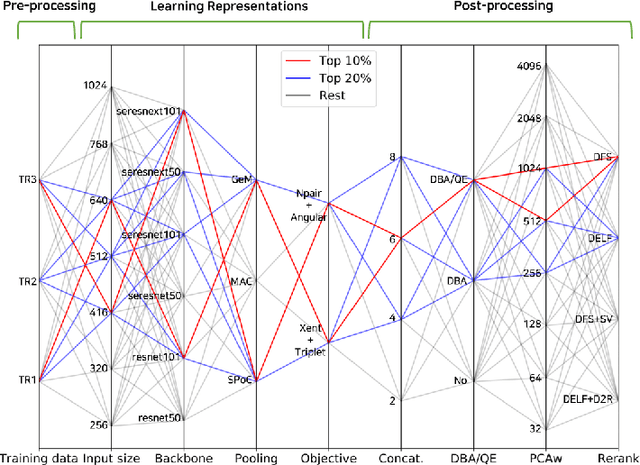
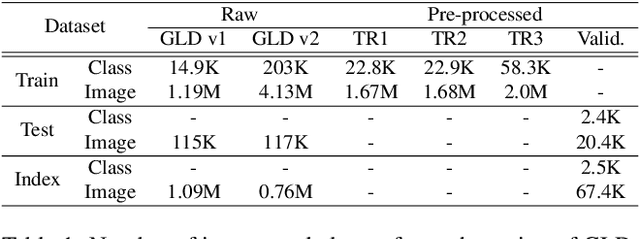

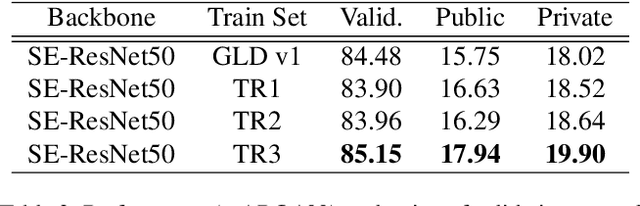
Many studies have been performed on metric learning, which has become a key ingredient in top-performing methods of instance-level image retrieval. Meanwhile, less attention has been paid to pre-processing and post-processing tricks that can significantly boost performance. Furthermore, we found that most previous studies used small scale datasets to simplify processing. Because the behavior of a feature representation in a deep learning model depends on both domain and data, it is important to understand how model behave in large-scale environments when a proper combination of retrieval tricks is used. In this paper, we extensively analyze the effect of well-known pre-processing, post-processing tricks, and their combination for large-scale image retrieval. We found that proper use of these tricks can significantly improve model performance without necessitating complex architecture or introducing loss, as confirmed by achieving a competitive result on the Google Landmark Retrieval Challenge 2019.