 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuCo: Multi-turn Contrastive Learning for Multimodal Embedding Model
Feb 06, 2026Universal Multimodal embedding models built on Multimodal Large Language Models (MLLMs) have traditionally employed contrastive learning, which aligns representations of query-target pairs across different modalities. Yet, despite its empirical success, they are primarily built on a "single-turn" formulation where each query-target pair is treated as an independent data point. This paradigm leads to computational inefficiency when scaling, as it requires a separate forward pass for each pair and overlooks potential contextual relationships between multiple queries that can relate to the same context. In this work, we introduce Multi-Turn Contrastive Learning (MuCo), a dialogue-inspired framework that revisits this process. MuCo leverages the conversational nature of MLLMs to process multiple, related query-target pairs associated with a single image within a single forward pass. This allows us to extract a set of multiple query and target embeddings simultaneously, conditioned on a shared context representation, amplifying the effective batch size and overall training efficiency. Experiments exhibit MuCo with a newly curated 5M multimodal multi-turn dataset (M3T), which yields state-of-the-art retrieval performance on MMEB and M-BEIR benchmarks, while markedly enhancing both training efficiency and representation coherence across modalities. Code and M3T are available at https://github.com/naver-ai/muco
CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion
Mar 21, 2023This paper proposes a novel diffusion-based model, CompoDiff, for solving Composed Image Retrieval (CIR) with latent diffusion and presents a newly created dataset of 18 million reference images, conditions, and corresponding target image triplets to train the model. CompoDiff not only achieves a new zero-shot state-of-the-art on a CIR benchmark such as FashionIQ but also enables a more versatile CIR by accepting various conditions, such as negative text and image mask conditions, which are unavailable with existing CIR methods. In addition, the CompoDiff features are on the intact CLIP embedding space so that they can be directly used for all existing models exploiting the CLIP space. The code and dataset used for the training, and the pre-trained weights are available at https://github.com/navervision/CompoDiff
An Effective Pipeline for a Real-world Clothes Retrieval System
May 26, 2020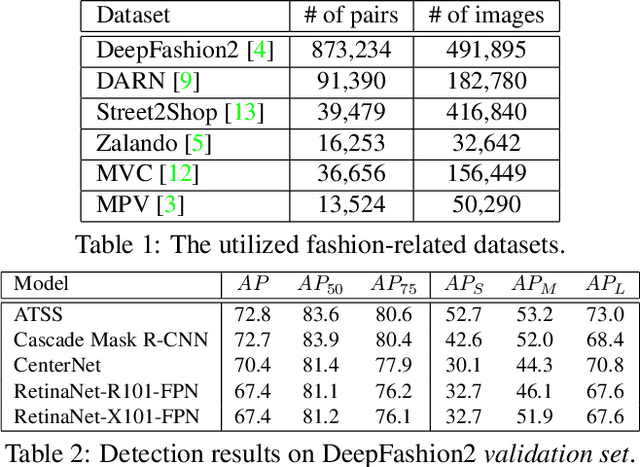

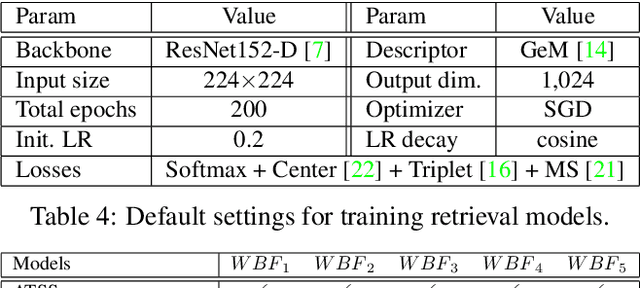
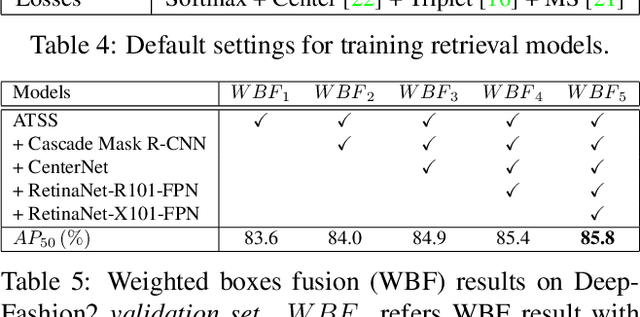
In this paper, we propose an effective pipeline for clothes retrieval system which has sturdiness on large-scale real-world fashion data. Our proposed method consists of three components: detection, retrieval, and post-processing. We firstly conduct a detection task for precise retrieval on target clothes, then retrieve the corresponding items with the metric learning-based model. To improve the retrieval robustness against noise and misleading bounding boxes, we apply post-processing methods such as weighted boxes fusion and feature concatenation. With the proposed methodology, we achieved 2nd place in the DeepFashion2 Clothes Retrieval 2020 challenge.
A Benchmark on Tricks for Large-scale Image Retrieval
Jul 27, 2019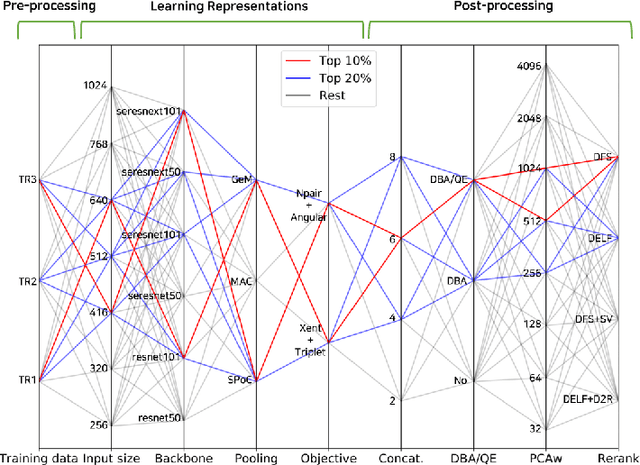
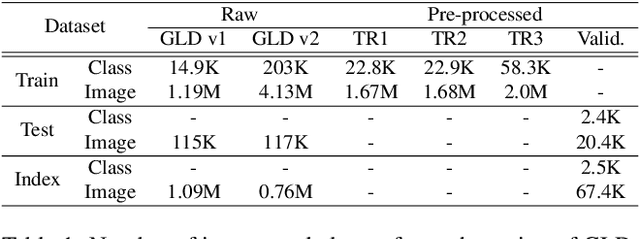

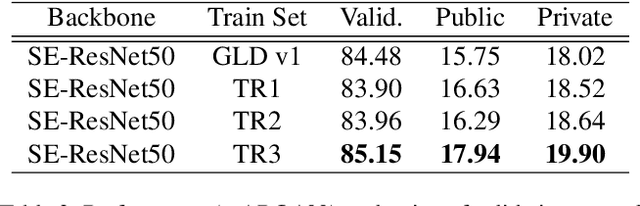
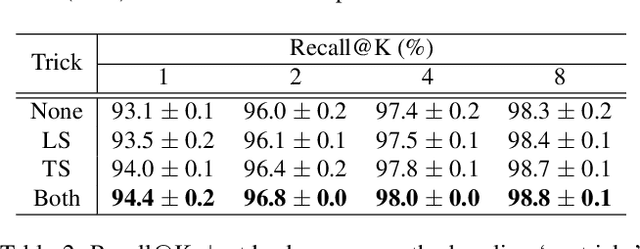
Many studies have been performed on metric learning, which has become a key ingredient in top-performing methods of instance-level image retrieval. Meanwhile, less attention has been paid to pre-processing and post-processing tricks that can significantly boost performance. Furthermore, we found that most previous studies used small scale datasets to simplify processing. Because the behavior of a feature representation in a deep learning model depends on both domain and data, it is important to understand how model behave in large-scale environments when a proper combination of retrieval tricks is used. In this paper, we extensively analyze the effect of well-known pre-processing, post-processing tricks, and their combination for large-scale image retrieval. We found that proper use of these tricks can significantly improve model performance without necessitating complex architecture or introducing loss, as confirmed by achieving a competitive result on the Google Landmark Retrieval Challenge 2019.
Combination of Multiple Global Descriptors for Image Retrieval
Mar 26, 2019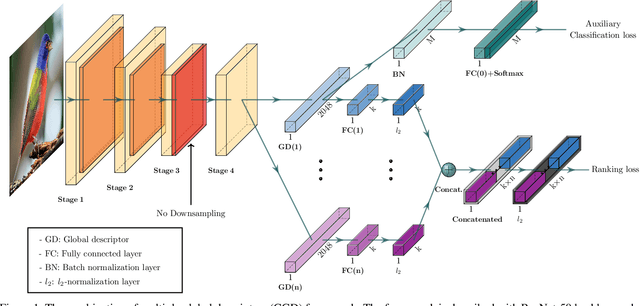

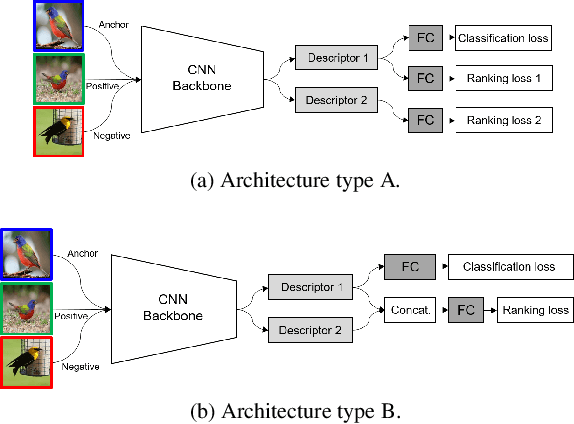
Recent studies in image retrieval task have shown that ensembling different models and combining multiple global descriptors lead to performance improvement. However, training different models for ensemble is not only difficult but also inefficient with respect to time or memory. In this paper, we propose a novel framework that exploits multiple global descriptors to get an ensemble-like effect while it can be trained in an end-to-end manner. The proposed framework is flexible and expandable by the global descriptor, CNN backbone, loss, and dataset. Moreover, we investigate the effectiveness of combining multiple global descriptors with quantitative and qualitative analysis. Our extensive experiments show that the combined descriptor outperforms a single global descriptor, as it can utilize different types of feature properties. In the benchmark evaluation, the proposed framework achieves the state-of-the-art performance on the CARS196, CUB200-2011, In-shop Clothes and Stanford Online Products on image retrieval tasks by a large margin compared to competing approaches.