 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxisGuide: Grounding Robot Action Coordinate System in RGB Observations for Robust Visuomotor Manipulation
Jun 04, 2026Visuomotor manipulation policies trained via large-scale behavior cloning have achieved strong semantic scene understanding, yet often fail to reliably execute correct low-level actions under distribution shifts. For example, even in a simple pickup task with identical scene layouts, camera viewpoints, and illumination, performance can degrade substantially when the object is placed at unseen locations. We argue that this gap arises from insufficient action understanding, namely the inability to interpret the robot's base-frame action coordinate system in image space. To address this issue, we introduce AxisGuide, a lightweight guidance method that bridges semantic scene understanding and action-coordinate interpretation. Using camera parameters and end-effector poses, AxisGuide renders the robot base-frame axes in each camera view and augments RGB observations with a small set of cue channels that explicitly visualize the meaning of the +x, +y, and +z motions in image space. Extensive evaluations in both the LIBERO simulation and real-world environments demonstrate that AxisGuide yields substantial performance gains and improved generalization, highlighting the effectiveness of explicit action-coordinate cues for learning reliable and transferable generalist visuomotor policies.
Data augmentation using diffusion models to enhance inverse Ising inference
Mar 13, 2025Identifying model parameters from observed configurations poses a fundamental challenge in data science, especially with limited data. Recently, diffusion models have emerged as a novel paradigm in generative machine learning, capable of producing new samples that closely mimic observed data. These models learn the gradient of model probabilities, bypassing the need for cumbersome calculations of partition functions across all possible configurations. We explore whether diffusion models can enhance parameter inference by augmenting small datasets. Our findings demonstrate this potential through a synthetic task involving inverse Ising inference and a real-world application of reconstructing missing values in neural activity data. This study serves as a proof-of-concept for using diffusion models for data augmentation in physics-related problems, thereby opening new avenues in data science.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Bayesian Structural Model Updating with Multimodal Variational Autoencoder
Jun 20, 2024



A novel framework for Bayesian structural model updating is presented in this study. The proposed method utilizes the surrogate unimodal encoders of a multimodal variational autoencoder (VAE). The method facilitates an approximation of the likelihood when dealing with a small number of observations. It is particularly suitable for high-dimensional correlated simultaneous observations applicable to various dynamic analysis models. The proposed approach was benchmarked using a numerical model of a single-story frame building with acceleration and dynamic strain measurements. Additionally, an example involving a Bayesian update of nonlinear model parameters for a three-degree-of-freedom lumped mass model demonstrates computational efficiency when compared to using the original VAE, while maintaining adequate accuracy for practical applications.
* 44 pages, 21 figures
Emotion Recognition Using Transformers with Masked Learning
Mar 23, 2024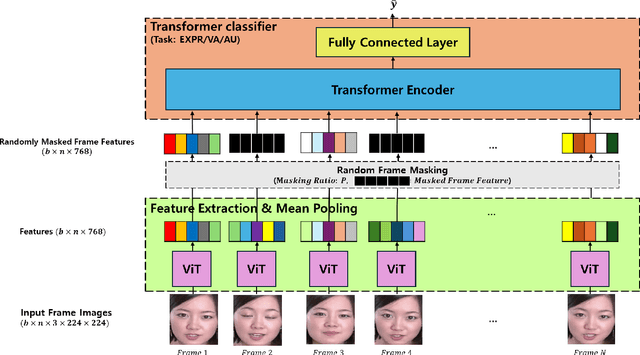
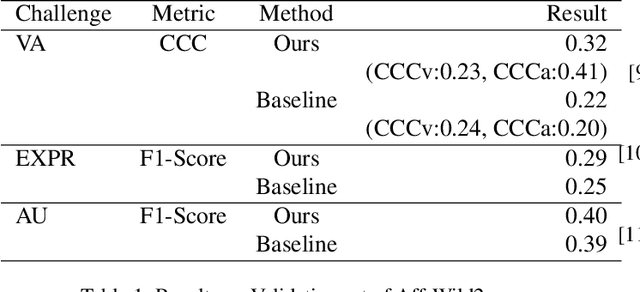
In recent years, deep learning has achieved innovative advancements in various fields, including the analysis of human emotions and behaviors. Initiatives such as the Affective Behavior Analysis in-the-wild (ABAW) competition have been particularly instrumental in driving research in this area by providing diverse and challenging datasets that enable precise evaluation of complex emotional states. This study leverages the Vision Transformer (ViT) and Transformer models to focus on the estimation of Valence-Arousal (VA), which signifies the positivity and intensity of emotions, recognition of various facial expressions, and detection of Action Units (AU) representing fundamental muscle movements. This approach transcends traditional Convolutional Neural Networks (CNNs) and Long Short-Term Memory (LSTM) based methods, proposing a new Transformer-based framework that maximizes the understanding of temporal and spatial features. The core contributions of this research include the introduction of a learning technique through random frame masking and the application of Focal loss adapted for imbalanced data, enhancing the accuracy and applicability of emotion and behavior analysis in real-world settings. This approach is expected to contribute to the advancement of emotional computing and deep learning methodologies.
Optimizing Base Placement of Surgical Robot: Kinematics Data-Driven Approach by Analyzing Working Pattern
Feb 25, 2024In robot-assisted minimally invasive surgery (RAMIS), optimal placement of the surgical robot's base is crucial for successful surgery. Improper placement can hinder performance due to manipulator limitations and inaccessible workspaces. Traditionally, trained medical staff rely on experience for base placement, but this approach lacks objectivity. This paper proposes a novel method to determine the optimal base pose based on the individual surgeon's working pattern. The proposed method analyzes recorded end-effector poses using machine-learning based clustering technique to identify key positions and orientations preferred by the surgeon. To address joint limits and singularities problems, we introduce two scoring metrics: joint margin score and manipulability score. We then train a multi-layer perceptron (MLP) regressor to predict the optimal base pose based on these scores. Evaluation in a simulated environment using the da Vinci Research Kit (dVRK) showed unique base pose-score maps for four volunteers, highlighting the individuality of working patterns. After conducting tests on the base poses identified using the proposed method, we confirmed that they have a score approximately 28.2\% higher than when the robots were placed randomly, with respect to the score we defined. This emphasizes the need for operator-specific optimization in RAMIS base placement.
Failure Tolerant Training with Persistent Memory Disaggregation over CXL
Jan 20, 2023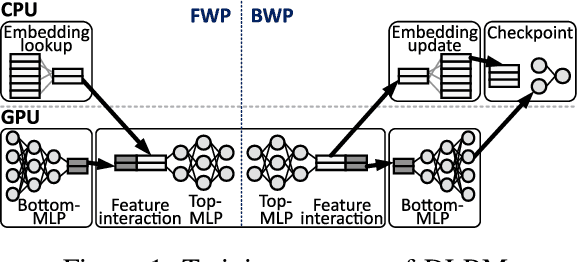

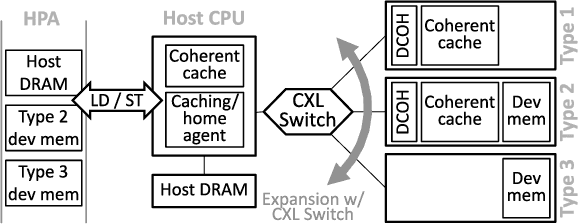

This paper proposes TRAININGCXL that can efficiently process large-scale recommendation datasets in the pool of disaggregated memory while making training fault tolerant with low overhead. To this end, i) we integrate persistent memory (PMEM) and GPU into a cache-coherent domain as Type-2. Enabling CXL allows PMEM to be directly placed in GPU's memory hierarchy, such that GPU can access PMEM without software intervention. TRAININGCXL introduces computing and checkpointing logic near the CXL controller, thereby training data and managing persistency in an active manner. Considering PMEM's vulnerability, ii) we utilize the unique characteristics of recommendation models and take the checkpointing overhead off the critical path of their training. Lastly, iii) TRAININGCXL employs an advanced checkpointing technique that relaxes the updating sequence of model parameters and embeddings across training batches. The evaluation shows that TRAININGCXL achieves 5.2x training performance improvement and 76% energy savings, compared to the modern PMEM-based recommendation systems.
Hardware/Software Co-Programmable Framework for Computational SSDs to Accelerate Deep Learning Service on Large-Scale Graphs
Jan 23, 2022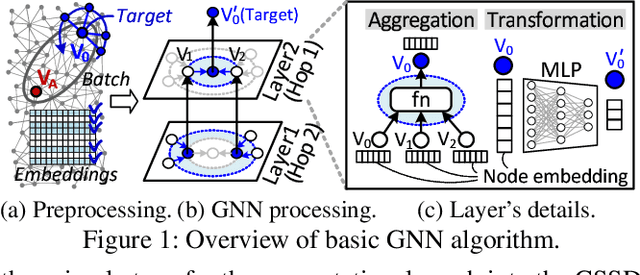

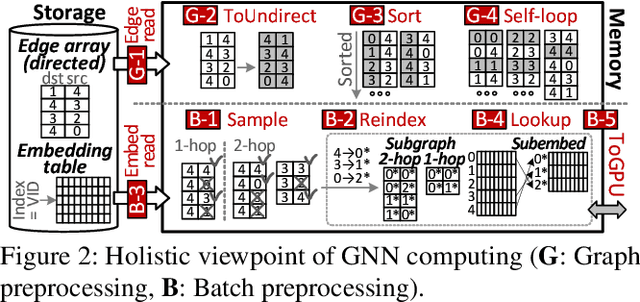

Graph neural networks (GNNs) process large-scale graphs consisting of a hundred billion edges. In contrast to traditional deep learning, unique behaviors of the emerging GNNs are engaged with a large set of graphs and embedding data on storage, which exhibits complex and irregular preprocessing. We propose a novel deep learning framework on large graphs, HolisticGNN, that provides an easy-to-use, near-storage inference infrastructure for fast, energy-efficient GNN processing. To achieve the best end-to-end latency and high energy efficiency, HolisticGNN allows users to implement various GNN algorithms and directly executes them where the actual data exist in a holistic manner. It also enables RPC over PCIe such that the users can simply program GNNs through a graph semantic library without any knowledge of the underlying hardware or storage configurations. We fabricate HolisticGNN's hardware RTL and implement its software on an FPGA-based computational SSD (CSSD). Our empirical evaluations show that the inference time of HolisticGNN outperforms GNN inference services using high-performance modern GPUs by 7.1x while reducing energy consumption by 33.2x, on average.
Inference of stochastic time series with missing data
Jan 28, 2021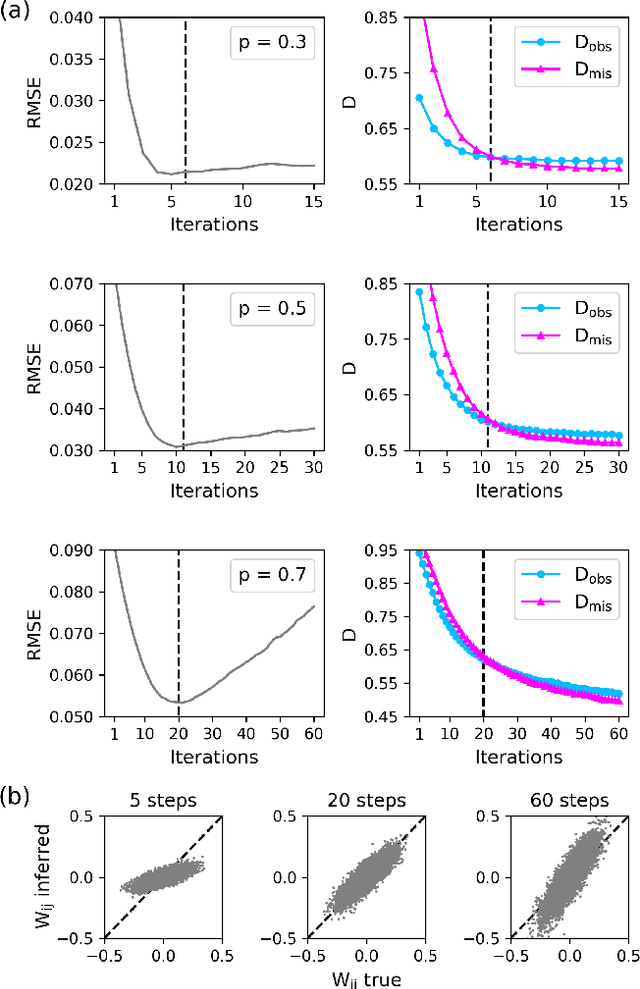
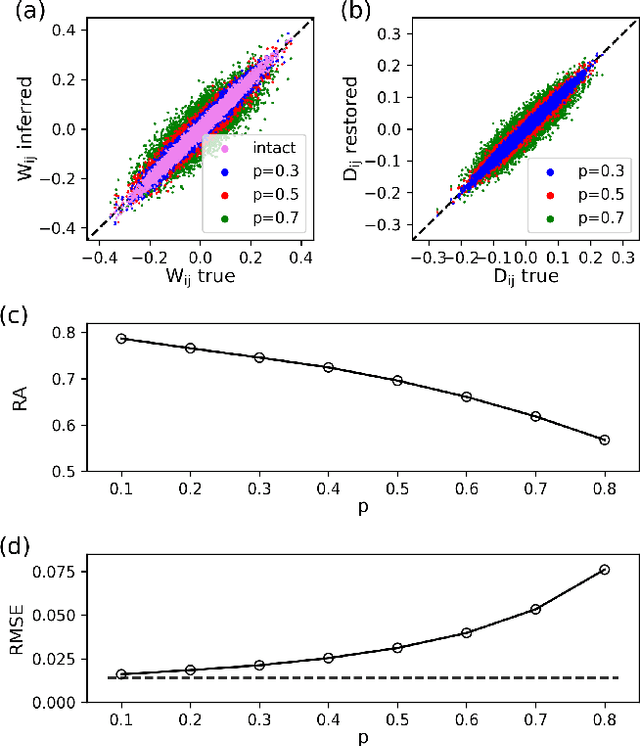
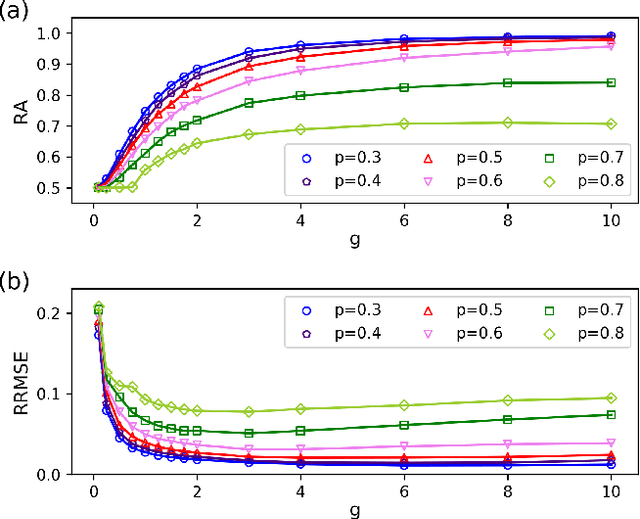
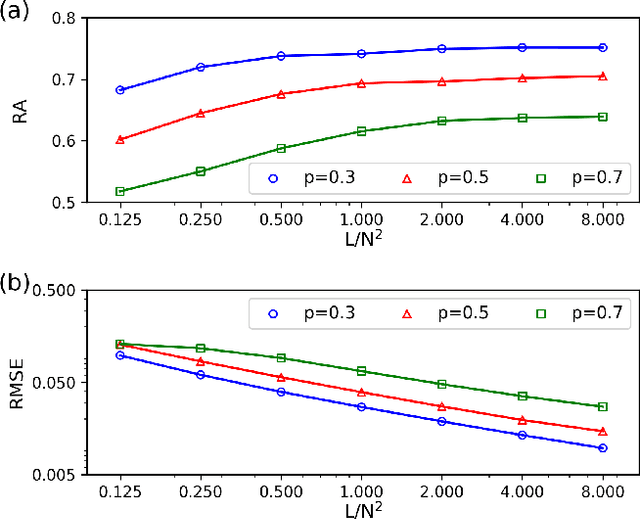
Inferring dynamics from time series is an important objective in data analysis. In particular, it is challenging to infer stochastic dynamics given incomplete data. We propose an expectation maximization (EM) algorithm that iterates between alternating two steps: E-step restores missing data points, while M-step infers an underlying network model of restored data. Using synthetic data generated by a kinetic Ising model, we confirm that the algorithm works for restoring missing data points as well as inferring the underlying model. At the initial iteration of the EM algorithm, the model inference shows better model-data consistency with observed data points than with missing data points. As we keep iterating, however, missing data points show better model-data consistency. We find that demanding equal consistency of observed and missing data points provides an effective stopping criterion for the iteration to prevent overshooting the most accurate model inference. Armed with this EM algorithm with this stopping criterion, we infer missing data points and an underlying network from a time-series data of real neuronal activities. Our method recovers collective properties of neuronal activities, such as time correlations and firing statistics, which have previously never been optimized to fit.
An Effective Pipeline for a Real-world Clothes Retrieval System
May 26, 2020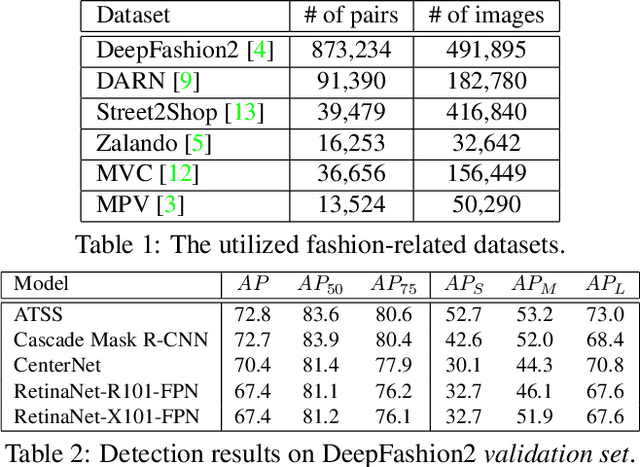

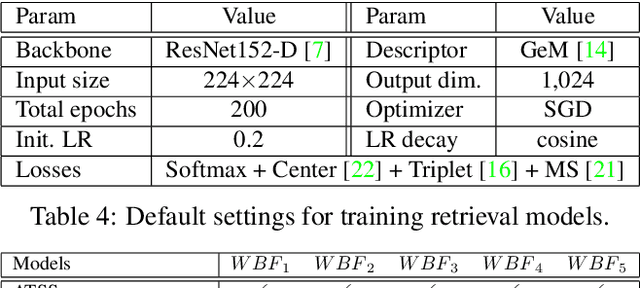
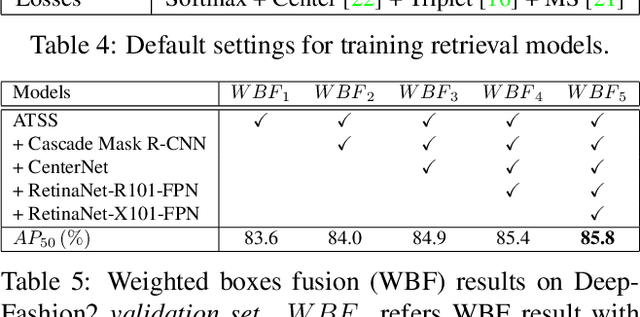
In this paper, we propose an effective pipeline for clothes retrieval system which has sturdiness on large-scale real-world fashion data. Our proposed method consists of three components: detection, retrieval, and post-processing. We firstly conduct a detection task for precise retrieval on target clothes, then retrieve the corresponding items with the metric learning-based model. To improve the retrieval robustness against noise and misleading bounding boxes, we apply post-processing methods such as weighted boxes fusion and feature concatenation. With the proposed methodology, we achieved 2nd place in the DeepFashion2 Clothes Retrieval 2020 challenge.