 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance-aware Soft Prompt Learning for Multimodal Valence-Arousal Estimation
Mar 12, 2026Valence-arousal (VA) estimation is crucial for capturing the nuanced nature of human emotions in naturalistic environments. While pre-trained Vision-Language models like CLIP have shown remarkable semantic alignment capabilities, their application in continuous regression tasks is often limited by the discrete nature of text prompts. In this paper, we propose a novel multimodal framework for VA estimation that introduces Distance-aware Soft Prompt Learning to bridge the gap between semantic space and continuous dimensions. Specifically, we partition the VA space into a 3X3 grid, defining nine emotional regions, each associated with distinct textual descriptions. Rather than a hard categorization, we employ a Gaussian kernel to compute soft labels based on the Euclidean distance between the ground truth coordinates and the region centers, allowing the model to learn fine-grained emotional transitions. For multimodal integration, our architecture utilizes a CLIP image encoder and an Audio Spectrogram Transformer (AST) to extract robust spatial and acoustic features. These features are temporally modeled via Gated Recurrent Units (GRUs) and integrated through a hierarchical fusion scheme that sequentially combines cross-modal attention for alignment and gated fusion for adaptive refinement. Experimental results on the Aff-Wild2 dataset demonstrate that our proposed semantic-guided approach significantly enhances the accuracy of VA estimation, achieving competitive performance in unconstrained ``in-the-wild'' scenarios.
Multimodal Emotion Recognition via Bi-directional Cross-Attention and Temporal Modeling
Mar 12, 2026Emotion recognition in in-the-wild video data remains a challenging problem due to large variations in facial appearance, head pose, illumination, background noise, and the inherently dynamic nature of human affect. Relying on a single modality, such as facial expressions or speech, is often insufficient to capture these complex emotional cues. To address this issue, we propose a multimodal emotion recognition framework for the Expression (EXPR) Recognition task in the 10th Affective Behavior Analysis in-the-wild (ABAW) Challenge. Our approach leverages large-scale pre-trained models, namely CLIP for visual encoding and Wav2Vec 2.0 for audio representation learning, as frozen backbone networks. To model temporal dependencies in facial expression sequences, we employ a Temporal Convolutional Network (TCN) over fixed-length video windows. In addition, we introduce a bi-directional cross-attention fusion module, in which visual and audio features interact symmetrically to enhance cross-modal contextualization and capture complementary emotional information. A lightweight classification head is then used for final emotion prediction. We further incorporate a text-guided contrastive objective based on CLIP text features to encourage semantically aligned visual representations. Experimental results on the ABAW 10th EXPR benchmark show that the proposed framework provides a strong multimodal baseline and achieves improved performance over unimodal modeling. These results demonstrate the effectiveness of combining temporal visual modeling, audio representation learning, and cross-modal fusion for robust emotion recognition in unconstrained real-world environments.
Emotion Recognition Using Transformers with Masked Learning
Mar 23, 2024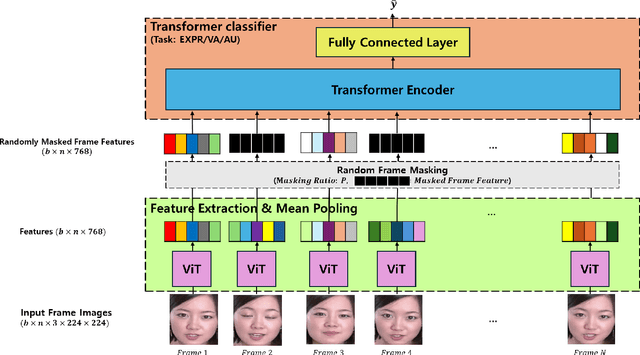
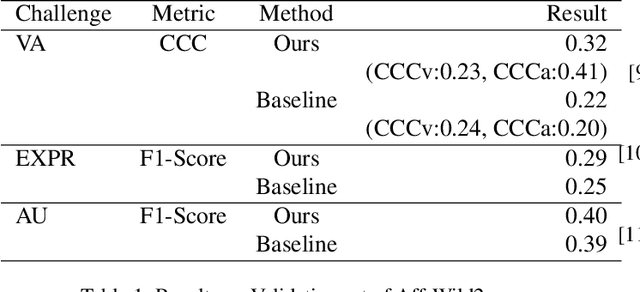
In recent years, deep learning has achieved innovative advancements in various fields, including the analysis of human emotions and behaviors. Initiatives such as the Affective Behavior Analysis in-the-wild (ABAW) competition have been particularly instrumental in driving research in this area by providing diverse and challenging datasets that enable precise evaluation of complex emotional states. This study leverages the Vision Transformer (ViT) and Transformer models to focus on the estimation of Valence-Arousal (VA), which signifies the positivity and intensity of emotions, recognition of various facial expressions, and detection of Action Units (AU) representing fundamental muscle movements. This approach transcends traditional Convolutional Neural Networks (CNNs) and Long Short-Term Memory (LSTM) based methods, proposing a new Transformer-based framework that maximizes the understanding of temporal and spatial features. The core contributions of this research include the introduction of a learning technique through random frame masking and the application of Focal loss adapted for imbalanced data, enhancing the accuracy and applicability of emotion and behavior analysis in real-world settings. This approach is expected to contribute to the advancement of emotional computing and deep learning methodologies.
PU-MFA : Point Cloud Up-sampling via Multi-scale Features Attention
Aug 22, 2022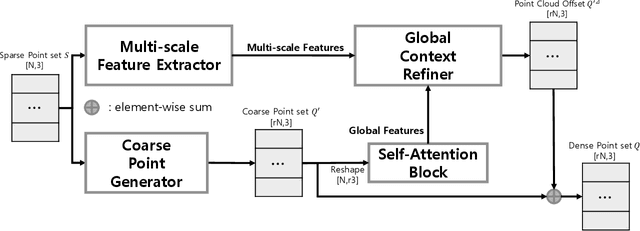

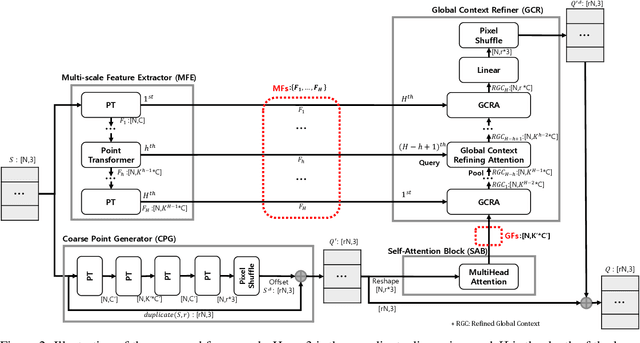
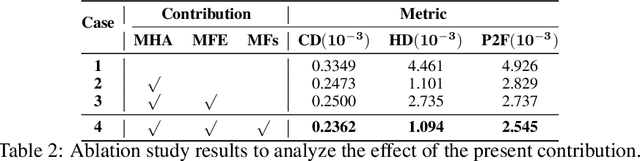
Recently, research using point clouds has been increasing with the development of 3D scanner technology. According to this trend, the demand for high-quality point clouds is increasing, but there is still a problem with the high cost of obtaining high-quality point clouds. Therefore, with the recent remarkable development of deep learning, point cloud up-sampling research, which uses deep learning to generate high-quality point clouds from low-quality point clouds, is one of the fields attracting considerable attention. This paper proposes a new point cloud up-sampling method called Point cloud Up-sampling via Multi-scale Features Attention (PU-MFA). Inspired by previous studies that reported good performance using the multi-scale features or attention mechanisms, PU-MFA merges the two through a U-Net structure. In addition, PU-MFA adaptively uses multi-scale features to refine the global features effectively. The performance of PU-MFA was compared with other state-of-the-art methods through various experiments using the PU-GAN dataset, which is a synthetic point cloud dataset, and the KITTI dataset, which is the real-scanned point cloud dataset. In various experimental results, PU-MFA showed superior performance in quantitative and qualitative evaluation compared to other state-of-the-art methods, proving the effectiveness of the proposed method. The attention map of PU-MFA was also visualized to show the effect of multi-scale features.
BYEL : Bootstrap on Your Emotion Latent
Jul 20, 2022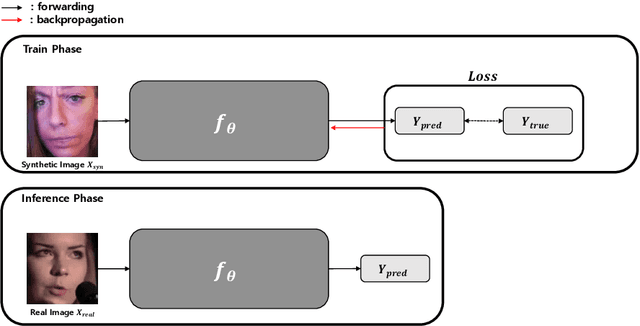
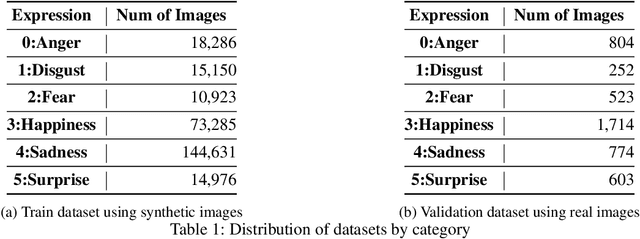
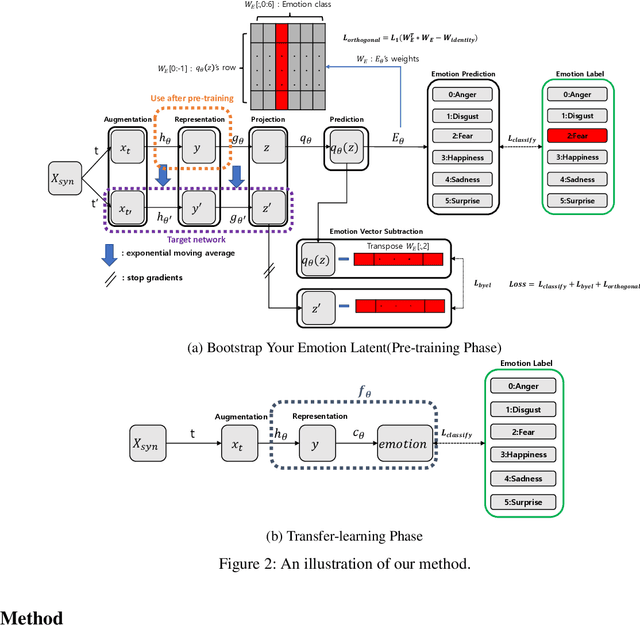
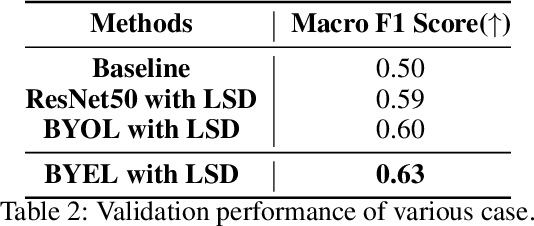
According to the problem of dataset construction cost for training in deep learning and the development of generative models, more and more researches are being conducted to train with synthetic data and to inference using real data. We propose emotion aware Self-Supervised Learning using ABAW's Learning Synthetic Data (LSD) dataset. We pre-train our method to LSD dataset as a self-supervised learning and then use the same LSD dataset to do downstream training on the emotion classification task as a supervised learning. As a result, a higher result(0.63) than baseline(0.5) was obtained.
Multitask Emotion Recognition Model with Knowledge Distillation and Task Discriminator
Mar 24, 2022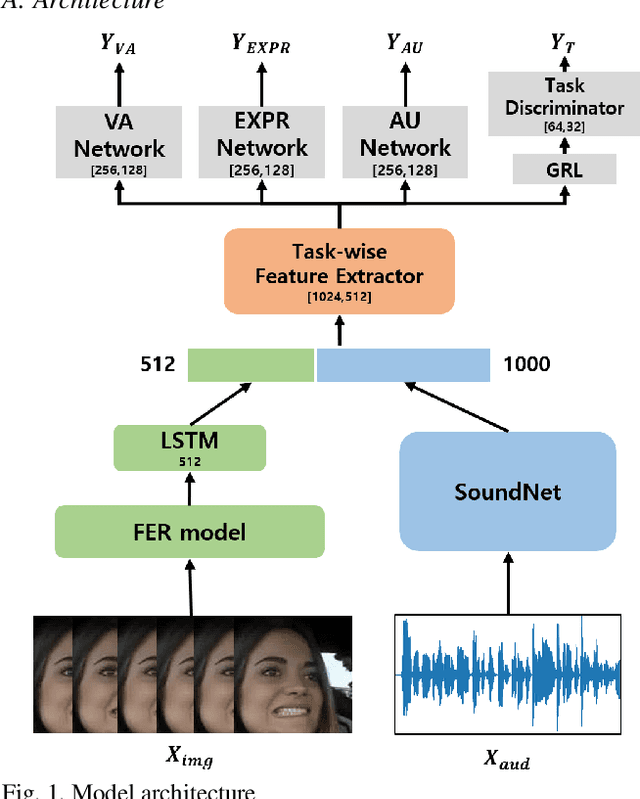

Due to the collection of big data and the development of deep learning, research to predict human emotions in the wild is being actively conducted. We designed a multi-task model using ABAW dataset to predict valence-arousal, expression, and action unit through audio data and face images at in real world. We trained model from the incomplete label by applying the knowledge distillation technique. The teacher model was trained as a supervised learning method, and the student model was trained by using the output of the teacher model as a soft label. As a result we achieved 2.40 in Multi Task Learning task validation dataset.
Causal affect prediction model using a facial image sequence
Jul 08, 2021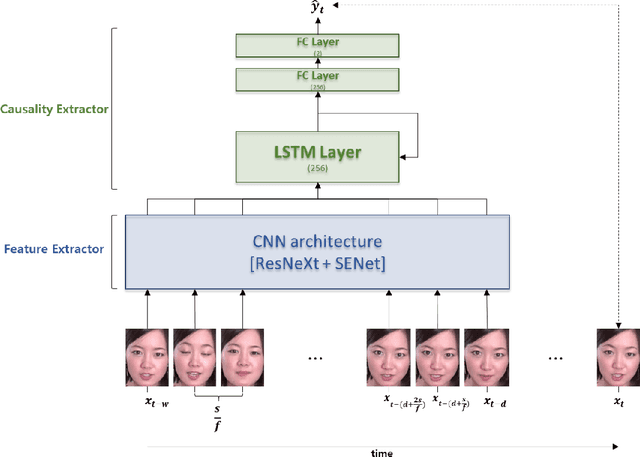
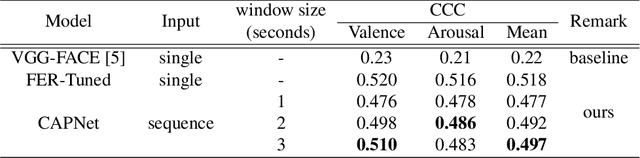
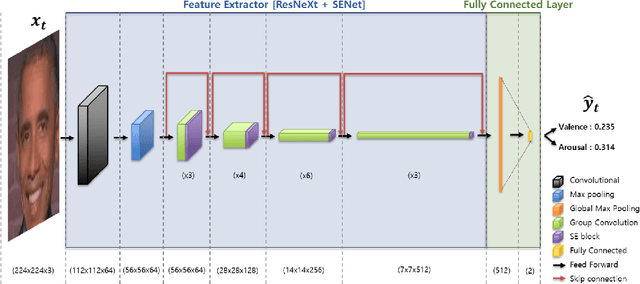
Among human affective behavior research, facial expression recognition research is improving in performance along with the development of deep learning. However, for improved performance, not only past images but also future images should be used along with corresponding facial images, but there are obstacles to the application of this technique to real-time environments. In this paper, we propose the causal affect prediction network (CAPNet), which uses only past facial images to predict corresponding affective valence and arousal. We train CAPNet to learn causal inference between past images and corresponding affective valence and arousal through supervised learning by pairing the sequence of past images with the current label using the Aff-Wild2 dataset. We show through experiments that the well-trained CAPNet outperforms the baseline of the second challenge of the Affective Behavior Analysis in-the-wild (ABAW2) Competition by predicting affective valence and arousal only with past facial images one-third of a second earlier. Therefore, in real-time application, CAPNet can reliably predict affective valence and arousal only with past data.