 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitask Emotion Recognition Model with Knowledge Distillation and Task Discriminator
Mar 24, 2022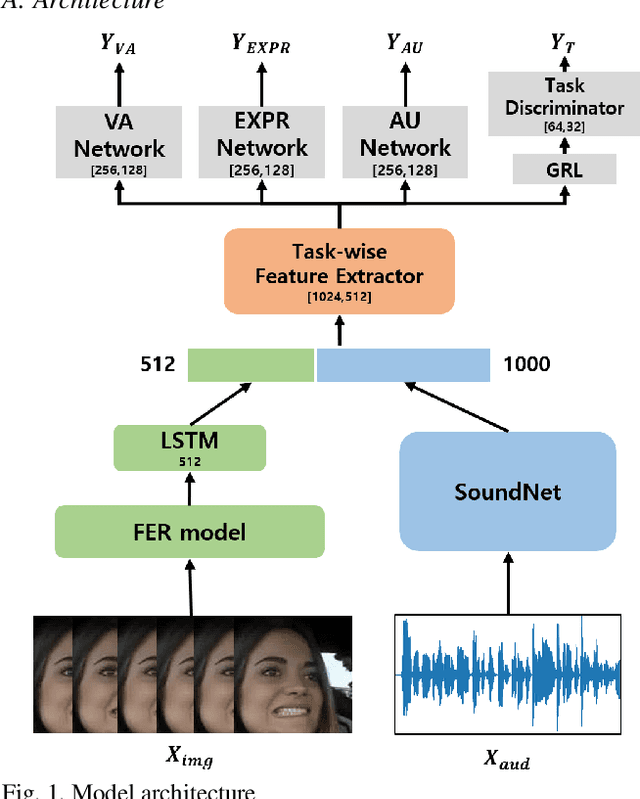

Due to the collection of big data and the development of deep learning, research to predict human emotions in the wild is being actively conducted. We designed a multi-task model using ABAW dataset to predict valence-arousal, expression, and action unit through audio data and face images at in real world. We trained model from the incomplete label by applying the knowledge distillation technique. The teacher model was trained as a supervised learning method, and the student model was trained by using the output of the teacher model as a soft label. As a result we achieved 2.40 in Multi Task Learning task validation dataset.
Causal affect prediction model using a facial image sequence
Jul 08, 2021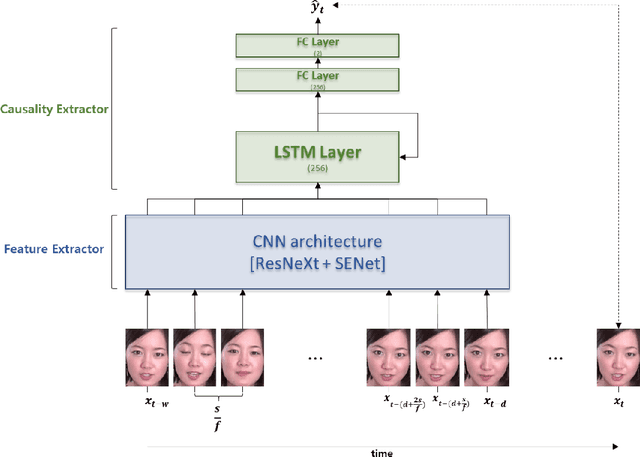
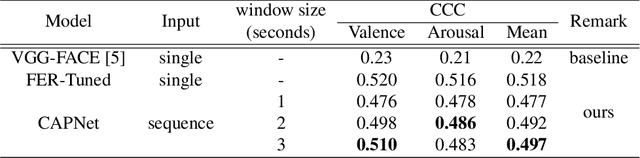
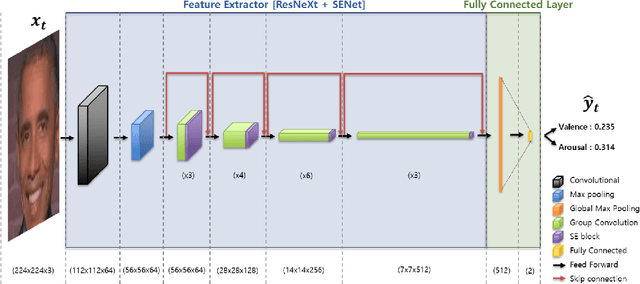
Among human affective behavior research, facial expression recognition research is improving in performance along with the development of deep learning. However, for improved performance, not only past images but also future images should be used along with corresponding facial images, but there are obstacles to the application of this technique to real-time environments. In this paper, we propose the causal affect prediction network (CAPNet), which uses only past facial images to predict corresponding affective valence and arousal. We train CAPNet to learn causal inference between past images and corresponding affective valence and arousal through supervised learning by pairing the sequence of past images with the current label using the Aff-Wild2 dataset. We show through experiments that the well-trained CAPNet outperforms the baseline of the second challenge of the Affective Behavior Analysis in-the-wild (ABAW2) Competition by predicting affective valence and arousal only with past facial images one-third of a second earlier. Therefore, in real-time application, CAPNet can reliably predict affective valence and arousal only with past data.