 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Better Match for Drivers and Riders: Reinforcement Learning at Lyft
Oct 20, 2023To better match drivers to riders in our ridesharing application, we revised Lyft's core matching algorithm. We use a novel online reinforcement learning approach that estimates the future earnings of drivers in real time and use this information to find more efficient matches. This change was the first documented implementation of a ridesharing matching algorithm that can learn and improve in real time. We evaluated the new approach during weeks of switchback experimentation in most Lyft markets, and estimated how it benefited drivers, riders, and the platform. In particular, it enabled our drivers to serve millions of additional riders each year, leading to more than $30 million per year in incremental revenue. Lyft rolled out the algorithm globally in 2021.
PU-MFA : Point Cloud Up-sampling via Multi-scale Features Attention
Aug 22, 2022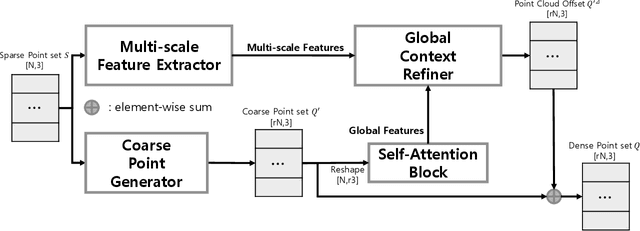

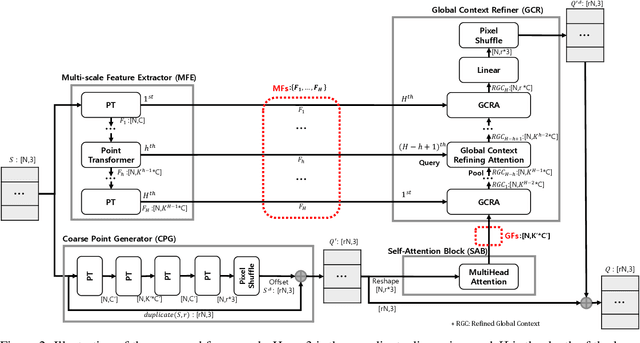
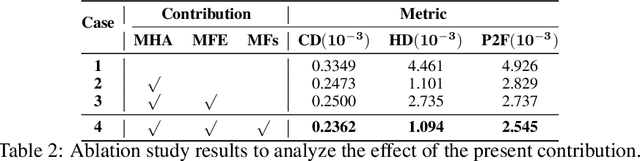
Recently, research using point clouds has been increasing with the development of 3D scanner technology. According to this trend, the demand for high-quality point clouds is increasing, but there is still a problem with the high cost of obtaining high-quality point clouds. Therefore, with the recent remarkable development of deep learning, point cloud up-sampling research, which uses deep learning to generate high-quality point clouds from low-quality point clouds, is one of the fields attracting considerable attention. This paper proposes a new point cloud up-sampling method called Point cloud Up-sampling via Multi-scale Features Attention (PU-MFA). Inspired by previous studies that reported good performance using the multi-scale features or attention mechanisms, PU-MFA merges the two through a U-Net structure. In addition, PU-MFA adaptively uses multi-scale features to refine the global features effectively. The performance of PU-MFA was compared with other state-of-the-art methods through various experiments using the PU-GAN dataset, which is a synthetic point cloud dataset, and the KITTI dataset, which is the real-scanned point cloud dataset. In various experimental results, PU-MFA showed superior performance in quantitative and qualitative evaluation compared to other state-of-the-art methods, proving the effectiveness of the proposed method. The attention map of PU-MFA was also visualized to show the effect of multi-scale features.
BYEL : Bootstrap on Your Emotion Latent
Jul 20, 2022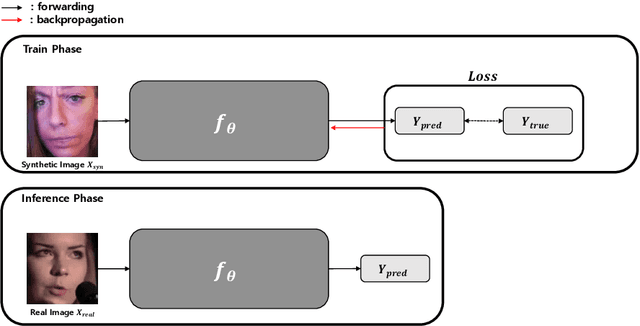
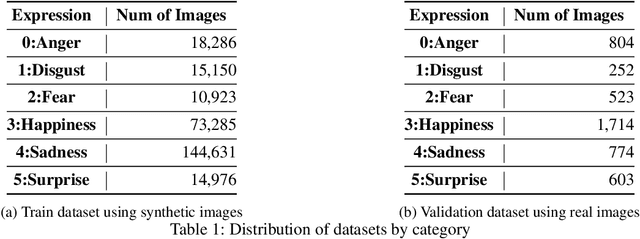
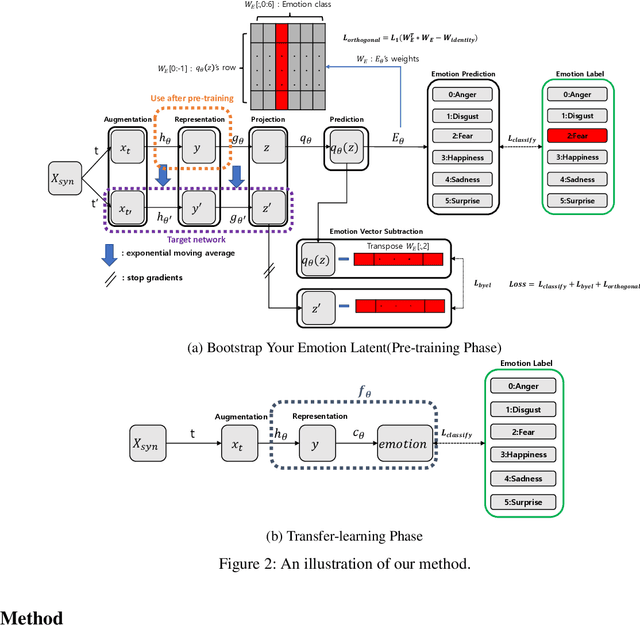
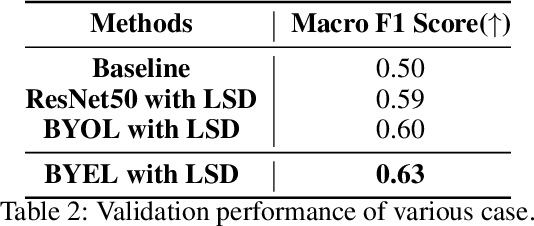
According to the problem of dataset construction cost for training in deep learning and the development of generative models, more and more researches are being conducted to train with synthetic data and to inference using real data. We propose emotion aware Self-Supervised Learning using ABAW's Learning Synthetic Data (LSD) dataset. We pre-train our method to LSD dataset as a self-supervised learning and then use the same LSD dataset to do downstream training on the emotion classification task as a supervised learning. As a result, a higher result(0.63) than baseline(0.5) was obtained.