 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRawGen: Learning Camera Raw Image Generation
Mar 31, 2026Cameras capture scene-referred linear raw images, which are processed by onboard image signal processors (ISPs) into display-referred 8-bit sRGB outputs. Although raw data is more faithful for low-level vision tasks, collecting large-scale raw datasets remains a major bottleneck, as existing datasets are limited and tied to specific camera hardware. Generative models offer a promising way to address this scarcity -- however, existing diffusion frameworks are designed to synthesize photo-finished sRGB images rather than physically consistent linear representations. This paper presents RawGen, to our knowledge the first diffusion-based framework enabling text-to-raw generation for arbitrary target cameras, alongside sRGB-to-raw inversion. RawGen leverages the generative priors of large-scale sRGB diffusion models to synthesize physically meaningful linear outputs, such as CIE XYZ or camera-specific raw representations, via specialized processing in latent and pixel spaces. To handle unknown and diverse ISP pipelines and photo-finishing effects in diffusion-model training data, we build a many-to-one inverse-ISP dataset where multiple sRGB renditions of the same scene generated using diverse ISP parameters are anchored to a common scene-referred target. Fine-tuning a conditional denoiser and specialized decoder on this dataset allows RawGen to obtain camera-centric linear reconstructions that effectively invert the rendering pipeline. We demonstrate RawGen's superior performance over traditional inverse-ISP methods that assume a fixed ISP. Furthermore, we show that augmenting training pipelines with RawGen's scalable, text-driven synthetic data can benefit downstream low-level vision tasks.
RAW-Domain Degradation Models for Realistic Smartphone Super-Resolution
Mar 12, 2026Digital zoom on smartphones relies on learning-based super-resolution (SR) models that operate on RAW sensor images, but obtaining sensor-specific training data is challenging due to the lack of ground-truth images. Synthetic data generation via ``unprocessing'' pipelines offers a potential solution by simulating the degradations that transform high-resolution (HR) images into their low-resolution (LR) counterparts. However, these pipelines can introduce domain gaps due to incomplete or unrealistic degradation modeling. In this paper, we demonstrate that principled and carefully designed degradation modeling can enhance SR performance in real-world conditions. Instead of relying on generic priors for camera blur and noise, we model device-specific degradations through calibration and unprocess publicly available rendered images into the RAW domain of different smartphones. Using these image pairs, we train a single-image RAW-to-RGB SR model and evaluate it on real data from a held-out device. Our experiments show that accurate degradation modeling leads to noticeable improvements, with our SR model outperforming baselines trained on large pools of arbitrarily chosen degradations.
Multispectral Demosaicing via Dual Cameras
Mar 27, 2025



Multispectral (MS) images capture detailed scene information across a wide range of spectral bands, making them invaluable for applications requiring rich spectral data. Integrating MS imaging into multi camera devices, such as smartphones, has the potential to enhance both spectral applications and RGB image quality. A critical step in processing MS data is demosaicing, which reconstructs color information from the mosaic MS images captured by the camera. This paper proposes a method for MS image demosaicing specifically designed for dual-camera setups where both RGB and MS cameras capture the same scene. Our approach leverages co-captured RGB images, which typically have higher spatial fidelity, to guide the demosaicing of lower-fidelity MS images. We introduce the Dual-camera RGB-MS Dataset - a large collection of paired RGB and MS mosaiced images with ground-truth demosaiced outputs - that enables training and evaluation of our method. Experimental results demonstrate that our method achieves state-of-the-art accuracy compared to existing techniques.
Enhancing Circuit Trainability with Selective Gate Activation Strategy
Mar 17, 2025



Hybrid quantum-classical computing relies heavily on Variational Quantum Algorithms (VQAs) to tackle challenges in diverse fields like quantum chemistry and machine learning. However, VQAs face a critical limitation: the balance between circuit trainability and expressibility. Trainability, the ease of optimizing circuit parameters for problem-solving, is often hampered by the Barren Plateau, where gradients vanish and hinder optimization. On the other hand, increasing expressibility, the ability to represent a wide range of quantum states, often necessitates deeper circuits with more parameters, which in turn exacerbates trainability issues. In this work, we investigate selective gate activation strategies as a potential solution to these challenges within the context of Variational Quantum Eigensolvers (VQEs). We evaluate three different approaches: activating gates randomly without considering their type or parameter magnitude, activating gates randomly but limited to a single gate type, and activating gates based on the magnitude of their parameter values. Experiment results reveal that the Magnitude-based strategy surpasses other methods, achieving improved convergence.
Q-MAML: Quantum Model-Agnostic Meta-Learning for Variational Quantum Algorithms
Jan 10, 2025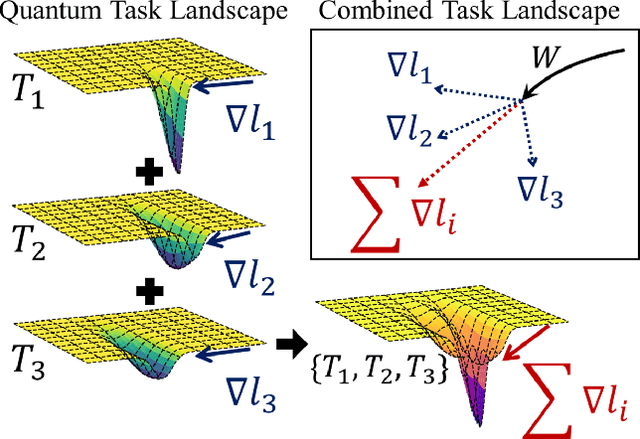

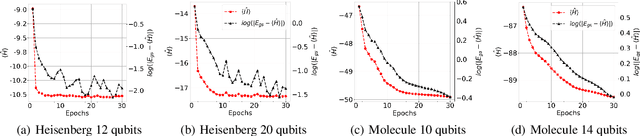
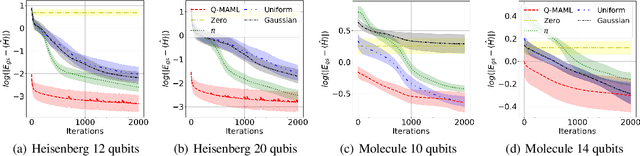
In the Noisy Intermediate-Scale Quantum (NISQ) era, using variational quantum algorithms (VQAs) to solve optimization problems has become a key application. However, these algorithms face significant challenges, such as choosing an effective initial set of parameters and the limited quantum processing time that restricts the number of optimization iterations. In this study, we introduce a new framework for optimizing parameterized quantum circuits (PQCs) that employs a classical optimizer, inspired by Model-Agnostic Meta-Learning (MAML) technique. This approach aim to achieve better parameter initialization that ensures fast convergence. Our framework features a classical neural network, called Learner}, which interacts with a PQC using the output of Learner as an initial parameter. During the pre-training phase, Learner is trained with a meta-objective based on the quantum circuit cost function. In the adaptation phase, the framework requires only a few PQC updates to converge to a more accurate value, while the learner remains unchanged. This method is highly adaptable and is effectively extended to various Hamiltonian optimization problems. We validate our approach through experiments, including distribution function mapping and optimization of the Heisenberg XYZ Hamiltonian. The result implies that the Learner successfully estimates initial parameters that generalize across the problem space, enabling fast adaptation.
Carrot and Stick: Inducing Self-Motivation with Positive & Negative Feedback
Jun 24, 2024Positive thinking is thought to be an important component of self-motivation in various practical fields such as education and the workplace. Previous work, including sentiment transfer and positive reframing, has focused on the positive side of language. However, self-motivation that drives people to reach their goals has not yet been studied from a computational perspective. Moreover, negative feedback has not yet been explored, even though positive and negative feedback are both necessary to grow self-motivation. To facilitate self-motivation, we propose CArrot and STICk (CASTIC) dataset, consisting of 12,590 sentences with 5 different strategies for enhancing self-motivation. Our data and code are publicly available at here.
Emotion Recognition Using Transformers with Masked Learning
Mar 23, 2024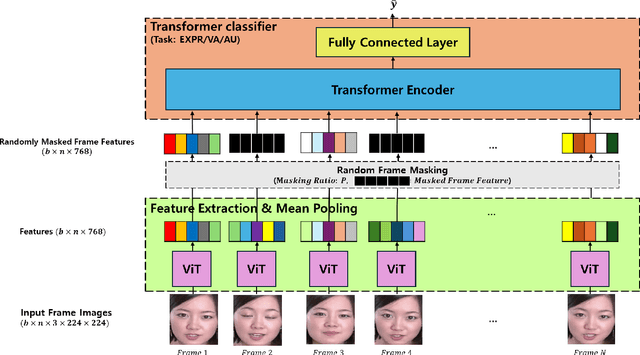
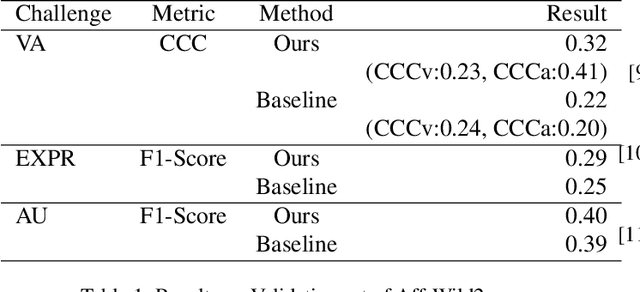
In recent years, deep learning has achieved innovative advancements in various fields, including the analysis of human emotions and behaviors. Initiatives such as the Affective Behavior Analysis in-the-wild (ABAW) competition have been particularly instrumental in driving research in this area by providing diverse and challenging datasets that enable precise evaluation of complex emotional states. This study leverages the Vision Transformer (ViT) and Transformer models to focus on the estimation of Valence-Arousal (VA), which signifies the positivity and intensity of emotions, recognition of various facial expressions, and detection of Action Units (AU) representing fundamental muscle movements. This approach transcends traditional Convolutional Neural Networks (CNNs) and Long Short-Term Memory (LSTM) based methods, proposing a new Transformer-based framework that maximizes the understanding of temporal and spatial features. The core contributions of this research include the introduction of a learning technique through random frame masking and the application of Focal loss adapted for imbalanced data, enhancing the accuracy and applicability of emotion and behavior analysis in real-world settings. This approach is expected to contribute to the advancement of emotional computing and deep learning methodologies.
ParamISP: Learned Forward and Inverse ISPs using Camera Parameters
Dec 20, 2023



RAW images are rarely shared mainly due to its excessive data size compared to their sRGB counterparts obtained by camera ISPs. Learning the forward and inverse processes of camera ISPs has been recently demonstrated, enabling physically-meaningful RAW-level image processing on input sRGB images. However, existing learning-based ISP methods fail to handle the large variations in the ISP processes with respect to camera parameters such as ISO and exposure time, and have limitations when used for various applications. In this paper, we propose ParamISP, a learning-based method for forward and inverse conversion between sRGB and RAW images, that adopts a novel neural-network module to utilize camera parameters, which is dubbed as ParamNet. Given the camera parameters provided in the EXIF data, ParamNet converts them into a feature vector to control the ISP networks. Extensive experiments demonstrate that ParamISP achieve superior RAW and sRGB reconstruction results compared to previous methods and it can be effectively used for a variety of applications such as deblurring dataset synthesis, raw deblurring, HDR reconstruction, and camera-to-camera transfer.
Deep Hybrid Camera Deblurring
Dec 20, 2023



Mobile cameras, despite their significant advancements, still face low-light challenges due to compact sensors and lenses, leading to longer exposures and motion blur. Traditional solutions like blind deconvolution and learning-based methods often fall short in handling ill-posedness of the deblurring problem. To address this, we propose a novel deblurring framework for multi-camera smartphones, utilizing a hybrid imaging technique. We simultaneously capture a long exposure wide-angle image and ultra-wide burst images from a smartphone, and use the sharp burst to estimate blur kernels for deblurring the wide-angle image. For learning and evaluation of our network, we introduce the HCBlur dataset, which includes pairs of blurry wide-angle and sharp ultra-wide burst images, and their sharp wide-angle counterparts. We extensively evaluate our method, and the result shows the state-of-the-art quality.
Rationale-aware Autonomous Driving Policy utilizing Safety Force Field implemented on CARLA Simulator
Nov 18, 2022



Despite the rapid improvement of autonomous driving technology in recent years, automotive manufacturers must resolve liability issues to commercialize autonomous passenger car of SAE J3016 Level 3 or higher. To cope with the product liability law, manufacturers develop autonomous driving systems in compliance with international standards for safety such as ISO 26262 and ISO 21448. Concerning the safety of the intended functionality (SOTIF) requirement in ISO 26262, the driving policy recommends providing an explicit rational basis for maneuver decisions. In this case, mathematical models such as Safety Force Field (SFF) and Responsibility-Sensitive Safety (RSS) which have interpretability on decision, may be suitable. In this work, we implement SFF from scratch to substitute the undisclosed NVIDIA's source code and integrate it with CARLA open-source simulator. Using SFF and CARLA, we present a predictor for claimed sets of vehicles, and based on the predictor, propose an integrated driving policy that consistently operates regardless of safety conditions it encounters while passing through dynamic traffic. The policy does not have a separate plan for each condition, but using safety potential, it aims human-like driving blended in with traffic flow.