 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned split-spectrum metalens for obstruction-free broadband imaging in the visible
Jan 27, 2026Obstructions such as raindrops, fences, or dust degrade captured images, especially when mechanical cleaning is infeasible. Conventional solutions to obstructions rely on a bulky compound optics array or computational inpainting, which compromise compactness or fidelity. Metalenses composed of subwavelength meta-atoms promise compact imaging, but simultaneous achievement of broadband and obstruction-free imaging remains a challenge, since a metalens that images distant scenes across a broadband spectrum cannot properly defocus near-depth occlusions. Here, we introduce a learned split-spectrum metalens that enables broadband obstruction-free imaging. Our approach divides the spectrum of each RGB channel into pass and stop bands with multi-band spectral filtering and learns the metalens to focus light from far objects through pass bands, while filtering focused near-depth light through stop bands. This optical signal is further enhanced using a neural network. Our learned split-spectrum metalens achieves broadband and obstruction-free imaging with relative PSNR gains of 32.29% and improves object detection and semantic segmentation accuracies with absolute gains of +13.54% mAP, +48.45% IoU, and +20.35% mIoU over a conventional hyperbolic design. This promises robust obstruction-free sensing and vision for space-constrained systems, such as mobile robots, drones, and endoscopes.
A Real-world Display Inverse Rendering Dataset
Aug 20, 2025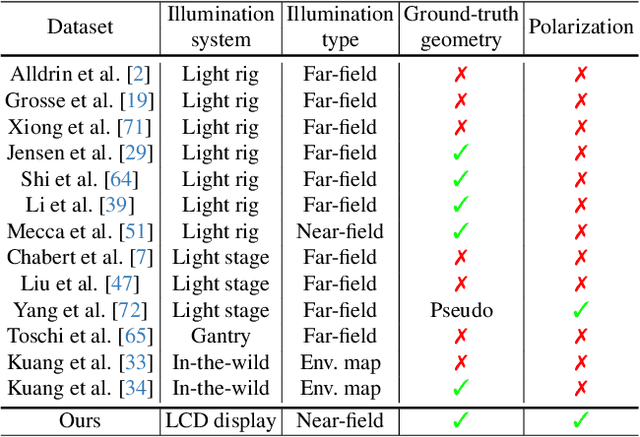
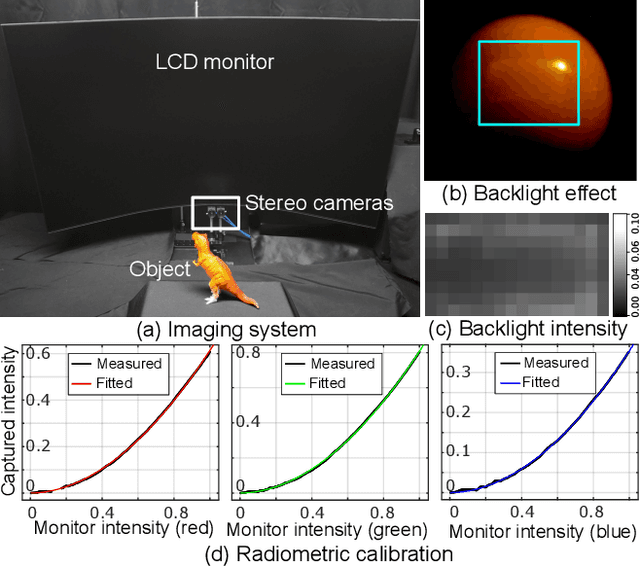


Inverse rendering aims to reconstruct geometry and reflectance from captured images. Display-camera imaging systems offer unique advantages for this task: each pixel can easily function as a programmable point light source, and the polarized light emitted by LCD displays facilitates diffuse-specular separation. Despite these benefits, there is currently no public real-world dataset captured using display-camera systems, unlike other setups such as light stages. This absence hinders the development and evaluation of display-based inverse rendering methods. In this paper, we introduce the first real-world dataset for display-based inverse rendering. To achieve this, we construct and calibrate an imaging system comprising an LCD display and stereo polarization cameras. We then capture a diverse set of objects with diverse geometry and reflectance under one-light-at-a-time (OLAT) display patterns. We also provide high-quality ground-truth geometry. Our dataset enables the synthesis of captured images under arbitrary display patterns and different noise levels. Using this dataset, we evaluate the performance of existing photometric stereo and inverse rendering methods, and provide a simple, yet effective baseline for display inverse rendering, outperforming state-of-the-art inverse rendering methods. Code and dataset are available on our project page at https://michaelcsj.github.io/DIR/
Complex-Valued Holographic Radiance Fields
Jun 10, 2025Modeling the full properties of light, including both amplitude and phase, in 3D representations is crucial for advancing physically plausible rendering, particularly in holographic displays. To support these features, we propose a novel representation that optimizes 3D scenes without relying on intensity-based intermediaries. We reformulate 3D Gaussian splatting with complex-valued Gaussian primitives, expanding support for rendering with light waves. By leveraging RGBD multi-view images, our method directly optimizes complex-valued Gaussians as a 3D holographic scene representation. This eliminates the need for computationally expensive hologram re-optimization. Compared with state-of-the-art methods, our method achieves 30x-10,000x speed improvements while maintaining on-par image quality, representing a first step towards geometrically aligned, physically plausible holographic scene representations.
FloVD: Optical Flow Meets Video Diffusion Model for Enhanced Camera-Controlled Video Synthesis
Feb 12, 2025This paper presents FloVD, a novel optical-flow-based video diffusion model for camera-controllable video generation. FloVD leverages optical flow maps to represent motions of the camera and moving objects. This approach offers two key benefits. Since optical flow can be directly estimated from videos, our approach allows for the use of arbitrary training videos without ground-truth camera parameters. Moreover, as background optical flow encodes 3D correlation across different viewpoints, our method enables detailed camera control by leveraging the background motion. To synthesize natural object motion while supporting detailed camera control, our framework adopts a two-stage video synthesis pipeline consisting of optical flow generation and flow-conditioned video synthesis. Extensive experiments demonstrate the superiority of our method over previous approaches in terms of accurate camera control and natural object motion synthesis.
Differentiable Mobile Display Photometric Stereo
Feb 07, 2025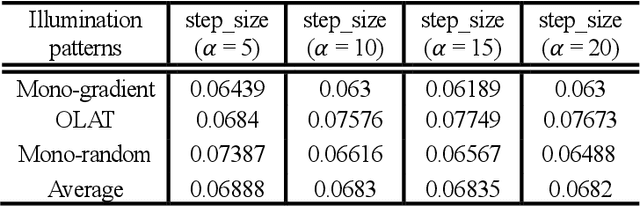



Display photometric stereo uses a display as a programmable light source to illuminate a scene with diverse illumination conditions. Recently, differentiable display photometric stereo (DDPS) demonstrated improved normal reconstruction accuracy by using learned display patterns. However, DDPS faced limitations in practicality, requiring a fixed desktop imaging setup using a polarization camera and a desktop-scale monitor. In this paper, we propose a more practical physics-based photometric stereo, differentiable mobile display photometric stereo (DMDPS), that leverages a mobile phone consisting of a display and a camera. We overcome the limitations of using a mobile device by developing a mobile app and method that simultaneously displays patterns and captures high-quality HDR images. Using this technique, we capture real-world 3D-printed objects and learn display patterns via a differentiable learning process. We demonstrate the effectiveness of DMDPS on both a 3D printed dataset and a first dataset of fallen leaves. The leaf dataset contains reconstructed surface normals and albedos of fallen leaves that may enable future research beyond computer graphics and vision. We believe that DMDPS takes a step forward for practical physics-based photometric stereo.
Polarimetric BSSRDF Acquisition of Dynamic Faces
Dec 29, 2024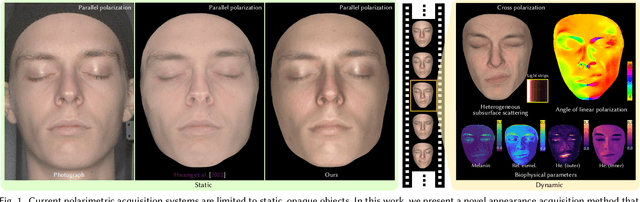
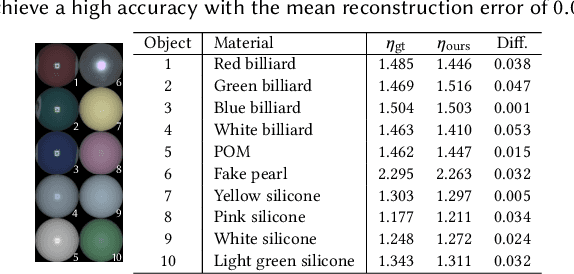
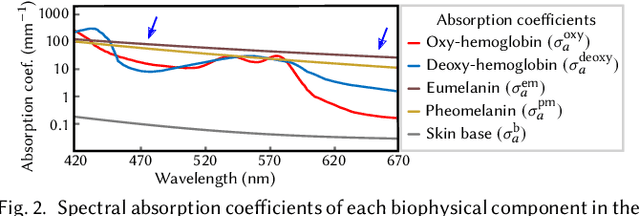

Acquisition and modeling of polarized light reflection and scattering help reveal the shape, structure, and physical characteristics of an object, which is increasingly important in computer graphics. However, current polarimetric acquisition systems are limited to static and opaque objects. Human faces, on the other hand, present a particularly difficult challenge, given their complex structure and reflectance properties, the strong presence of spatially-varying subsurface scattering, and their dynamic nature. We present a new polarimetric acquisition method for dynamic human faces, which focuses on capturing spatially varying appearance and precise geometry, across a wide spectrum of skin tones and facial expressions. It includes both single and heterogeneous subsurface scattering, index of refraction, and specular roughness and intensity, among other parameters, while revealing biophysically-based components such as inner- and outer-layer hemoglobin, eumelanin and pheomelanin. Our method leverages such components' unique multispectral absorption profiles to quantify their concentrations, which in turn inform our model about the complex interactions occurring within the skin layers. To our knowledge, our work is the first to simultaneously acquire polarimetric and spectral reflectance information alongside biophysically-based skin parameters and geometry of dynamic human faces. Moreover, our polarimetric skin model integrates seamlessly into various rendering pipelines.
Dual Exposure Stereo for Extended Dynamic Range 3D Imaging
Dec 03, 2024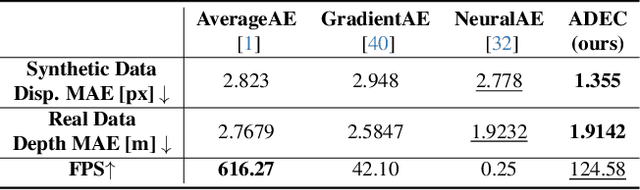
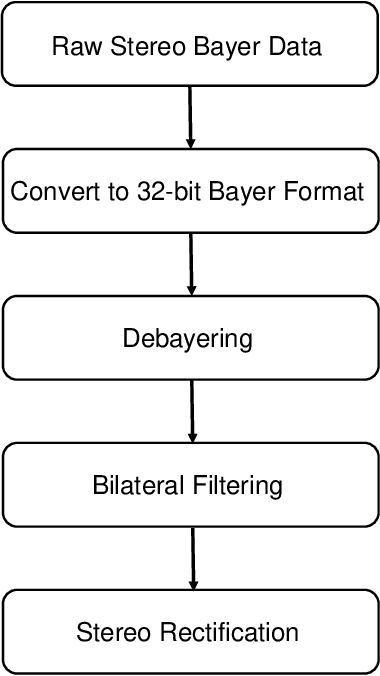

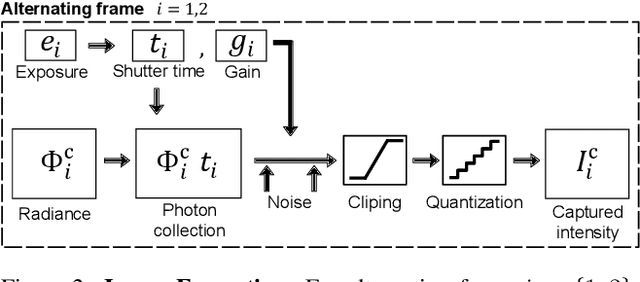
Achieving robust stereo 3D imaging under diverse illumination conditions is an important however challenging task, due to the limited dynamic ranges (DRs) of cameras, which are significantly smaller than real world DR. As a result, the accuracy of existing stereo depth estimation methods is often compromised by under- or over-exposed images. Here, we introduce dual-exposure stereo for extended dynamic range 3D imaging. We develop automatic dual-exposure control method that adjusts the dual exposures, diverging them when the scene DR exceeds the camera DR, thereby providing information about broader DR. From the captured dual-exposure stereo images, we estimate depth using motion-aware dual-exposure stereo network. To validate our method, we develop a robot-vision system, collect stereo video datasets, and generate a synthetic dataset. Our method outperforms other exposure control methods.
Dense Dispersed Structured Light for Hyperspectral 3D Imaging of Dynamic Scenes
Dec 02, 2024

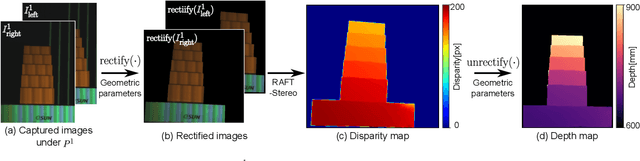

Hyperspectral 3D imaging captures both depth maps and hyperspectral images, enabling comprehensive geometric and material analysis. Recent methods achieve high spectral and depth accuracy; however, they require long acquisition times often over several minutes or rely on large, expensive systems, restricting their use to static scenes. We present Dense Dispersed Structured Light (DDSL), an accurate hyperspectral 3D imaging method for dynamic scenes that utilizes stereo RGB cameras and an RGB projector equipped with an affordable diffraction grating film. We design spectrally multiplexed DDSL patterns that significantly reduce the number of required projector patterns, thereby accelerating acquisition speed. Additionally, we formulate an image formation model and a reconstruction method to estimate a hyperspectral image and depth map from captured stereo images. As the first practical and accurate hyperspectral 3D imaging method for dynamic scenes, we experimentally demonstrate that DDSL achieves a spectral resolution of 15.5 nm full width at half maximum (FWHM), a depth error of 4 mm, and a frame rate of 6.6 fps.
Pixel-aligned RGB-NIR Stereo Imaging and Dataset for Robot Vision
Nov 27, 2024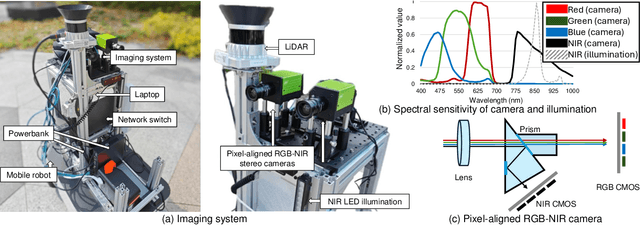
Integrating RGB and NIR stereo imaging provides complementary spectral information, potentially enhancing robotic 3D vision in challenging lighting conditions. However, existing datasets and imaging systems lack pixel-level alignment between RGB and NIR images, posing challenges for downstream vision tasks. In this paper, we introduce a robotic vision system equipped with pixel-aligned RGB-NIR stereo cameras and a LiDAR sensor mounted on a mobile robot. The system simultaneously captures pixel-aligned pairs of RGB stereo images, NIR stereo images, and temporally synchronized LiDAR points. Utilizing the mobility of the robot, we present a dataset containing continuous video frames under diverse lighting conditions. We then introduce two methods that utilize the pixel-aligned RGB-NIR images: an RGB-NIR image fusion method and a feature fusion method. The first approach enables existing RGB-pretrained vision models to directly utilize RGB-NIR information without fine-tuning. The second approach fine-tunes existing vision models to more effectively utilize RGB-NIR information. Experimental results demonstrate the effectiveness of using pixel-aligned RGB-NIR images across diverse lighting conditions.
Differentiable Inverse Rendering with Interpretable Basis BRDFs
Nov 27, 2024Inverse rendering seeks to reconstruct both geometry and spatially varying BRDFs (SVBRDFs) from captured images. To address the inherent ill-posedness of inverse rendering, basis BRDF representations are commonly used, modeling SVBRDFs as spatially varying blends of a set of basis BRDFs. However, existing methods often yield basis BRDFs that lack intuitive separation and have limited scalability to scenes of varying complexity. In this paper, we introduce a differentiable inverse rendering method that produces interpretable basis BRDFs. Our approach models a scene using 2D Gaussians, where the reflectance of each Gaussian is defined by a weighted blend of basis BRDFs. We efficiently render an image from the 2D Gaussians and basis BRDFs using differentiable rasterization and impose a rendering loss with the input images. During this analysis-by-synthesis optimization process of differentiable inverse rendering, we dynamically adjust the number of basis BRDFs to fit the target scene while encouraging sparsity in the basis weights. This ensures that the reflectance of each Gaussian is represented by only a few basis BRDFs. This approach enables the reconstruction of accurate geometry and interpretable basis BRDFs that are spatially separated. Consequently, the resulting scene representation, comprising basis BRDFs and 2D Gaussians, supports physically-based novel-view relighting and intuitive scene editing.