 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniLiPs: Unified LiDAR Pseudo-Labeling with Geometry-Grounded Dynamic Scene Decomposition
Jan 08, 2026Unlabeled LiDAR logs, in autonomous driving applications, are inherently a gold mine of dense 3D geometry hiding in plain sight - yet they are almost useless without human labels, highlighting a dominant cost barrier for autonomous-perception research. In this work we tackle this bottleneck by leveraging temporal-geometric consistency across LiDAR sweeps to lift and fuse cues from text and 2D vision foundation models directly into 3D, without any manual input. We introduce an unsupervised multi-modal pseudo-labeling method relying on strong geometric priors learned from temporally accumulated LiDAR maps, alongside with a novel iterative update rule that enforces joint geometric-semantic consistency, and vice-versa detecting moving objects from inconsistencies. Our method simultaneously produces 3D semantic labels, 3D bounding boxes, and dense LiDAR scans, demonstrating robust generalization across three datasets. We experimentally validate that our method compares favorably to existing semantic segmentation and object detection pseudo-labeling methods, which often require additional manual supervision. We confirm that even a small fraction of our geometrically consistent, densified LiDAR improves depth prediction by 51.5% and 22.0% MAE in the 80-150 and 150-250 meters range, respectively.
Dual Exposure Stereo for Extended Dynamic Range 3D Imaging
Dec 03, 2024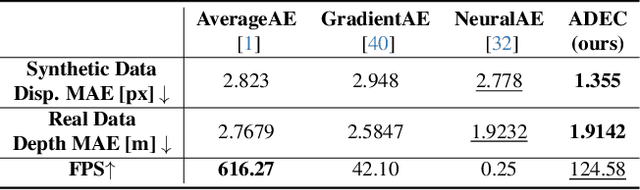
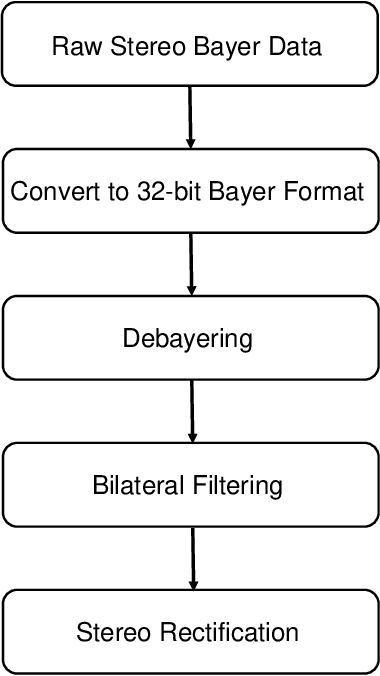

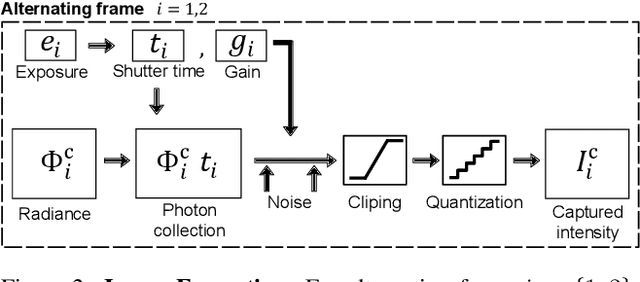
Achieving robust stereo 3D imaging under diverse illumination conditions is an important however challenging task, due to the limited dynamic ranges (DRs) of cameras, which are significantly smaller than real world DR. As a result, the accuracy of existing stereo depth estimation methods is often compromised by under- or over-exposed images. Here, we introduce dual-exposure stereo for extended dynamic range 3D imaging. We develop automatic dual-exposure control method that adjusts the dual exposures, diverging them when the scene DR exceeds the camera DR, thereby providing information about broader DR. From the captured dual-exposure stereo images, we estimate depth using motion-aware dual-exposure stereo network. To validate our method, we develop a robot-vision system, collect stereo video datasets, and generate a synthetic dataset. Our method outperforms other exposure control methods.
Cross-spectral Gated-RGB Stereo Depth Estimation
May 21, 2024Gated cameras flood-illuminate a scene and capture the time-gated impulse response of a scene. By employing nanosecond-scale gates, existing sensors are capable of capturing mega-pixel gated images, delivering dense depth improving on today's LiDAR sensors in spatial resolution and depth precision. Although gated depth estimation methods deliver a million of depth estimates per frame, their resolution is still an order below existing RGB imaging methods. In this work, we combine high-resolution stereo HDR RCCB cameras with gated imaging, allowing us to exploit depth cues from active gating, multi-view RGB and multi-view NIR sensing -- multi-view and gated cues across the entire spectrum. The resulting capture system consists only of low-cost CMOS sensors and flood-illumination. We propose a novel stereo-depth estimation method that is capable of exploiting these multi-modal multi-view depth cues, including the active illumination that is measured by the RCCB camera when removing the IR-cut filter. The proposed method achieves accurate depth at long ranges, outperforming the next best existing method by 39% for ranges of 100 to 220m in MAE on accumulated LiDAR ground-truth. Our code, models and datasets are available at https://light.princeton.edu/gatedrccbstereo/ .