 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniLiPs: Unified LiDAR Pseudo-Labeling with Geometry-Grounded Dynamic Scene Decomposition
Jan 08, 2026Unlabeled LiDAR logs, in autonomous driving applications, are inherently a gold mine of dense 3D geometry hiding in plain sight - yet they are almost useless without human labels, highlighting a dominant cost barrier for autonomous-perception research. In this work we tackle this bottleneck by leveraging temporal-geometric consistency across LiDAR sweeps to lift and fuse cues from text and 2D vision foundation models directly into 3D, without any manual input. We introduce an unsupervised multi-modal pseudo-labeling method relying on strong geometric priors learned from temporally accumulated LiDAR maps, alongside with a novel iterative update rule that enforces joint geometric-semantic consistency, and vice-versa detecting moving objects from inconsistencies. Our method simultaneously produces 3D semantic labels, 3D bounding boxes, and dense LiDAR scans, demonstrating robust generalization across three datasets. We experimentally validate that our method compares favorably to existing semantic segmentation and object detection pseudo-labeling methods, which often require additional manual supervision. We confirm that even a small fraction of our geometrically consistent, densified LiDAR improves depth prediction by 51.5% and 22.0% MAE in the 80-150 and 150-250 meters range, respectively.
LSD-3D: Large-Scale 3D Driving Scene Generation with Geometry Grounding
Aug 26, 2025Large-scale scene data is essential for training and testing in robot learning. Neural reconstruction methods have promised the capability of reconstructing large physically-grounded outdoor scenes from captured sensor data. However, these methods have baked-in static environments and only allow for limited scene control -- they are functionally constrained in scene and trajectory diversity by the captures from which they are reconstructed. In contrast, generating driving data with recent image or video diffusion models offers control, however, at the cost of geometry grounding and causality. In this work, we aim to bridge this gap and present a method that directly generates large-scale 3D driving scenes with accurate geometry, allowing for causal novel view synthesis with object permanence and explicit 3D geometry estimation. The proposed method combines the generation of a proxy geometry and environment representation with score distillation from learned 2D image priors. We find that this approach allows for high controllability, enabling the prompt-guided geometry and high-fidelity texture and structure that can be conditioned on map layouts -- producing realistic and geometrically consistent 3D generations of complex driving scenes.
Beyond Domain Randomization: Event-Inspired Perception for Visually Robust Adversarial Imitation from Videos
May 24, 2025Imitation from videos often fails when expert demonstrations and learner environments exhibit domain shifts, such as discrepancies in lighting, color, or texture. While visual randomization partially addresses this problem by augmenting training data, it remains computationally intensive and inherently reactive, struggling with unseen scenarios. We propose a different approach: instead of randomizing appearances, we eliminate their influence entirely by rethinking the sensory representation itself. Inspired by biological vision systems that prioritize temporal transients (e.g., retinal ganglion cells) and by recent sensor advancements, we introduce event-inspired perception for visually robust imitation. Our method converts standard RGB videos into a sparse, event-based representation that encodes temporal intensity gradients, discarding static appearance features. This biologically grounded approach disentangles motion dynamics from visual style, enabling robust visual imitation from observations even in the presence of visual mismatches between expert and agent environments. By training policies on event streams, we achieve invariance to appearance-based distractors without requiring computationally expensive and environment-specific data augmentation techniques. Experiments across the DeepMind Control Suite and the Adroit platform for dynamic dexterous manipulation show the efficacy of our method. Our code is publicly available at Eb-LAIfO.
Dual Exposure Stereo for Extended Dynamic Range 3D Imaging
Dec 03, 2024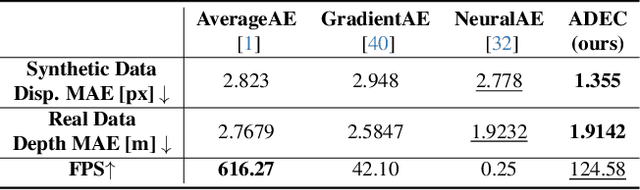
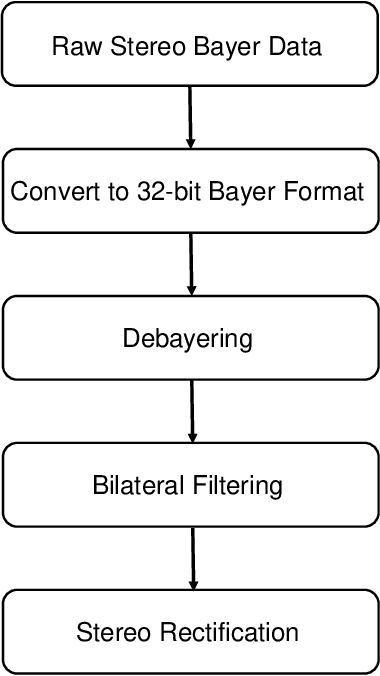

Achieving robust stereo 3D imaging under diverse illumination conditions is an important however challenging task, due to the limited dynamic ranges (DRs) of cameras, which are significantly smaller than real world DR. As a result, the accuracy of existing stereo depth estimation methods is often compromised by under- or over-exposed images. Here, we introduce dual-exposure stereo for extended dynamic range 3D imaging. We develop automatic dual-exposure control method that adjusts the dual exposures, diverging them when the scene DR exceeds the camera DR, thereby providing information about broader DR. From the captured dual-exposure stereo images, we estimate depth using motion-aware dual-exposure stereo network. To validate our method, we develop a robot-vision system, collect stereo video datasets, and generate a synthetic dataset. Our method outperforms other exposure control methods.
Polarization Wavefront Lidar: Learning Large Scene Reconstruction from Polarized Wavefronts
Jun 05, 2024



Lidar has become a cornerstone sensing modality for 3D vision, especially for large outdoor scenarios and autonomous driving. Conventional lidar sensors are capable of providing centimeter-accurate distance information by emitting laser pulses into a scene and measuring the time-of-flight (ToF) of the reflection. However, the polarization of the received light that depends on the surface orientation and material properties is usually not considered. As such, the polarization modality has the potential to improve scene reconstruction beyond distance measurements. In this work, we introduce a novel long-range polarization wavefront lidar sensor (PolLidar) that modulates the polarization of the emitted and received light. Departing from conventional lidar sensors, PolLidar allows access to the raw time-resolved polarimetric wavefronts. We leverage polarimetric wavefronts to estimate normals, distance, and material properties in outdoor scenarios with a novel learned reconstruction method. To train and evaluate the method, we introduce a simulated and real-world long-range dataset with paired raw lidar data, ground truth distance, and normal maps. We find that the proposed method improves normal and distance reconstruction by 53\% mean angular error and 41\% mean absolute error compared to existing shape-from-polarization (SfP) and ToF methods. Code and data are open-sourced at https://light.princeton.edu/pollidar.
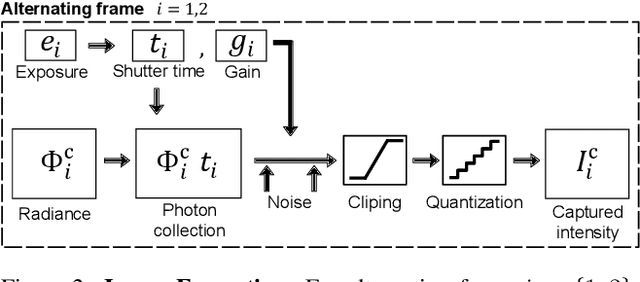
Gated Fields: Learning Scene Reconstruction from Gated Videos
May 30, 2024


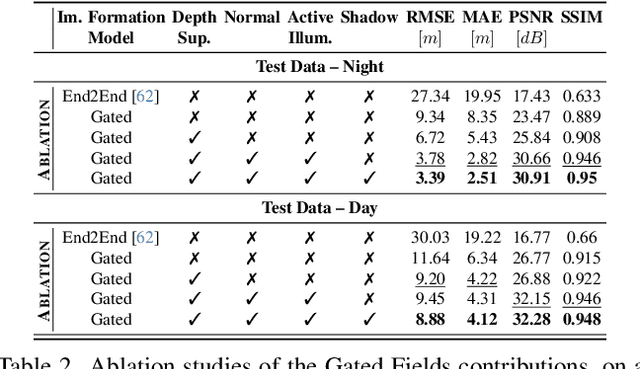
Reconstructing outdoor 3D scenes from temporal observations is a challenge that recent work on neural fields has offered a new avenue for. However, existing methods that recover scene properties, such as geometry, appearance, or radiance, solely from RGB captures often fail when handling poorly-lit or texture-deficient regions. Similarly, recovering scenes with scanning LiDAR sensors is also difficult due to their low angular sampling rate which makes recovering expansive real-world scenes difficult. Tackling these gaps, we introduce Gated Fields - a neural scene reconstruction method that utilizes active gated video sequences. To this end, we propose a neural rendering approach that seamlessly incorporates time-gated capture and illumination. Our method exploits the intrinsic depth cues in the gated videos, achieving precise and dense geometry reconstruction irrespective of ambient illumination conditions. We validate the method across day and night scenarios and find that Gated Fields compares favorably to RGB and LiDAR reconstruction methods. Our code and datasets are available at https://light.princeton.edu/gatedfields/.
HINT: Learning Complete Human Neural Representations from Limited Viewpoints
May 30, 2024No augmented application is possible without animated humanoid avatars. At the same time, generating human replicas from real-world monocular hand-held or robotic sensor setups is challenging due to the limited availability of views. Previous work showed the feasibility of virtual avatars but required the presence of 360 degree views of the targeted subject. To address this issue, we propose HINT, a NeRF-based algorithm able to learn a detailed and complete human model from limited viewing angles. We achieve this by introducing a symmetry prior, regularization constraints, and training cues from large human datasets. In particular, we introduce a sagittal plane symmetry prior to the appearance of the human, directly supervise the density function of the human model using explicit 3D body modeling, and leverage a co-learned human digitization network as additional supervision for the unseen angles. As a result, our method can reconstruct complete humans even from a few viewing angles, increasing performance by more than 15% PSNR compared to previous state-of-the-art algorithms.
Real-Time Environment Condition Classification for Autonomous Vehicles
May 29, 2024
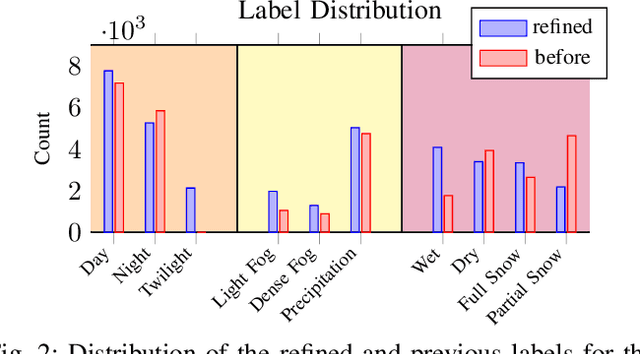
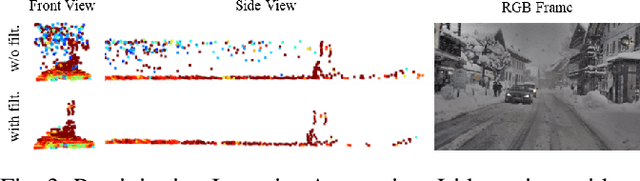
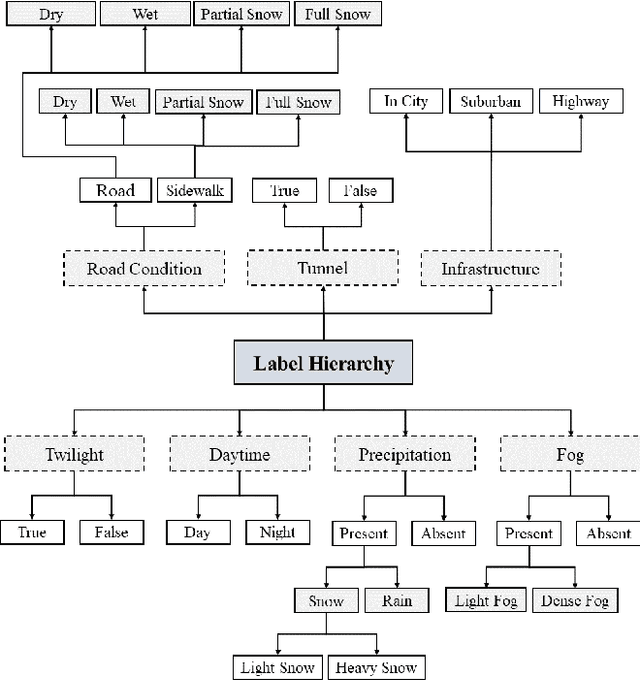
Current autonomous driving technologies are being rolled out in geo-fenced areas with well-defined operation conditions such as time of operation, area, weather conditions and road conditions. In this way, challenging conditions as adverse weather, slippery road or densely-populated city centers can be excluded. In order to lift the geo-fenced restriction and allow a more dynamic availability of autonomous driving functions, it is necessary for the vehicle to autonomously perform an environment condition assessment in real time to identify when the system cannot operate safely and either stop operation or require the resting passenger to take control. In particular, adverse-weather challenges are a fundamental limitation as sensor performance degenerates quickly, prohibiting the use of sensors such as cameras to locate and monitor road signs, pedestrians or other vehicles. To address this issue, we train a deep learning model to identify outdoor weather and dangerous road conditions, enabling a quick reaction to new situations and environments. We achieve this by introducing an improved taxonomy and label hierarchy for a state-of-the-art adverse-weather dataset, relabelling it with a novel semi-automated labeling pipeline. Using the novel proposed dataset and hierarchy, we train RECNet, a deep learning model for the classification of environment conditions from a single RGB frame. We outperform baseline models by relative 16% in F1- Score, while maintaining a real-time capable performance of 20 Hz.
Cross-spectral Gated-RGB Stereo Depth Estimation
May 21, 2024Gated cameras flood-illuminate a scene and capture the time-gated impulse response of a scene. By employing nanosecond-scale gates, existing sensors are capable of capturing mega-pixel gated images, delivering dense depth improving on today's LiDAR sensors in spatial resolution and depth precision. Although gated depth estimation methods deliver a million of depth estimates per frame, their resolution is still an order below existing RGB imaging methods. In this work, we combine high-resolution stereo HDR RCCB cameras with gated imaging, allowing us to exploit depth cues from active gating, multi-view RGB and multi-view NIR sensing -- multi-view and gated cues across the entire spectrum. The resulting capture system consists only of low-cost CMOS sensors and flood-illumination. We propose a novel stereo-depth estimation method that is capable of exploiting these multi-modal multi-view depth cues, including the active illumination that is measured by the RCCB camera when removing the IR-cut filter. The proposed method achieves accurate depth at long ranges, outperforming the next best existing method by 39% for ranges of 100 to 220m in MAE on accumulated LiDAR ground-truth. Our code, models and datasets are available at https://light.princeton.edu/gatedrccbstereo/ .
Radar Fields: Frequency-Space Neural Scene Representations for FMCW Radar
May 07, 2024Neural fields have been broadly investigated as scene representations for the reproduction and novel generation of diverse outdoor scenes, including those autonomous vehicles and robots must handle. While successful approaches for RGB and LiDAR data exist, neural reconstruction methods for radar as a sensing modality have been largely unexplored. Operating at millimeter wavelengths, radar sensors are robust to scattering in fog and rain, and, as such, offer a complementary modality to active and passive optical sensing techniques. Moreover, existing radar sensors are highly cost-effective and deployed broadly in robots and vehicles that operate outdoors. We introduce Radar Fields - a neural scene reconstruction method designed for active radar imagers. Our approach unites an explicit, physics-informed sensor model with an implicit neural geometry and reflectance model to directly synthesize raw radar measurements and extract scene occupancy. The proposed method does not rely on volume rendering. Instead, we learn fields in Fourier frequency space, supervised with raw radar data. We validate the effectiveness of the method across diverse outdoor scenarios, including urban scenes with dense vehicles and infrastructure, and in harsh weather scenarios, where mm-wavelength sensing is especially favorable.