 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Stereo: Joint Depth Estimation from Gated and Wide-Baseline Active Stereo Cues
May 22, 2023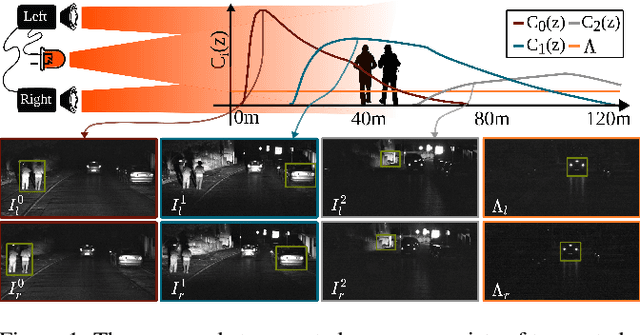
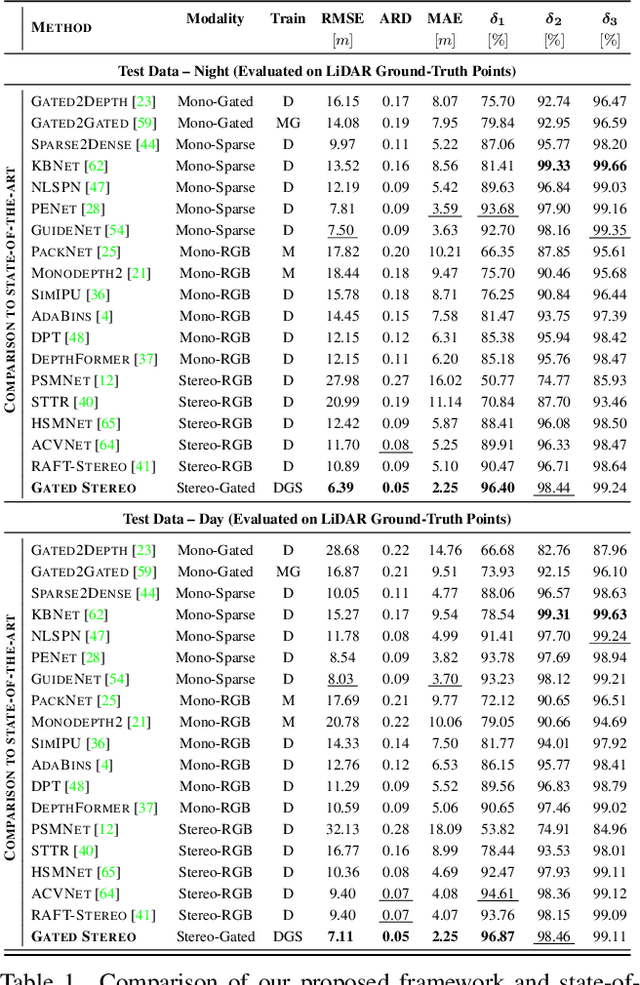
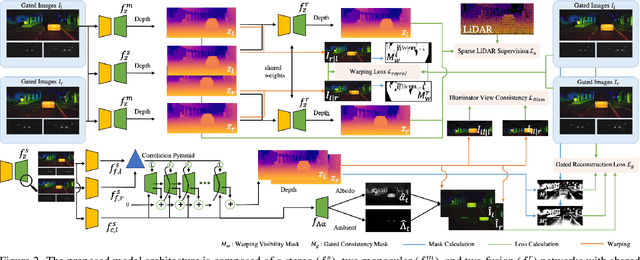
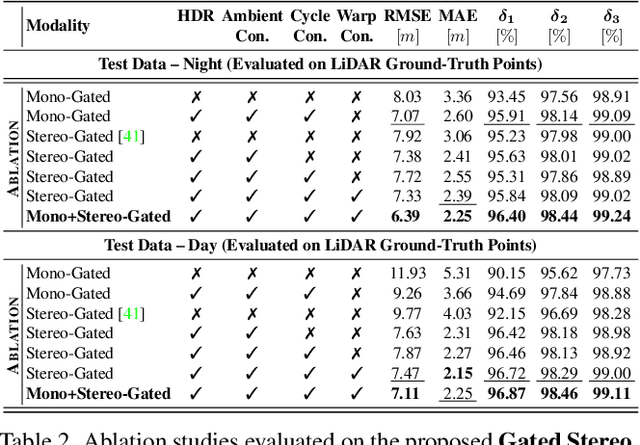
We propose Gated Stereo, a high-resolution and long-range depth estimation technique that operates on active gated stereo images. Using active and high dynamic range passive captures, Gated Stereo exploits multi-view cues alongside time-of-flight intensity cues from active gating. To this end, we propose a depth estimation method with a monocular and stereo depth prediction branch which are combined in a final fusion stage. Each block is supervised through a combination of supervised and gated self-supervision losses. To facilitate training and validation, we acquire a long-range synchronized gated stereo dataset for automotive scenarios. We find that the method achieves an improvement of more than 50 % MAE compared to the next best RGB stereo method, and 74 % MAE to existing monocular gated methods for distances up to 160 m. Our code,models and datasets are available here.
S$^3$Track: Self-supervised Tracking with Soft Assignment Flow
May 17, 2023



In this work, we study self-supervised multiple object tracking without using any video-level association labels. We propose to cast the problem of multiple object tracking as learning the frame-wise associations between detections in consecutive frames. To this end, we propose differentiable soft object assignment for object association, making it possible to learn features tailored to object association with differentiable end-to-end training. With this training approach in hand, we develop an appearance-based model for learning instance-aware object features used to construct a cost matrix based on the pairwise distances between the object features. We train our model using temporal and multi-view data, where we obtain association pseudo-labels using optical flow and disparity information. Unlike most self-supervised tracking methods that rely on pretext tasks for learning the feature correspondences, our method is directly optimized for cross-object association in complex scenarios. As such, the proposed method offers a reidentification-based MOT approach that is robust to training hyperparameters and does not suffer from local minima, which are a challenge in self-supervised methods. We evaluate our proposed model on the KITTI, Waymo, nuScenes, and Argoverse datasets, consistently improving over other unsupervised methods ($7.8\%$ improvement in association accuracy on nuScenes).
The Differentiable Lens: Compound Lens Search over Glass Surfaces and Materials for Object Detection
Dec 08, 2022Most camera lens systems are designed in isolation, separately from downstream computer vision methods. Recently, joint optimization approaches that design lenses alongside other components of the image acquisition and processing pipeline -- notably, downstream neural networks -- have achieved improved imaging quality or better performance on vision tasks. However, these existing methods optimize only a subset of lens parameters and cannot optimize glass materials given their categorical nature. In this work, we develop a differentiable spherical lens simulation model that accurately captures geometrical aberrations. We propose an optimization strategy to address the challenges of lens design -- notorious for non-convex loss function landscapes and many manufacturing constraints -- that are exacerbated in joint optimization tasks. Specifically, we introduce quantized continuous glass variables to facilitate the optimization and selection of glass materials in an end-to-end design context, and couple this with carefully designed constraints to support manufacturability. In automotive object detection, we show improved detection performance over existing designs even when simplifying designs to two- or three-element lenses, despite significantly degrading the image quality. Code and optical designs will be made publicly available.
Gated2Gated: Self-Supervised Depth Estimation from Gated Images
Dec 04, 2021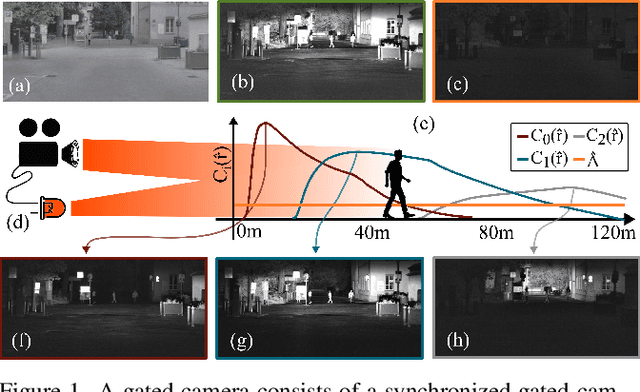
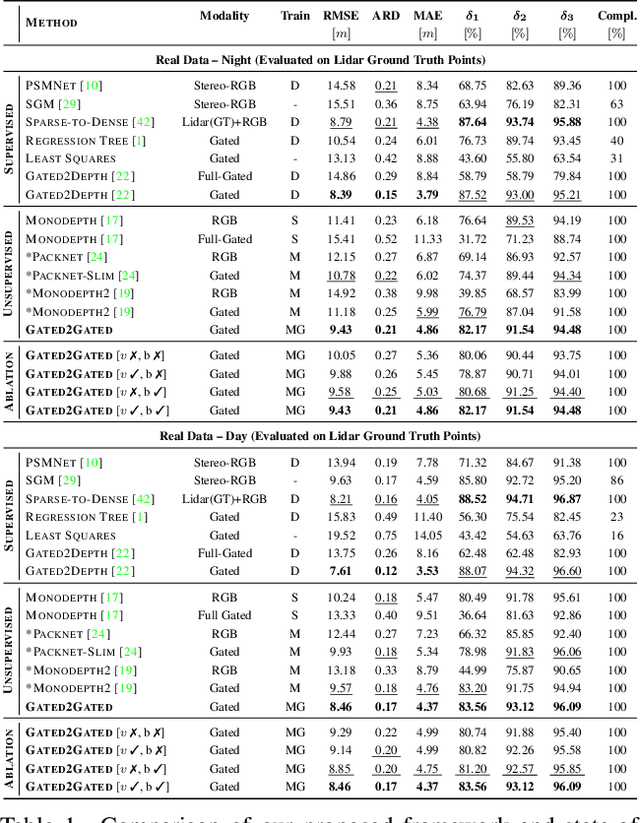
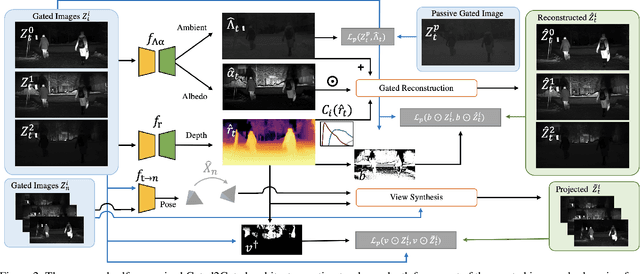
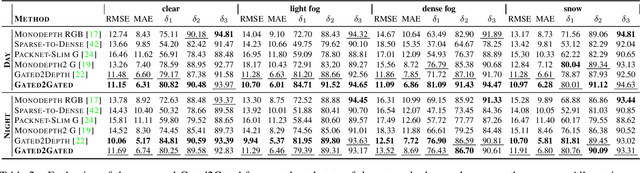
Gated cameras hold promise as an alternative to scanning LiDAR sensors with high-resolution 3D depth that is robust to back-scatter in fog, snow, and rain. Instead of sequentially scanning a scene and directly recording depth via the photon time-of-flight, as in pulsed LiDAR sensors, gated imagers encode depth in the relative intensity of a handful of gated slices, captured at megapixel resolution. Although existing methods have shown that it is possible to decode high-resolution depth from such measurements, these methods require synchronized and calibrated LiDAR to supervise the gated depth decoder -- prohibiting fast adoption across geographies, training on large unpaired datasets, and exploring alternative applications outside of automotive use cases. In this work, we fill this gap and propose an entirely self-supervised depth estimation method that uses gated intensity profiles and temporal consistency as a training signal. The proposed model is trained end-to-end from gated video sequences, does not require LiDAR or RGB data, and learns to estimate absolute depth values. We take gated slices as input and disentangle the estimation of the scene albedo, depth, and ambient light, which are then used to learn to reconstruct the input slices through a cyclic loss. We rely on temporal consistency between a given frame and neighboring gated slices to estimate depth in regions with shadows and reflections. We experimentally validate that the proposed approach outperforms existing supervised and self-supervised depth estimation methods based on monocular RGB and stereo images, as well as supervised methods based on gated images.
Adversarial Imaging Pipelines
Feb 19, 2021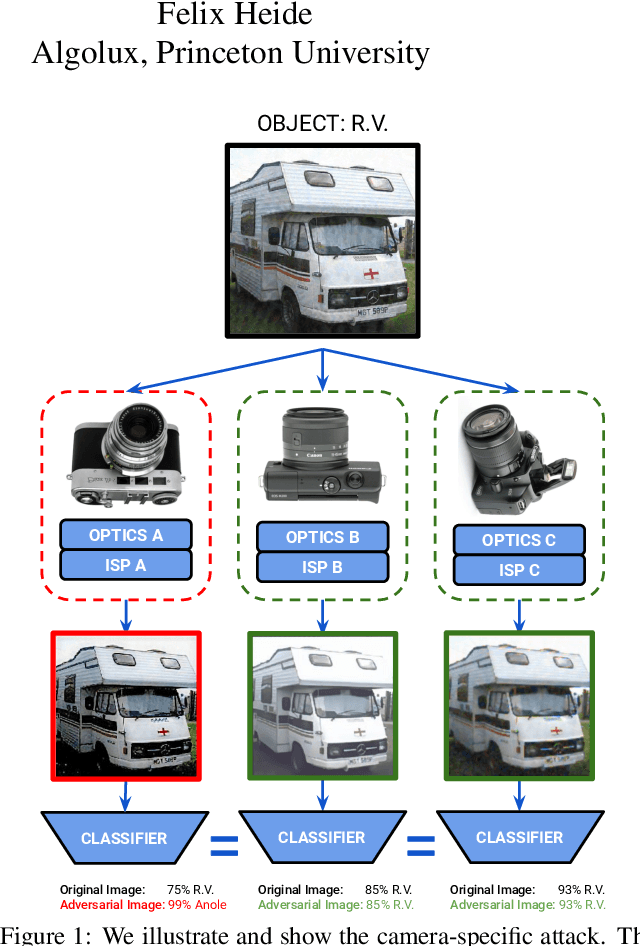
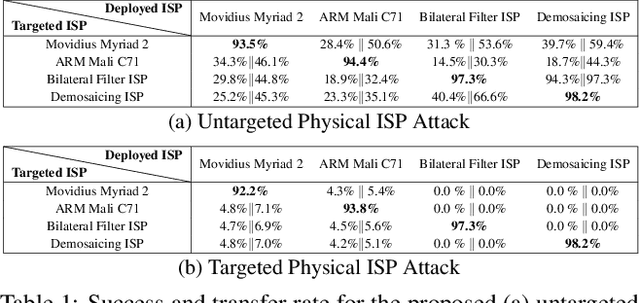
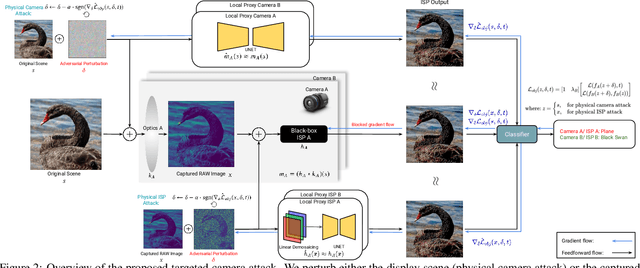

Adversarial attacks play an essential role in understanding deep neural network predictions and improving their robustness. Existing attack methods aim to deceive convolutional neural network (CNN)-based classifiers by manipulating RGB images that are fed directly to the classifiers. However, these approaches typically neglect the influence of the camera optics and image processing pipeline (ISP) that produce the network inputs. ISPs transform RAW measurements to RGB images and traditionally are assumed to preserve adversarial patterns. However, these low-level pipelines can, in fact, destroy, introduce or amplify adversarial patterns that can deceive a downstream detector. As a result, optimized patterns can become adversarial for the classifier after being transformed by a certain camera ISP and optic but not for others. In this work, we examine and develop such an attack that deceives a specific camera ISP while leaving others intact, using the same down-stream classifier. We frame camera-specific attacks as a multi-task optimization problem, relying on a differentiable approximation for the ISP itself. We validate the proposed method using recent state-of-the-art automotive hardware ISPs, achieving 92% fooling rate when attacking a specific ISP. We demonstrate physical optics attacks with 90% fooling rate for a specific camera lenses.
Gated3D: Monocular 3D Object Detection From Temporal Illumination Cues
Feb 06, 2021
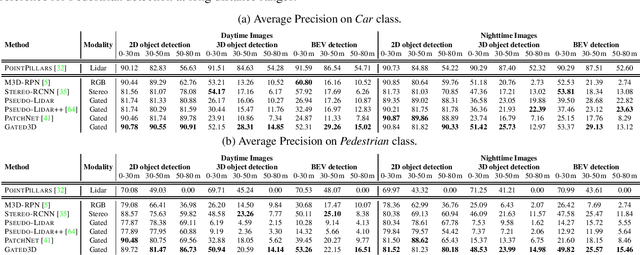
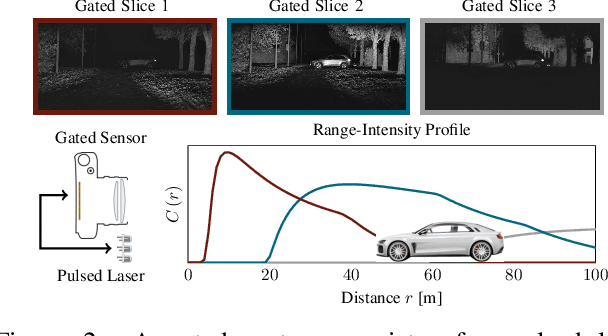
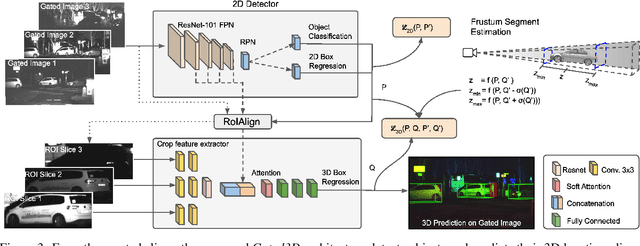
Today's state-of-the-art methods for 3D object detection are based on lidar, stereo, or monocular cameras. Lidar-based methods achieve the best accuracy, but have a large footprint, high cost, and mechanically-limited angular sampling rates, resulting in low spatial resolution at long ranges. Recent approaches based on low-cost monocular or stereo cameras promise to overcome these limitations but struggle in low-light or low-contrast regions as they rely on passive CMOS sensors. In this work, we propose a novel 3D object detection modality that exploits temporal illumination cues from a low-cost monocular gated imager. We propose a novel deep detector architecture, Gated3D, that is tailored to temporal illumination cues from three gated images. Gated images allow us to exploit mature 2D object feature extractors that guide the 3D predictions through a frustum segment estimation. We assess the proposed method on a novel 3D detection dataset that includes gated imagery captured in over 10,000 km of driving data. We validate that our method outperforms state-of-the-art monocular and stereo approaches at long distances. We will release our code and dataset, opening up a new sensor modality as an avenue to replace lidar in autonomous driving.
Neural Scene Graphs for Dynamic Scenes
Nov 20, 2020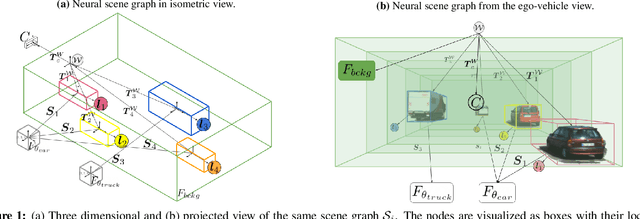
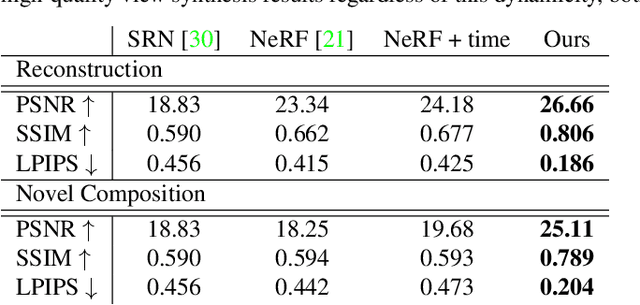
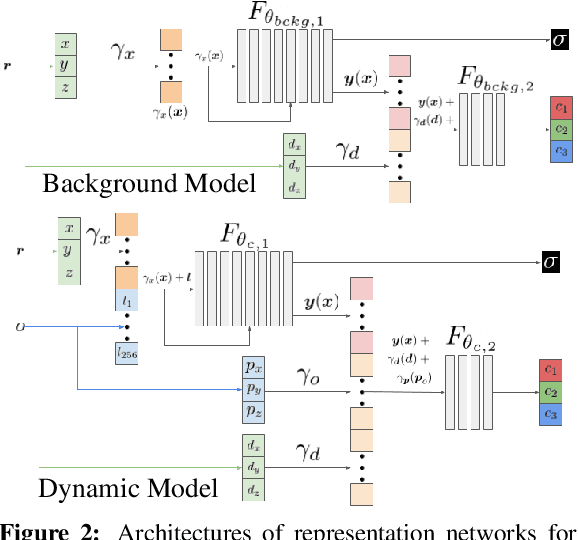

Recent implicit neural rendering methods have demonstrated that it is possible to learn accurate view synthesis for complex scenes by predicting their volumetric density and color supervised solely by a set of RGB images. However, existing methods are restricted to learning efficient interpolations of static scenes that encode all scene objects into a single neural network, lacking the ability to represent dynamic scenes and decompositions into individual scene objects. In this work, we present the first neural rendering method that decomposes dynamic scenes into scene graphs. We propose a learned scene graph representation, which encodes object transformation and radiance, to efficiently render novel arrangements and views of the scene. To this end, we learn implicitly encoded scenes, combined with a jointly learned latent representation to describe objects with a single implicit function. We assess the proposed method on synthetic and real automotive data, validating that our approach learns dynamic scenes - only by observing a video of this scene - and allows for rendering novel photo-realistic views of novel scene compositions with unseen sets of objects at unseen poses.
Pix2Shape: Towards Unsupervised Learning of 3D Scenes from Images using a View-based Representation
Apr 17, 2020


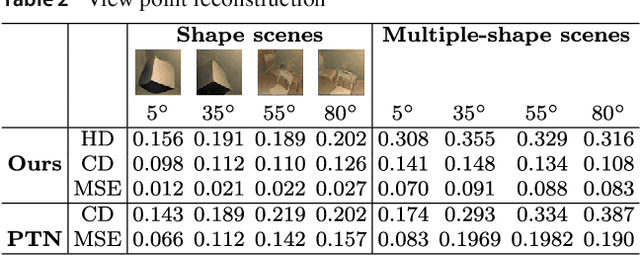
We infer and generate three-dimensional (3D) scene information from a single input image and without supervision. This problem is under-explored, with most prior work relying on supervision from, e.g., 3D ground-truth, multiple images of a scene, image silhouettes or key-points. We propose Pix2Shape, an approach to solve this problem with four components: (i) an encoder that infers the latent 3D representation from an image, (ii) a decoder that generates an explicit 2.5D surfel-based reconstruction of a scene from the latent code (iii) a differentiable renderer that synthesizes a 2D image from the surfel representation, and (iv) a critic network trained to discriminate between images generated by the decoder-renderer and those from a training distribution. Pix2Shape can generate complex 3D scenes that scale with the view-dependent on-screen resolution, unlike representations that capture world-space resolution, i.e., voxels or meshes. We show that Pix2Shape learns a consistent scene representation in its encoded latent space and that the decoder can then be applied to this latent representation in order to synthesize the scene from a novel viewpoint. We evaluate Pix2Shape with experiments on the ShapeNet dataset as well as on a novel benchmark we developed, called 3D-IQTT, to evaluate models based on their ability to enable 3d spatial reasoning. Qualitative and quantitative evaluation demonstrate Pix2Shape's ability to solve scene reconstruction, generation, and understanding tasks.
* This is a pre-print of an article published in International Journal of Computer Vision. The final authenticated version is available online at: https://doi.org/10.1007/s11263-020-01322-1
Seeing Around Street Corners: Non-Line-of-Sight Detection and Tracking In-the-Wild Using Doppler Radar
Dec 13, 2019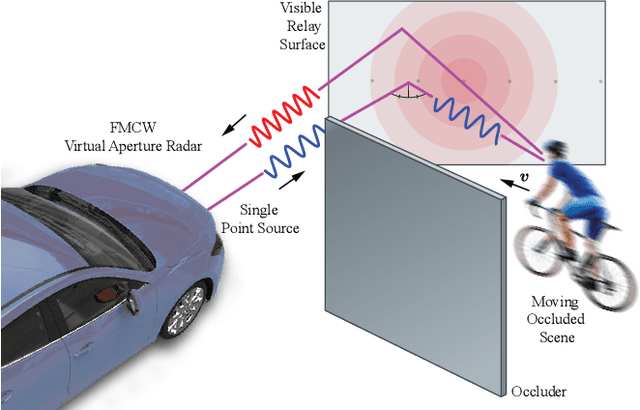
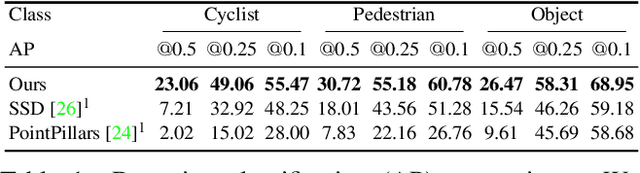

Conventional sensor systems record information about directly visible objects, whereas occluded scene components are considered lost in the measurement process. Nonline-of-sight (NLOS) methods try to recover such hidden objects from their indirect reflections - faint signal components, traditionally treated as measurement noise. Existing NLOS approaches struggle to record these low-signal components outside the lab, and do not scale to large-scale outdoor scenes and high-speed motion, typical in automotive scenarios. Especially optical NLOS is fundamentally limited by the quartic intensity falloff of diffuse indirect reflections. In this work, we depart from visible-wavelength approaches and demonstrate detection, classification, and tracking of hidden objects in large-scale dynamic scenes using a Doppler radar which can be foreseen as a low-cost serial product in the near future. To untangle noisy indirect and direct reflections, we learn from temporal sequences of Doppler velocity and position measurements, which we fuse in a joint NLOS detection and tracking network over time. We validate the approach on in-the-wild automotive scenes, including sequences of parked cars or house facades as indirect reflectors, and demonstrate low-cost, real-time NLOS in dynamic automotive environments.
Seeing Through Fog Without Seeing Fog: Deep Sensor Fusion in the Absence of Labeled Training Data
Feb 24, 2019
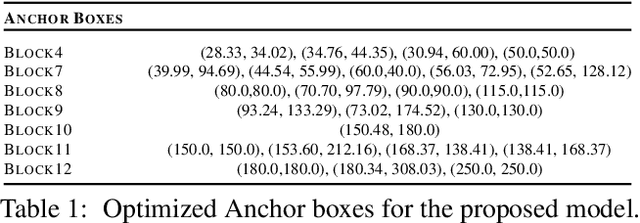
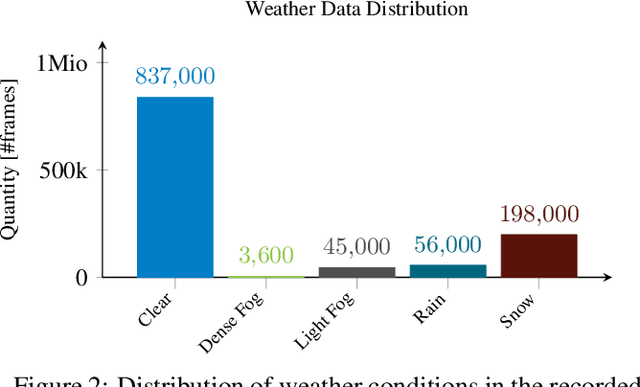
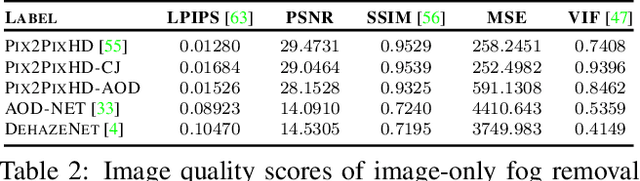
The fusion of color and lidar data plays a critical role in object detection for autonomous vehicles, which base their decision making on these inputs. While existing methods exploit redundant and complimentary information under good imaging conditions, they fail to do this in adverse weather and imaging conditions where the sensory streams can be asymmetrically distorted. These rare "edge-case" scenarios are not represented in available data sets, and existing fusion architectures are not designed to handle severe asymmetric distortions. We present a deep fusion architecture that allows for robust fusion in fog and snow without having large labeled training data available for these scenarios. Departing from proposal-level fusion, we propose a real-time single-shot model that adaptively fuses features driven by temporal coherence of the distortions. We validate the proposed method, trained on clean data, in simulation and on unseen conditions of in-the-wild driving scenarios.