 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Mesh Diffusion
Dec 01, 2023Given a 3D mesh with a UV parameterization, we introduce a novel approach to generating textures from text prompts. While prior work uses optimization from Text-to-Image Diffusion models to generate textures and geometry, this is slow and requires significant compute resources. Alternatively, there are projection based approaches that use the same Text-to-Image models that paint images onto a mesh, but lack consistency at different viewing angles, we propose a method that uses a single Depth-to-Image diffusion network, and generates a single consistent texture when rendered on the 3D surface by first unifying multiple 2D image's diffusion paths, and hoisting that to 3D with MultiDiffusion~\cite{multidiffusion}. We demonstrate our approach on a dataset containing 30 meshes, taking approximately 5 minutes per mesh. To evaluate the quality of our approach, we use CLIP-score~\cite{clipscore} and Frechet Inception Distance (FID)~\cite{frechet} to evaluate the quality of the rendering, and show our improvement over prior work.
Structural Dropout for Model Width Compression
May 13, 2022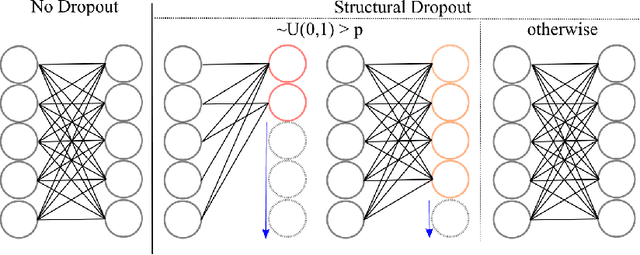

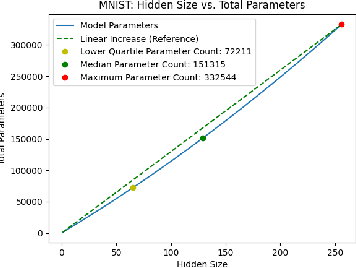
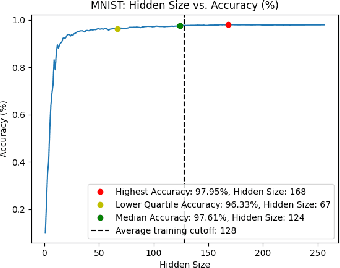
Existing ML models are known to be highly over-parametrized, and use significantly more resources than required for a given task. Prior work has explored compressing models offline, such as by distilling knowledge from larger models into much smaller ones. This is effective for compression, but does not give an empirical method for measuring how much the model can be compressed, and requires additional training for each compressed model. We propose a method that requires only a single training session for the original model and a set of compressed models. The proposed approach is a "structural" dropout that prunes all elements in the hidden state above a randomly chosen index, forcing the model to learn an importance ordering over its features. After learning this ordering, at inference time unimportant features can be pruned while retaining most accuracy, reducing parameter size significantly. In this work, we focus on Structural Dropout for fully-connected layers, but the concept can be applied to any kind of layer with unordered features, such as convolutional or attention layers. Structural Dropout requires no additional pruning/retraining, but requires additional validation for each possible hidden sizes. At inference time, a non-expert can select a memory versus accuracy trade-off that best suits their needs, across a wide range of highly compressed versus more accurate models.
Continuous Dynamic-NeRF: Spline-NeRF
Mar 25, 2022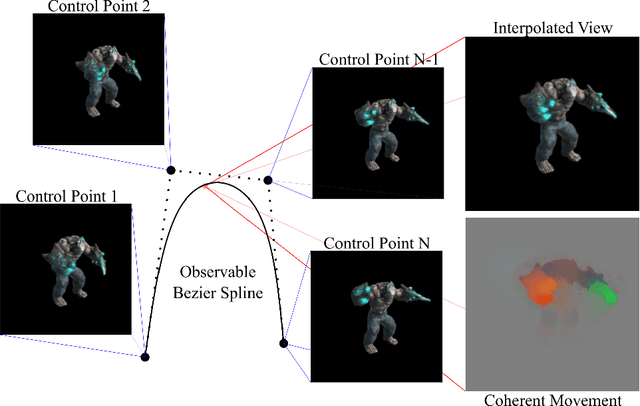
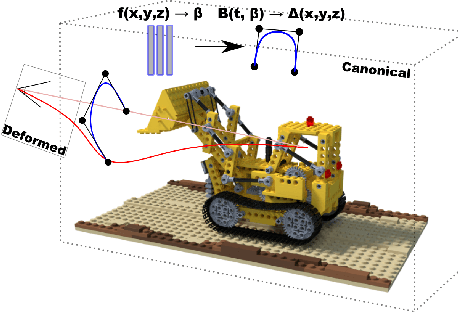
The problem of reconstructing continuous functions over time is important for problems such as reconstructing moving scenes, and interpolating between time steps. Previous approaches that use deep-learning rely on regularization to ensure that reconstructions are approximately continuous, which works well on short sequences. As sequence length grows, though, it becomes more difficult to regularize, and it becomes less feasible to learn only through regularization. We propose a new architecture for function reconstruction based on classical Bezier splines, which ensures $C^0$ and $C^1$-continuity, where $C^0$ continuity is that $\forall c:\lim\limits_{x\to c} f(x) = f(c)$, or more intuitively that there are no breaks at any point in the function. In order to demonstrate our architecture, we reconstruct dynamic scenes using Neural Radiance Fields, but hope it is clear that our approach is general and can be applied to a variety of problems. We recover a Bezier spline $B(\beta, t\in[0,1])$, parametrized by the control points $\beta$. Using Bezier splines ensures reconstructions have $C^0$ and $C^1$ continuity, allowing for guaranteed interpolation over time. We reconstruct $\beta$ with a multi-layer perceptron (MLP), blending machine learning with classical animation techniques. All code is available at https://github.com/JulianKnodt/nerf_atlas, and datasets are from prior work.
Neural Ray-Tracing: Learning Surfaces and Reflectance for Relighting and View Synthesis
Apr 28, 2021
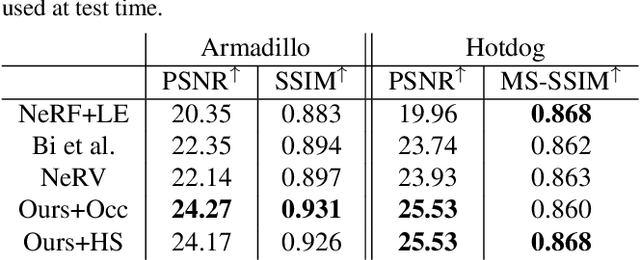
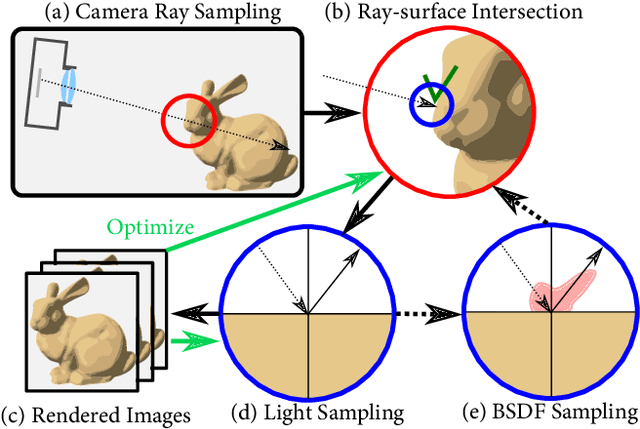
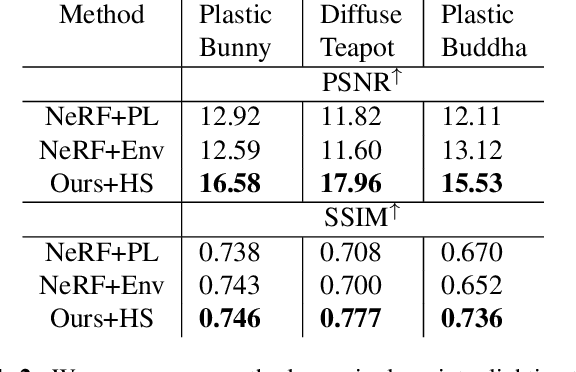
Recent neural rendering methods have demonstrated accurate view interpolation by predicting volumetric density and color with a neural network. Although such volumetric representations can be supervised on static and dynamic scenes, existing methods implicitly bake the complete scene light transport into a single neural network for a given scene, including surface modeling, bidirectional scattering distribution functions, and indirect lighting effects. In contrast to traditional rendering pipelines, this prohibits changing surface reflectance, illumination, or composing other objects in the scene. In this work, we explicitly model the light transport between scene surfaces and we rely on traditional integration schemes and the rendering equation to reconstruct a scene. The proposed method allows BSDF recovery with unknown light conditions and classic light transports such as pathtracing. By learning decomposed transport with surface representations established in conventional rendering methods, the method naturally facilitates editing shape, reflectance, lighting and scene composition. The method outperforms NeRV for relighting under known lighting conditions, and produces realistic reconstructions for relit and edited scenes. We validate the proposed approach for scene editing, relighting and reflectance estimation learned from synthetic and captured views on a subset of NeRV's datasets.
Neural Scene Graphs for Dynamic Scenes
Nov 20, 2020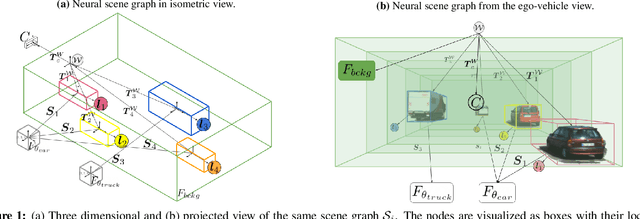
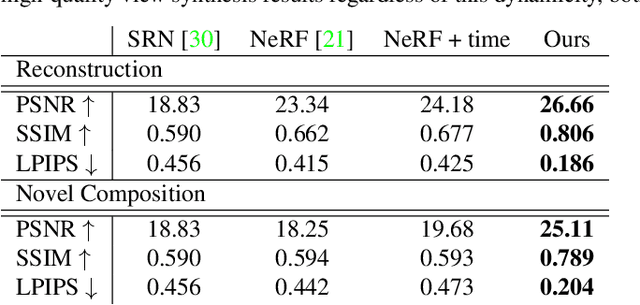
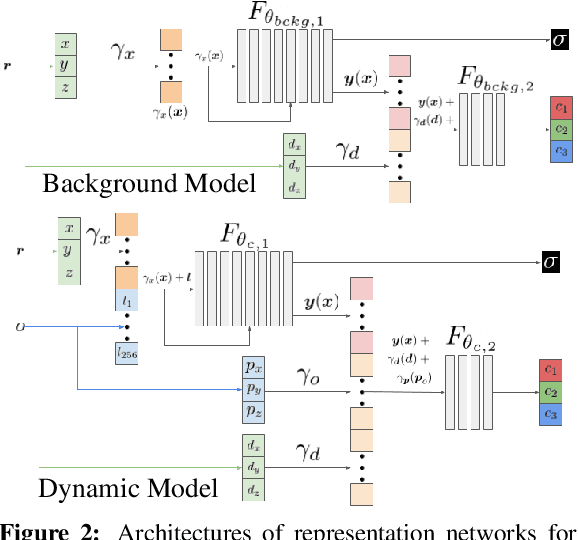

Recent implicit neural rendering methods have demonstrated that it is possible to learn accurate view synthesis for complex scenes by predicting their volumetric density and color supervised solely by a set of RGB images. However, existing methods are restricted to learning efficient interpolations of static scenes that encode all scene objects into a single neural network, lacking the ability to represent dynamic scenes and decompositions into individual scene objects. In this work, we present the first neural rendering method that decomposes dynamic scenes into scene graphs. We propose a learned scene graph representation, which encodes object transformation and radiance, to efficiently render novel arrangements and views of the scene. To this end, we learn implicitly encoded scenes, combined with a jointly learned latent representation to describe objects with a single implicit function. We assess the proposed method on synthetic and real automotive data, validating that our approach learns dynamic scenes - only by observing a video of this scene - and allows for rendering novel photo-realistic views of novel scene compositions with unseen sets of objects at unseen poses.