 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldFlow3D: Flowing Through 3D Distributions for Unbounded World Generation
Mar 31, 2026Unbounded 3D world generation is emerging as a foundational task for scene modeling in computer vision, graphics, and robotics. In this work, we present WorldFlow3D, a novel method capable of generating unbounded 3D worlds. Building upon a foundational property of flow matching - namely, defining a path of transport between two data distributions - we model 3D generation more generally as a problem of flowing through 3D data distributions, not limited to conditional denoising. We find that our latent-free flow approach generates causal and accurate 3D structure, and can use this as an intermediate distribution to guide the generation of more complex structure and high-quality texture - all while converging more rapidly than existing methods. We enable controllability over generated scenes with vectorized scene layout conditions for geometric structure control and visual texture control through scene attributes. We confirm the effectiveness of WorldFlow3D on both real outdoor driving scenes and synthetic indoor scenes, validating cross-domain generalizability and high-quality generation on real data distributions. We confirm favorable scene generation fidelity over approaches in all tested settings for unbounded scene generation. For more, see https://light.princeton.edu/worldflow3d.
ChopGrad: Pixel-Wise Losses for Latent Video Diffusion via Truncated Backpropagation
Mar 18, 2026Recent video diffusion models achieve high-quality generation through recurrent frame processing where each frame generation depends on previous frames. However, this recurrent mechanism means that training such models in the pixel domain incurs prohibitive memory costs, as activations accumulate across the entire video sequence. This fundamental limitation also makes fine-tuning these models with pixel-wise losses computationally intractable for long or high-resolution videos. This paper introduces ChopGrad, a truncated backpropagation scheme for video decoding, limiting gradient computation to local frame windows while maintaining global consistency. We provide a theoretical analysis of this approximation and show that it enables efficient fine-tuning with frame-wise losses. ChopGrad reduces training memory from scaling linearly with the number of video frames (full backpropagation) to constant memory, and compares favorably to existing state-of-the-art video diffusion models across a suite of conditional video generation tasks with pixel-wise losses, including video super-resolution, video inpainting, video enhancement of neural-rendered scenes, and controlled driving video generation.
LSD-3D: Large-Scale 3D Driving Scene Generation with Geometry Grounding
Aug 26, 2025Large-scale scene data is essential for training and testing in robot learning. Neural reconstruction methods have promised the capability of reconstructing large physically-grounded outdoor scenes from captured sensor data. However, these methods have baked-in static environments and only allow for limited scene control -- they are functionally constrained in scene and trajectory diversity by the captures from which they are reconstructed. In contrast, generating driving data with recent image or video diffusion models offers control, however, at the cost of geometry grounding and causality. In this work, we aim to bridge this gap and present a method that directly generates large-scale 3D driving scenes with accurate geometry, allowing for causal novel view synthesis with object permanence and explicit 3D geometry estimation. The proposed method combines the generation of a proxy geometry and environment representation with score distillation from learned 2D image priors. We find that this approach allows for high controllability, enabling the prompt-guided geometry and high-fidelity texture and structure that can be conditioned on map layouts -- producing realistic and geometrically consistent 3D generations of complex driving scenes.
VERDI: VLM-Embedded Reasoning for Autonomous Driving
May 21, 2025While autonomous driving (AD) stacks struggle with decision making under partial observability and real-world complexity, human drivers are capable of commonsense reasoning to make near-optimal decisions with limited information. Recent work has attempted to leverage finetuned Vision-Language Models (VLMs) for trajectory planning at inference time to emulate human behavior. Despite their success in benchmark evaluations, these methods are often impractical to deploy (a 70B parameter VLM inference at merely 8 tokens per second requires more than 160G of memory), and their monolithic network structure prohibits safety decomposition. To bridge this gap, we propose VLM-Embedded Reasoning for autonomous Driving (VERDI), a training-time framework that distills the reasoning process and commonsense knowledge of VLMs into the AD stack. VERDI augments modular differentiable end-to-end (e2e) AD models by aligning intermediate module outputs at the perception, prediction, and planning stages with text features explaining the driving reasoning process produced by VLMs. By encouraging alignment in latent space, \textsc{VERDI} enables the modular AD stack to internalize structured reasoning, without incurring the inference-time costs of large VLMs. We demonstrate the effectiveness of our method on the NuScenes dataset and find that VERDI outperforms existing e2e methods that do not embed reasoning by 10% in $\ell_{2}$ distance, while maintaining high inference speed.
Inverse Neural Rendering for Explainable Multi-Object Tracking
Apr 18, 2024



Today, most methods for image understanding tasks rely on feed-forward neural networks. While this approach has allowed for empirical accuracy, efficiency, and task adaptation via fine-tuning, it also comes with fundamental disadvantages. Existing networks often struggle to generalize across different datasets, even on the same task. By design, these networks ultimately reason about high-dimensional scene features, which are challenging to analyze. This is true especially when attempting to predict 3D information based on 2D images. We propose to recast 3D multi-object tracking from RGB cameras as an \emph{Inverse Rendering (IR)} problem, by optimizing via a differentiable rendering pipeline over the latent space of pre-trained 3D object representations and retrieve the latents that best represent object instances in a given input image. To this end, we optimize an image loss over generative latent spaces that inherently disentangle shape and appearance properties. We investigate not only an alternate take on tracking but our method also enables examining the generated objects, reasoning about failure situations, and resolving ambiguous cases. We validate the generalization and scaling capabilities of our method by learning the generative prior exclusively from synthetic data and assessing camera-based 3D tracking on the nuScenes and Waymo datasets. Both these datasets are completely unseen to our method and do not require fine-tuning. Videos and code are available at https://light.princeton.edu/inverse-rendering-tracking/.
Neural Point Light Fields
Dec 17, 2021


We introduce Neural Point Light Fields that represent scenes implicitly with a light field living on a sparse point cloud. Combining differentiable volume rendering with learned implicit density representations has made it possible to synthesize photo-realistic images for novel views of small scenes. As neural volumetric rendering methods require dense sampling of the underlying functional scene representation, at hundreds of samples along a ray cast through the volume, they are fundamentally limited to small scenes with the same objects projected to hundreds of training views. Promoting sparse point clouds to neural implicit light fields allows us to represent large scenes effectively with only a single implicit sampling operation per ray. These point light fields are as a function of the ray direction, and local point feature neighborhood, allowing us to interpolate the light field conditioned training images without dense object coverage and parallax. We assess the proposed method for novel view synthesis on large driving scenarios, where we synthesize realistic unseen views that existing implicit approaches fail to represent. We validate that Neural Point Light Fields make it possible to predict videos along unseen trajectories previously only feasible to generate by explicitly modeling the scene.
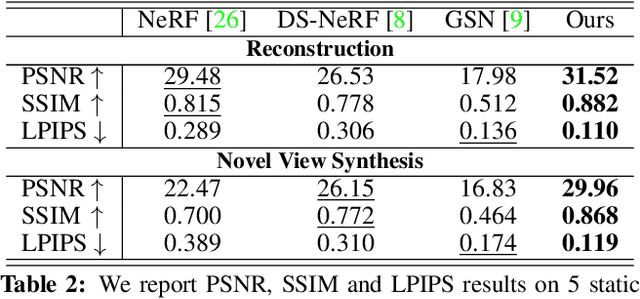
Neural Scene Graphs for Dynamic Scenes
Nov 20, 2020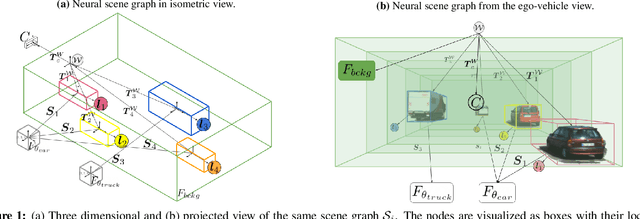
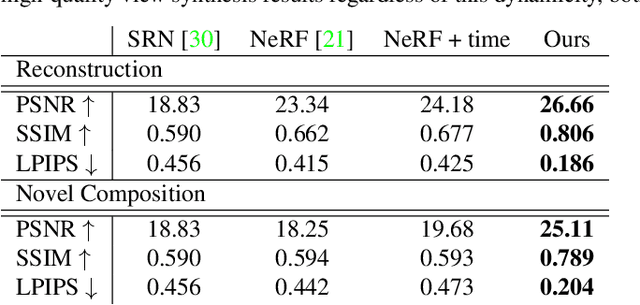
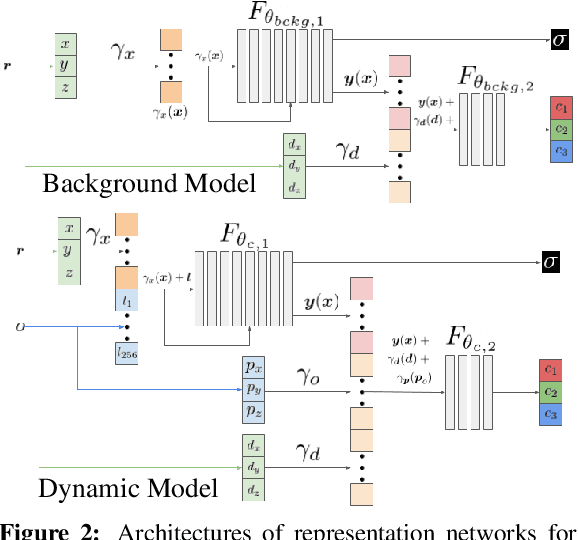

Recent implicit neural rendering methods have demonstrated that it is possible to learn accurate view synthesis for complex scenes by predicting their volumetric density and color supervised solely by a set of RGB images. However, existing methods are restricted to learning efficient interpolations of static scenes that encode all scene objects into a single neural network, lacking the ability to represent dynamic scenes and decompositions into individual scene objects. In this work, we present the first neural rendering method that decomposes dynamic scenes into scene graphs. We propose a learned scene graph representation, which encodes object transformation and radiance, to efficiently render novel arrangements and views of the scene. To this end, we learn implicitly encoded scenes, combined with a jointly learned latent representation to describe objects with a single implicit function. We assess the proposed method on synthetic and real automotive data, validating that our approach learns dynamic scenes - only by observing a video of this scene - and allows for rendering novel photo-realistic views of novel scene compositions with unseen sets of objects at unseen poses.