 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Posterior Sampling to Meaningful Diversity in Image Restoration
Oct 24, 2023
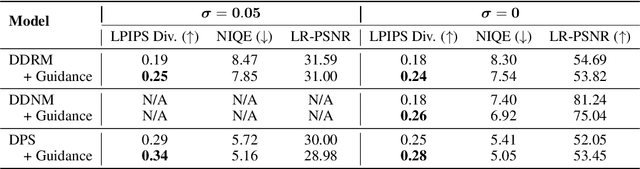
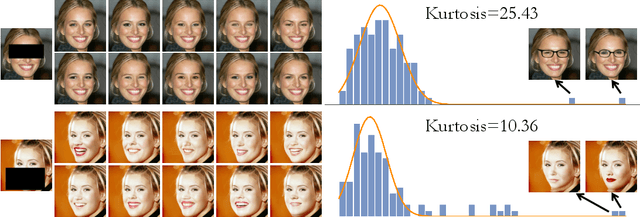
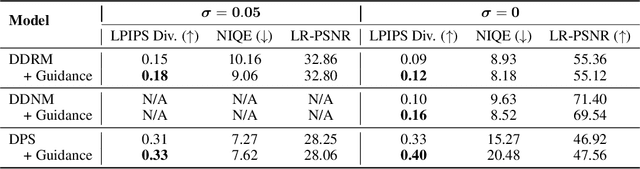
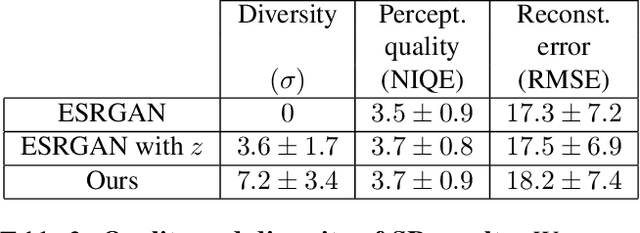
Image restoration problems are typically ill-posed in the sense that each degraded image can be restored in infinitely many valid ways. To accommodate this, many works generate a diverse set of outputs by attempting to randomly sample from the posterior distribution of natural images given the degraded input. Here we argue that this strategy is commonly of limited practical value because of the heavy tail of the posterior distribution. Consider for example inpainting a missing region of the sky in an image. Since there is a high probability that the missing region contains no object but clouds, any set of samples from the posterior would be entirely dominated by (practically identical) completions of sky. However, arguably, presenting users with only one clear sky completion, along with several alternative solutions such as airships, birds, and balloons, would better outline the set of possibilities. In this paper, we initiate the study of meaningfully diverse image restoration. We explore several post-processing approaches that can be combined with any diverse image restoration method to yield semantically meaningful diversity. Moreover, we propose a practical approach for allowing diffusion based image restoration methods to generate meaningfully diverse outputs, while incurring only negligent computational overhead. We conduct extensive user studies to analyze the proposed techniques, and find the strategy of reducing similarity between outputs to be significantly favorable over posterior sampling. Code and examples are available in https://noa-cohen.github.io/MeaningfulDiversityInIR
Kissing to Find a Match: Efficient Low-Rank Permutation Representation
Aug 25, 2023Permutation matrices play a key role in matching and assignment problems across the fields, especially in computer vision and robotics. However, memory for explicitly representing permutation matrices grows quadratically with the size of the problem, prohibiting large problem instances. In this work, we propose to tackle the curse of dimensionality of large permutation matrices by approximating them using low-rank matrix factorization, followed by a nonlinearity. To this end, we rely on the Kissing number theory to infer the minimal rank required for representing a permutation matrix of a given size, which is significantly smaller than the problem size. This leads to a drastic reduction in computation and memory costs, e.g., up to $3$ orders of magnitude less memory for a problem of size $n=20000$, represented using $8.4\times10^5$ elements in two small matrices instead of using a single huge matrix with $4\times 10^8$ elements. The proposed representation allows for accurate representations of large permutation matrices, which in turn enables handling large problems that would have been infeasible otherwise. We demonstrate the applicability and merits of the proposed approach through a series of experiments on a range of problems that involve predicting permutation matrices, from linear and quadratic assignment to shape matching problems.
Neural Volume Super-Resolution
Dec 09, 2022Neural volumetric representations have become a widely adopted model for radiance fields in 3D scenes. These representations are fully implicit or hybrid function approximators of the instantaneous volumetric radiance in a scene, which are typically learned from multi-view captures of the scene. We investigate the new task of neural volume super-resolution - rendering high-resolution views corresponding to a scene captured at low resolution. To this end, we propose a neural super-resolution network that operates directly on the volumetric representation of the scene. This approach allows us to exploit an advantage of operating in the volumetric domain, namely the ability to guarantee consistent super-resolution across different viewing directions. To realize our method, we devise a novel 3D representation that hinges on multiple 2D feature planes. This allows us to super-resolve the 3D scene representation by applying 2D convolutional networks on the 2D feature planes. We validate the proposed method's capability of super-resolving multi-view consistent views both quantitatively and qualitatively on a diverse set of unseen 3D scenes, demonstrating a significant advantage over existing approaches.
DiffusionSDF: Conditional Generative Modeling of Signed Distance Functions
Nov 24, 2022
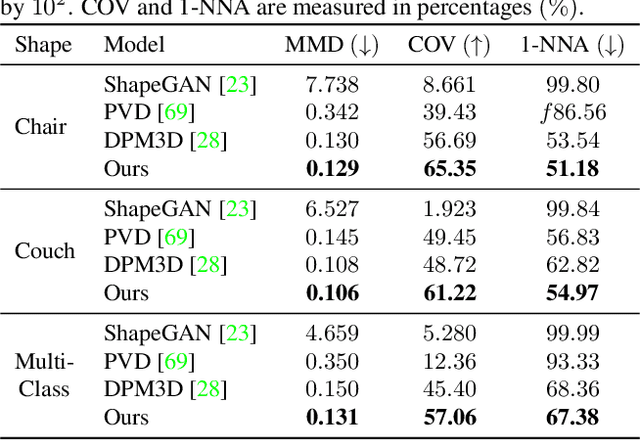
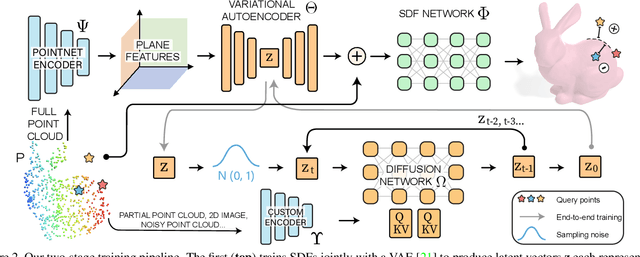

Probabilistic diffusion models have achieved state-of-the-art results for image synthesis, inpainting, and text-to-image tasks. However, they are still in the early stages of generating complex 3D shapes. This work proposes DiffusionSDF, a generative model for shape completion, single-view reconstruction, and reconstruction of real-scanned point clouds. We use neural signed distance functions (SDFs) as our 3D representation to parameterize the geometry of various signals (e.g., point clouds, 2D images) through neural networks. Neural SDFs are implicit functions and diffusing them amounts to learning the reversal of their neural network weights, which we solve using a custom modulation module. Extensive experiments show that our method is capable of both realistic unconditional generation and conditional generation from partial inputs. This work expands the domain of diffusion models from learning 2D, explicit representations, to 3D, implicit representations.
Neural Point Light Fields
Dec 17, 2021


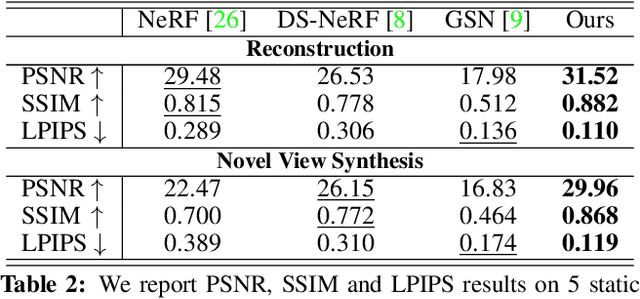
We introduce Neural Point Light Fields that represent scenes implicitly with a light field living on a sparse point cloud. Combining differentiable volume rendering with learned implicit density representations has made it possible to synthesize photo-realistic images for novel views of small scenes. As neural volumetric rendering methods require dense sampling of the underlying functional scene representation, at hundreds of samples along a ray cast through the volume, they are fundamentally limited to small scenes with the same objects projected to hundreds of training views. Promoting sparse point clouds to neural implicit light fields allows us to represent large scenes effectively with only a single implicit sampling operation per ray. These point light fields are as a function of the ray direction, and local point feature neighborhood, allowing us to interpolate the light field conditioned training images without dense object coverage and parallax. We assess the proposed method for novel view synthesis on large driving scenarios, where we synthesize realistic unseen views that existing implicit approaches fail to represent. We validate that Neural Point Light Fields make it possible to predict videos along unseen trajectories previously only feasible to generate by explicitly modeling the scene.
Classification Confidence Estimation with Test-Time Data-Augmentation
Jun 30, 2020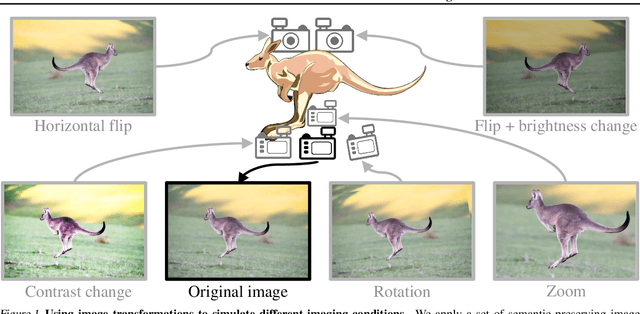
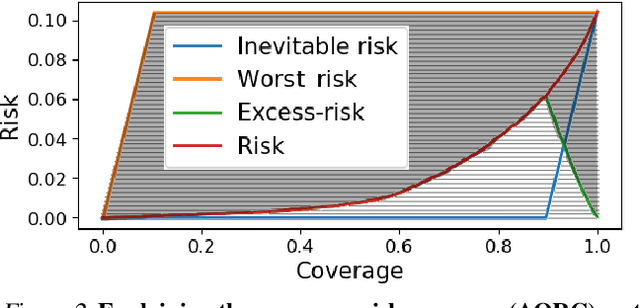
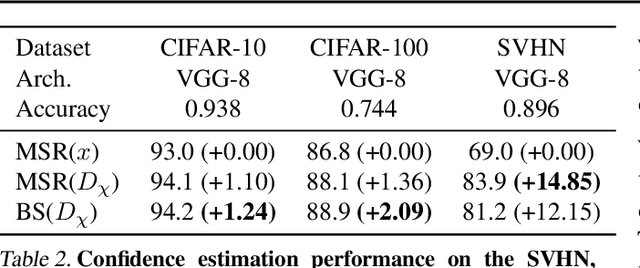
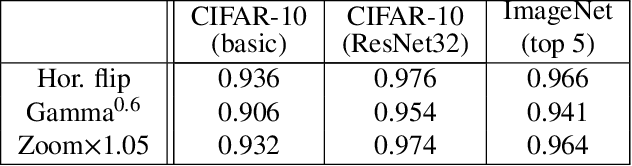
Machine learning plays an increasingly significant role in many aspects of our lives (including medicine, transportation, security, justice and other domains), making the potential consequences of false predictions increasingly devastating. These consequences may be mitigated if we can automatically flag such false predictions and potentially assign them to alternative, more reliable mechanisms, that are possibly more costly and involve human attention. This suggests the task of detecting errors, which we tackle in this paper for the case of visual classification. To this end, we propose a novel approach for classification confidence estimation. We apply a set of semantics-preserving image transformations to the input image, and show how the resulting image sets can be used to estimate confidence in the classifier's prediction. We demonstrate the potential of our approach by extensively evaluating it on a wide variety of classifier architectures and datasets, including ResNext/ImageNet, achieving state of the art performance. This paper constitutes a significant revision of our earlier work in this direction (Bahat & Shakhnarovich, 2018).
Explorable Decoding of Compressed Images
Jun 16, 2020

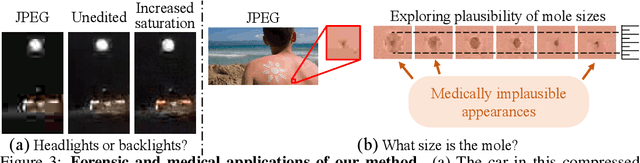

The ever-growing amounts of visual contents captured on a daily basis necessitate the use of lossy compression methods in order to save storage space and transmission bandwidth. While extensive research efforts are devoted to improving compression techniques, every method inevitably discards information. Especially at low bit rates, this information often corresponds to semantically meaningful visual cues, so that decompression involves significant ambiguity. In spite of this fact, existing decompression algorithms typically produce only a single output, and do not allow the viewer to explore the set of images that map to the given compressed code. Recently, explorable image restoration has been studied in the context of super-resolution. In this work, we propose to take this idea to the realm of image decompression. Specifically, we develop a novel deep-network based decoder architecture for the ubiquitous JPEG standard, which allows traversing the set of decompressed images that are consistent with the compressed input code. To allow for simple user interaction, we also develop a graphical user interface that comprises several intuitive exploration and editing tools. We exemplify our framework on graphical, medical and forensic use cases, demonstrating its wide range of potential applications.
Explorable Super Resolution
Dec 04, 2019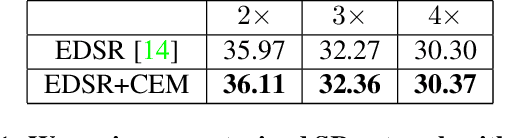


Single image super resolution (SR) has seen major performance leaps in recent years. However, existing methods do not allow exploring the infinitely many plausible reconstructions that might have given rise to the observed low-resolution (LR) image. These different explanations to the LR image may dramatically vary in their textures and fine details, and may often encode completely different semantic information. In this paper, we introduce the task of explorable super resolution. We propose a framework comprising a graphical user interface with a neural network backend, allowing editing the SR output so as to explore the abundance of plausible HR explanations to the LR input. At the heart of our method is a novel module that can wrap any existing SR network, analytically guaranteeing that its SR outputs would precisely match the LR input, when downsampled. Besides its importance in our setting, this module is guaranteed to decrease the reconstruction error of any SR network it wraps, and can be used to cope with blur kernels that are different from the one the network was trained for. We illustrate our approach in a variety of use cases, ranging from medical imaging and forensics, to graphics.
Natural and Adversarial Error Detection using Invariance to Image Transformations
Feb 01, 2019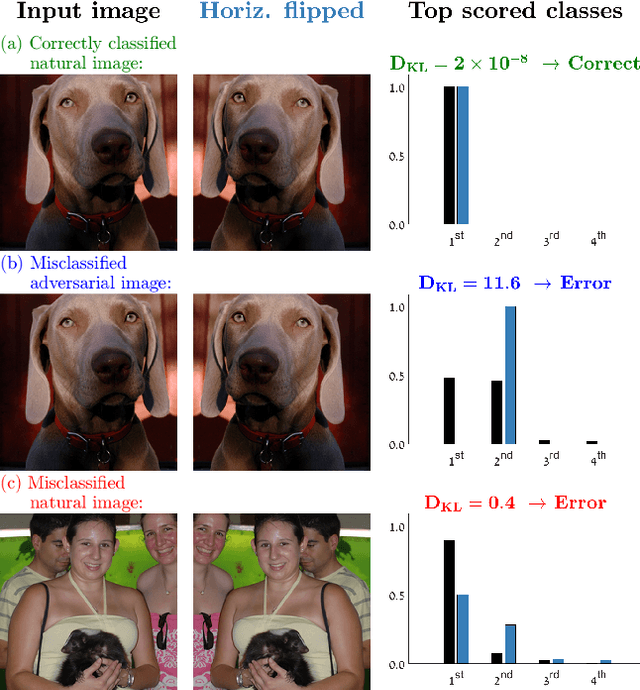
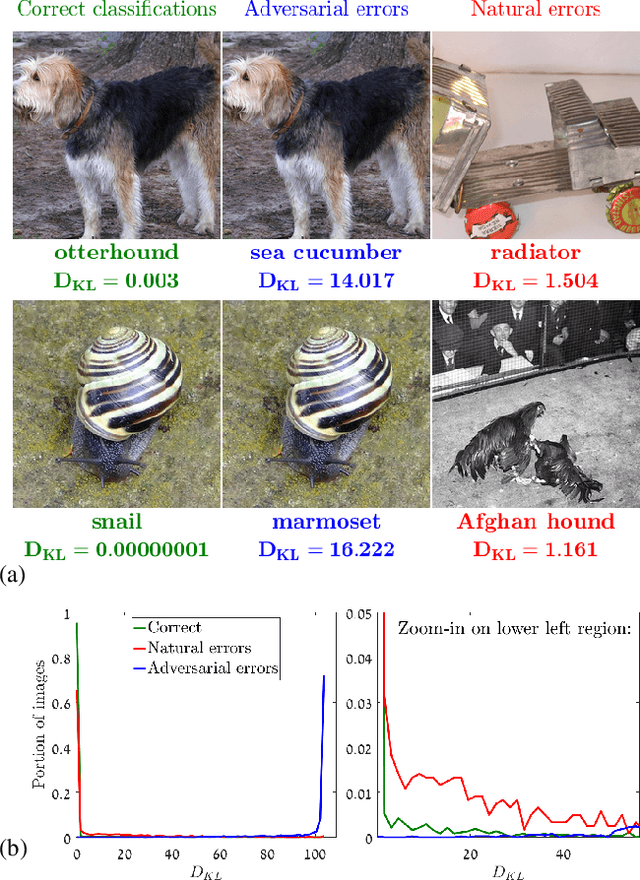
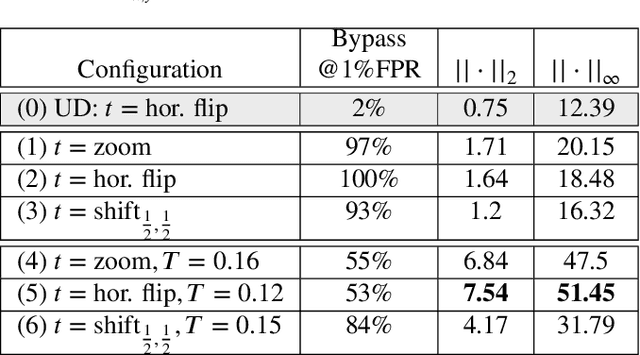
We propose an approach to distinguish between correct and incorrect image classifications. Our approach can detect misclassifications which either occur $\it{unintentionally}$ ("natural errors"), or due to $\it{intentional~adversarial~attacks}$ ("adversarial errors"), both in a single $\it{unified~framework}$. Our approach is based on the observation that correctly classified images tend to exhibit robust and consistent classifications under certain image transformations (e.g., horizontal flip, small image translation, etc.). In contrast, incorrectly classified images (whether due to adversarial errors or natural errors) tend to exhibit large variations in classification results under such transformations. Our approach does not require any modifications or retraining of the classifier, hence can be applied to any pre-trained classifier. We further use state of the art targeted adversarial attacks to demonstrate that even when the adversary has full knowledge of our method, the adversarial distortion needed for bypassing our detector is $\it{no~longer~imperceptible~to~the~human~eye}$. Our approach obtains state-of-the-art results compared to previous adversarial detection methods, surpassing them by a large margin.
Confidence from Invariance to Image Transformations
Apr 02, 2018
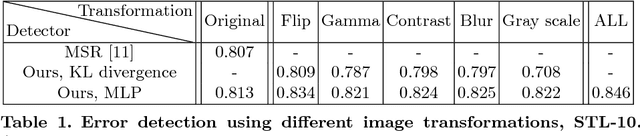

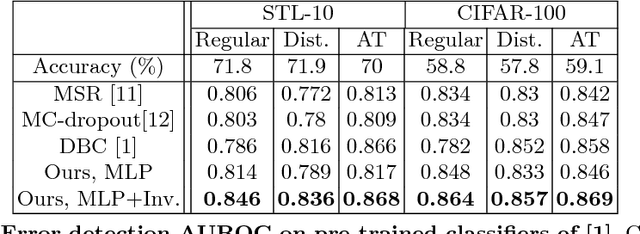
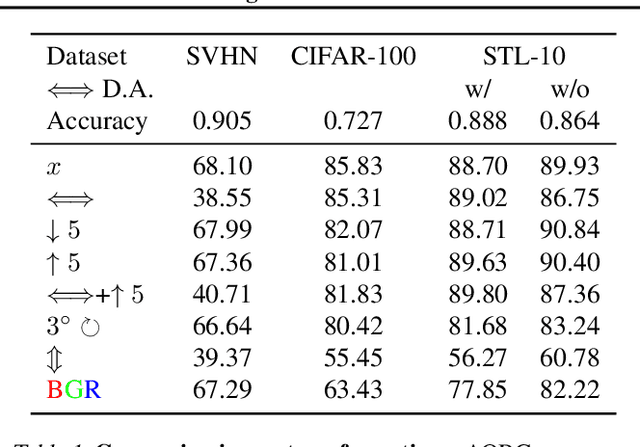
We develop a technique for automatically detecting the classification errors of a pre-trained visual classifier. Our method is agnostic to the form of the classifier, requiring access only to classifier responses to a set of inputs. We train a parametric binary classifier (error/correct) on a representation derived from a set of classifier responses generated from multiple copies of the same input, each subject to a different natural image transformation. Thus, we establish a measure of confidence in classifier's decision by analyzing the invariance of its decision under various transformations. In experiments with multiple data sets (STL-10,CIFAR-100,ImageNet) and classifiers, we demonstrate new state of the art for the error detection task. In addition, we apply our technique to novelty detection scenarios, where we also demonstrate state of the art results.