 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Inpainting for Real-Time 3D Streaming in Sparse Multi-Camera Setups
Mar 05, 2026High-quality 3D streaming from multiple cameras is crucial for immersive experiences in many AR/VR applications. The limited number of views - often due to real-time constraints - leads to missing information and incomplete surfaces in the rendered images. Existing approaches typically rely on simple heuristics for the hole filling, which can result in inconsistencies or visual artifacts. We propose to complete the missing textures using a novel, application-targeted inpainting method independent of the underlying representation as an image-based post-processing step after the novel view rendering. The method is designed as a standalone module compatible with any calibrated multi-camera system. For this we introduce a multi-view aware, transformer-based network architecture using spatio-temporal embeddings to ensure consistency across frames while preserving fine details. Additionally, our resolution-independent design allows adaptation to different camera setups, while an adaptive patch selection strategy balances inference speed and quality, allowing real-time performance. We evaluate our approach against state-of-the-art inpainting techniques under the same real-time constraints and demonstrate that our model achieves the best trade-off between quality and speed, outperforming competitors in both image and video-based metrics.
Neu-PiG: Neural Preconditioned Grids for Fast Dynamic Surface Reconstruction on Long Sequences
Feb 25, 2026Temporally consistent surface reconstruction of dynamic 3D objects from unstructured point cloud data remains challenging, especially for very long sequences. Existing methods either optimize deformations incrementally, risking drift and requiring long runtimes, or rely on complex learned models that demand category-specific training. We present Neu-PiG, a fast deformation optimization method based on a novel preconditioned latent-grid encoding that distributes spatial features parameterized on the position and normal direction of a keyframe surface. Our method encodes entire deformations across all time steps at various spatial scales into a multi-resolution latent grid, parameterized by the position and normal direction of a reference surface from a single keyframe. This latent representation is then augmented for time modulation and decoded into per-frame 6-DoF deformations via a lightweight multilayer perceptron (MLP). To achieve high-fidelity, drift-free surface reconstructions in seconds, we employ Sobolev preconditioning during gradient-based training of the latent space, completely avoiding the need for any explicit correspondences or further priors. Experiments across diverse human and animal datasets demonstrate that Neu-PiG outperforms state-the-art approaches, offering both superior accuracy and scalability to long sequences while running at least 60x faster than existing training-free methods and achieving inference speeds on the same order as heavy pretrained models.
Capture Stage Environments: A Guide to Better Matting
Jul 10, 2025



Capture stages are high-end sources of state-of-the-art recordings for downstream applications in movies, games, and other media. One crucial step in almost all pipelines is the matting of images to isolate the captured performances from the background. While common matting algorithms deliver remarkable performance in other applications like teleconferencing and mobile entertainment, we found that they struggle significantly with the peculiarities of capture stage content. The goal of our work is to share insights into those challenges as a curated list of those characteristics along with a constructive discussion for proactive intervention and present a guideline to practitioners for an improved workflow to mitigate unresolved challenges. To this end, we also demonstrate an efficient pipeline to adapt state-of-the-art approaches to such custom setups without the need of extensive annotations, both offline and real-time. For an objective evaluation, we propose a validation methodology based on a leading diffusion model that highlights the benefits of our approach.
VHS: High-Resolution Iterative Stereo Matching with Visual Hull Priors
Jun 04, 2024We present a stereo-matching method for depth estimation from high-resolution images using visual hulls as priors, and a memory-efficient technique for the correlation computation. Our method uses object masks extracted from supplementary views of the scene to guide the disparity estimation, effectively reducing the search space for matches. This approach is specifically tailored to stereo rigs in volumetric capture systems, where an accurate depth plays a key role in the downstream reconstruction task. To enable training and regression at high resolutions targeted by recent systems, our approach extends a sparse correlation computation into a hybrid sparse-dense scheme suitable for application in leading recurrent network architectures. We evaluate the performance-efficiency trade-off of our method compared to state-of-the-art methods, and demonstrate the efficacy of the visual hull guidance. In addition, we propose a training scheme for a further reduction of memory requirements during optimization, facilitating training on high-resolution data.
Kissing to Find a Match: Efficient Low-Rank Permutation Representation
Aug 25, 2023Permutation matrices play a key role in matching and assignment problems across the fields, especially in computer vision and robotics. However, memory for explicitly representing permutation matrices grows quadratically with the size of the problem, prohibiting large problem instances. In this work, we propose to tackle the curse of dimensionality of large permutation matrices by approximating them using low-rank matrix factorization, followed by a nonlinearity. To this end, we rely on the Kissing number theory to infer the minimal rank required for representing a permutation matrix of a given size, which is significantly smaller than the problem size. This leads to a drastic reduction in computation and memory costs, e.g., up to $3$ orders of magnitude less memory for a problem of size $n=20000$, represented using $8.4\times10^5$ elements in two small matrices instead of using a single huge matrix with $4\times 10^8$ elements. The proposed representation allows for accurate representations of large permutation matrices, which in turn enables handling large problems that would have been infeasible otherwise. We demonstrate the applicability and merits of the proposed approach through a series of experiments on a range of problems that involve predicting permutation matrices, from linear and quadratic assignment to shape matching problems.
Inverting Gradients -- How easy is it to break privacy in federated learning?
Mar 31, 2020


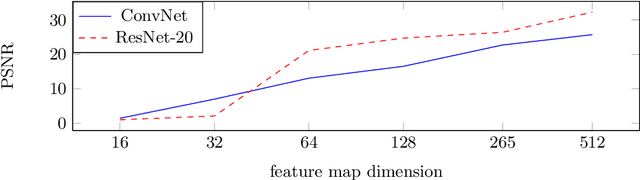
The idea of federated learning is to collaboratively train a neural network on a server. Each user receives the current weights of the network and in turns sends parameter updates (gradients) based on local data. This protocol has been designed not only to train neural networks data-efficiently, but also to provide privacy benefits for users, as their input data remains on device and only parameter gradients are shared. In this paper we show that sharing parameter gradients is by no means secure: By exploiting a cosine similarity loss along with optimization methods from adversarial attacks, we are able to faithfully reconstruct images at high resolution from the knowledge of their parameter gradients, and demonstrate that such a break of privacy is possible even for trained deep networks. Moreover, we analyze the effects of architecture as well as parameters on the difficulty of reconstructing the input image, prove that any input to a fully connected layer can be reconstructed analytically independent of the remaining architecture, and show numerically that even averaging gradients over several iterations or several images does not protect the user's privacy in federated learning applications in computer vision.