 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoment-Based 3D Gaussian Splatting: Resolving Volumetric Occlusion with Order-Independent Transmittance
Dec 12, 2025
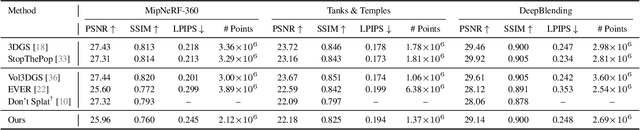

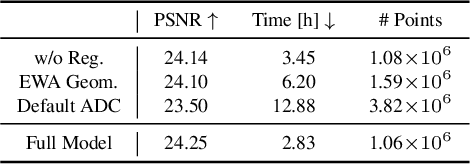
The recent success of 3D Gaussian Splatting (3DGS) has reshaped novel view synthesis by enabling fast optimization and real-time rendering of high-quality radiance fields. However, it relies on simplified, order-dependent alpha blending and coarse approximations of the density integral within the rasterizer, thereby limiting its ability to render complex, overlapping semi-transparent objects. In this paper, we extend rasterization-based rendering of 3D Gaussian representations with a novel method for high-fidelity transmittance computation, entirely avoiding the need for ray tracing or per-pixel sample sorting. Building on prior work in moment-based order-independent transparency, our key idea is to characterize the density distribution along each camera ray with a compact and continuous representation based on statistical moments. To this end, we analytically derive and compute a set of per-pixel moments from all contributing 3D Gaussians. From these moments, a continuous transmittance function is reconstructed for each ray, which is then independently sampled within each Gaussian. As a result, our method bridges the gap between rasterization and physical accuracy by modeling light attenuation in complex translucent media, significantly improving overall reconstruction and rendering quality.
NeRFs are Mirror Detectors: Using Structural Similarity for Multi-View Mirror Scene Reconstruction with 3D Surface Primitives
Jan 07, 2025



While neural radiance fields (NeRF) led to a breakthrough in photorealistic novel view synthesis, handling mirroring surfaces still denotes a particular challenge as they introduce severe inconsistencies in the scene representation. Previous attempts either focus on reconstructing single reflective objects or rely on strong supervision guidance in terms of additional user-provided annotations of visible image regions of the mirrors, thereby limiting the practical usability. In contrast, in this paper, we present NeRF-MD, a method which shows that NeRFs can be considered as mirror detectors and which is capable of reconstructing neural radiance fields of scenes containing mirroring surfaces without the need for prior annotations. To this end, we first compute an initial estimate of the scene geometry by training a standard NeRF using a depth reprojection loss. Our key insight lies in the fact that parts of the scene corresponding to a mirroring surface will still exhibit a significant photometric inconsistency, whereas the remaining parts are already reconstructed in a plausible manner. This allows us to detect mirror surfaces by fitting geometric primitives to such inconsistent regions in this initial stage of the training. Using this information, we then jointly optimize the radiance field and mirror geometry in a second training stage to refine their quality. We demonstrate the capability of our method to allow the faithful detection of mirrors in the scene as well as the reconstruction of a single consistent scene representation, and demonstrate its potential in comparison to baseline and mirror-aware approaches.
VHS: High-Resolution Iterative Stereo Matching with Visual Hull Priors
Jun 04, 2024We present a stereo-matching method for depth estimation from high-resolution images using visual hulls as priors, and a memory-efficient technique for the correlation computation. Our method uses object masks extracted from supplementary views of the scene to guide the disparity estimation, effectively reducing the search space for matches. This approach is specifically tailored to stereo rigs in volumetric capture systems, where an accurate depth plays a key role in the downstream reconstruction task. To enable training and regression at high resolutions targeted by recent systems, our approach extends a sparse correlation computation into a hybrid sparse-dense scheme suitable for application in leading recurrent network architectures. We evaluate the performance-efficiency trade-off of our method compared to state-of-the-art methods, and demonstrate the efficacy of the visual hull guidance. In addition, we propose a training scheme for a further reduction of memory requirements during optimization, facilitating training on high-resolution data.
RHINO-VR Experience: Teaching Mobile Robotics Concepts in an Interactive Museum Exhibit
Mar 22, 2024



In 1997, the very first tour guide robot RHINO was deployed in a museum in Germany. With the ability to navigate autonomously through the environment, the robot gave tours to over 2,000 visitors. Today, RHINO itself has become an exhibit and is no longer operational. In this paper, we present RHINO-VR, an interactive museum exhibit using virtual reality (VR) that allows museum visitors to experience the historical robot RHINO in operation in a virtual museum. RHINO-VR, unlike static exhibits, enables users to familiarize themselves with basic mobile robotics concepts without the fear of damaging the exhibit. In the virtual environment, the user is able to interact with RHINO in VR by pointing to a location to which the robot should navigate and observing the corresponding actions of the robot. To include other visitors who cannot use the VR, we provide an external observation view to make RHINO visible to them. We evaluated our system by measuring the frame rate of the VR simulation, comparing the generated virtual 3D models with the originals, and conducting a user study. The user-study showed that RHINO-VR improved the visitors' understanding of the robot's functionality and that they would recommend experiencing the VR exhibit to others.
TraM-NeRF: Tracing Mirror and Near-Perfect Specular Reflections through Neural Radiance Fields
Oct 16, 2023Implicit representations like Neural Radiance Fields (NeRF) showed impressive results for photorealistic rendering of complex scenes with fine details. However, ideal or near-perfectly specular reflecting objects such as mirrors, which are often encountered in various indoor scenes, impose ambiguities and inconsistencies in the representation of the reconstructed scene leading to severe artifacts in the synthesized renderings. In this paper, we present a novel reflection tracing method tailored for the involved volume rendering within NeRF that takes these mirror-like objects into account while avoiding the cost of straightforward but expensive extensions through standard path tracing. By explicitly modeling the reflection behavior using physically plausible materials and estimating the reflected radiance with Monte-Carlo methods within the volume rendering formulation, we derive efficient strategies for importance sampling and the transmittance computation along rays from only few samples. We show that our novel method enables the training of consistent representations of such challenging scenes and achieves superior results in comparison to previous state-of-the-art approaches.
Efficient 3D Reconstruction, Streaming and Visualization of Static and Dynamic Scene Parts for Multi-client Live-telepresence in Large-scale Environments
Nov 25, 2022
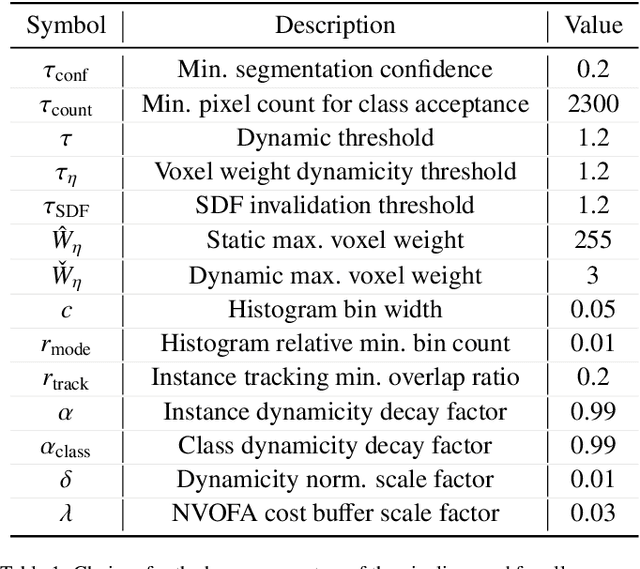

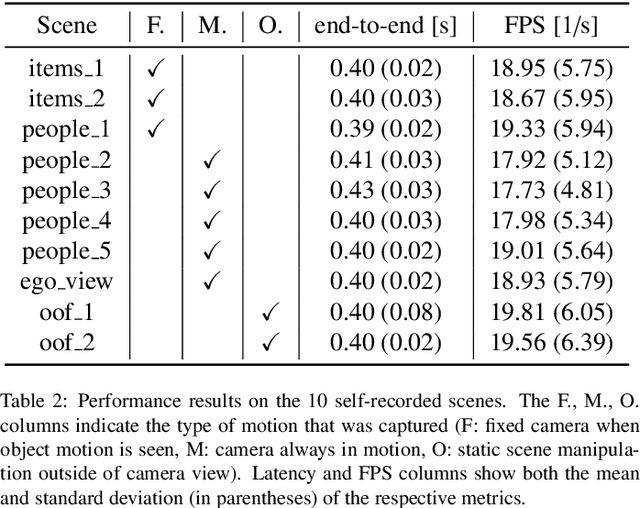
Despite the impressive progress of telepresence systems for room-scale scenes with static and dynamic scene entities, expanding their capabilities to scenarios with larger dynamic environments beyond a fixed size of a few squaremeters remains challenging. In this paper, we aim at sharing 3D live-telepresence experiences in large-scale environments beyond room scale with both static and dynamic scene entities at practical bandwidth requirements only based on light-weight scene capture with a single moving consumer-grade RGB-D camera. To this end, we present a system which is built upon a novel hybrid volumetric scene representation in terms of the combination of a voxel-based scene representation for the static contents, that not only stores the reconstructed surface geometry but also contains information about the object semantics as well as their accumulated dynamic movement over time, and a point-cloud-based representation for dynamic scene parts, where the respective separation from static parts is achieved based on semantic and instance information extracted for the input frames. With an independent yet simultaneous streaming of both static and dynamic content, where we seamlessly integrate potentially moving but currently static scene entities in the static model until they are becoming dynamic again, as well as the fusion of static and dynamic data at the remote client, our system is able to achieve VR-based live-telepresence at interactive rates. Our evaluation demonstrates the potential of our novel approach in terms of visual quality, performance, and ablation studies regarding involved design choices.