 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Visual Place Recognition Methods for Image Pair Retrieval in 3D Vision and Robotics
Mar 14, 2026Visual Place Recognition (VPR) is a core component in computer vision, typically formulated as an image retrieval task for localization, mapping, and navigation. In this work, we instead study VPR as an image pair retrieval front-end for registration pipelines, where the goal is to find top-matching image pairs between two disjoint image sets for downstream tasks such as scene registration, SLAM, and Structure-from-Motion. We comparatively evaluate state-of-the-art VPR families - NetVLAD-style baselines, classification-based global descriptors (CosPlace, EigenPlaces), feature-mixing (MixVPR), and foundation-model-driven methods (AnyLoc, SALAD, MegaLoc) - on three challenging datasets: object-centric outdoor scenes (Tanks and Temples), indoor RGB-D scans (ScanNet-GS), and autonomous-driving sequences (KITTI). We show that modern global descriptor approaches are increasingly suitable as off-the-shelf image pair retrieval modules in challenging scenarios including perceptual aliasing and incomplete sequences, while exhibiting clear, domain-dependent strengths and weaknesses that are critical when choosing VPR components for robust mapping and registration.
6D Strawberry Pose Estimation: Real-time and Edge AI Solutions Using Purely Synthetic Training Data
Nov 14, 2025Automated and selective harvesting of fruits has become an important area of research, particularly due to challenges such as high costs and a shortage of seasonal labor in advanced economies. This paper focuses on 6D pose estimation of strawberries using purely synthetic data generated through a procedural pipeline for photorealistic rendering. We employ the YOLOX-6D-Pose algorithm, a single-shot approach that leverages the YOLOX backbone, known for its balance between speed and accuracy, and its support for edge inference. To address the lacking availability of training data, we introduce a robust and flexible pipeline for generating synthetic strawberry data from various 3D models via a procedural Blender pipeline, where we focus on enhancing the realism of the synthesized data in comparison to previous work to make it a valuable resource for training pose estimation algorithms. Quantitative evaluations indicate that our models achieve comparable accuracy on both the NVIDIA RTX 3090 and Jetson Orin Nano across several ADD-S metrics, with the RTX 3090 demonstrating superior processing speed. However, the Jetson Orin Nano is particularly suited for resource-constrained environments, making it an excellent choice for deployment in agricultural robotics. Qualitative assessments further confirm the model's performance, demonstrating its capability to accurately infer the poses of ripe and partially ripe strawberries, while facing challenges in detecting unripe specimens. This suggests opportunities for future improvements, especially in enhancing detection capabilities for unripe strawberries (if desired) by exploring variations in color. Furthermore, the methodology presented could be adapted easily for other fruits such as apples, peaches, and plums, thereby expanding its applicability and impact in the field of agricultural automation.
Neural Restoration of Greening Defects in Historical Autochrome Photographs Based on Purely Synthetic Data
May 28, 2025The preservation of early visual arts, particularly color photographs, is challenged by deterioration caused by aging and improper storage, leading to issues like blurring, scratches, color bleeding, and fading defects. In this paper, we present the first approach for the automatic removal of greening color defects in digitized autochrome photographs. Our main contributions include a method based on synthetic dataset generation and the use of generative AI with a carefully designed loss function for the restoration of visual arts. To address the lack of suitable training datasets for analyzing greening defects in damaged autochromes, we introduce a novel approach for accurately simulating such defects in synthetic data. We also propose a modified weighted loss function for the ChaIR method to account for color imbalances between defected and non-defected areas. While existing methods struggle with accurately reproducing original colors and may require significant manual effort, our method allows for efficient restoration with reduced time requirements.
NeRFs are Mirror Detectors: Using Structural Similarity for Multi-View Mirror Scene Reconstruction with 3D Surface Primitives
Jan 07, 2025



While neural radiance fields (NeRF) led to a breakthrough in photorealistic novel view synthesis, handling mirroring surfaces still denotes a particular challenge as they introduce severe inconsistencies in the scene representation. Previous attempts either focus on reconstructing single reflective objects or rely on strong supervision guidance in terms of additional user-provided annotations of visible image regions of the mirrors, thereby limiting the practical usability. In contrast, in this paper, we present NeRF-MD, a method which shows that NeRFs can be considered as mirror detectors and which is capable of reconstructing neural radiance fields of scenes containing mirroring surfaces without the need for prior annotations. To this end, we first compute an initial estimate of the scene geometry by training a standard NeRF using a depth reprojection loss. Our key insight lies in the fact that parts of the scene corresponding to a mirroring surface will still exhibit a significant photometric inconsistency, whereas the remaining parts are already reconstructed in a plausible manner. This allows us to detect mirror surfaces by fitting geometric primitives to such inconsistent regions in this initial stage of the training. Using this information, we then jointly optimize the radiance field and mirror geometry in a second training stage to refine their quality. We demonstrate the capability of our method to allow the faithful detection of mirrors in the scene as well as the reconstruction of a single consistent scene representation, and demonstrate its potential in comparison to baseline and mirror-aware approaches.
SpectralGaussians: Semantic, spectral 3D Gaussian splatting for multi-spectral scene representation, visualization and analysis
Aug 13, 2024We propose a novel cross-spectral rendering framework based on 3D Gaussian Splatting (3DGS) that generates realistic and semantically meaningful splats from registered multi-view spectrum and segmentation maps. This extension enhances the representation of scenes with multiple spectra, providing insights into the underlying materials and segmentation. We introduce an improved physically-based rendering approach for Gaussian splats, estimating reflectance and lights per spectra, thereby enhancing accuracy and realism. In a comprehensive quantitative and qualitative evaluation, we demonstrate the superior performance of our approach with respect to other recent learning-based spectral scene representation approaches (i.e., XNeRF and SpectralNeRF) as well as other non-spectral state-of-the-art learning-based approaches. Our work also demonstrates the potential of spectral scene understanding for precise scene editing techniques like style transfer, inpainting, and removal. Thereby, our contributions address challenges in multi-spectral scene representation, rendering, and editing, offering new possibilities for diverse applications.
RANRAC: Robust Neural Scene Representations via Random Ray Consensus
Dec 15, 2023We introduce RANRAC, a robust reconstruction algorithm for 3D objects handling occluded and distracted images, which is a particularly challenging scenario that prior robust reconstruction methods cannot deal with. Our solution supports single-shot reconstruction by involving light-field networks, and is also applicable to photo-realistic, robust, multi-view reconstruction from real-world images based on neural radiance fields. While the algorithm imposes certain limitations on the scene representation and, thereby, the supported scene types, it reliably detects and excludes inconsistent perspectives, resulting in clean images without floating artifacts. Our solution is based on a fuzzy adaption of the random sample consensus paradigm, enabling its application to large scale models. We interpret the minimal number of samples to determine the model parameters as a tunable hyperparameter. This is applicable, as a cleaner set of samples improves reconstruction quality. Further, this procedure also handles outliers. Especially for conditioned models, it can result in the same local minimum in the latent space as would be obtained with a completely clean set. We report significant improvements for novel-view synthesis in occluded scenarios, of up to 8dB PSNR compared to the baseline.
Neural inverse procedural modeling of knitting yarns from images
Mar 01, 2023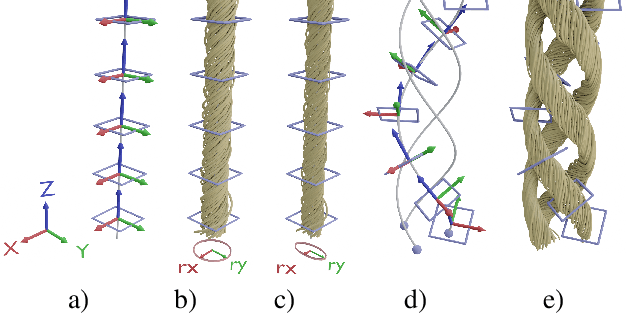
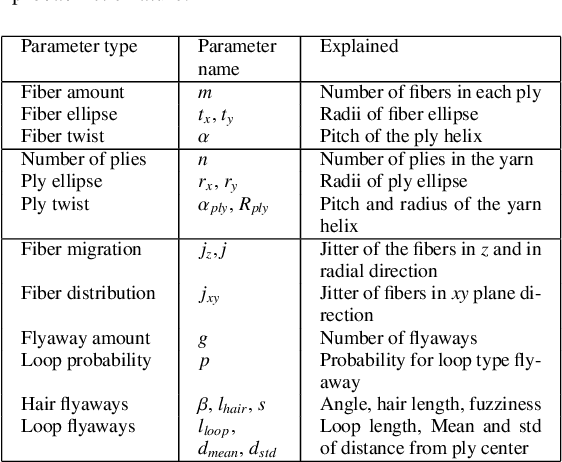

We investigate the capabilities of neural inverse procedural modeling to infer high-quality procedural yarn models with fiber-level details from single images of depicted yarn samples. While directly inferring all parameters of the underlying yarn model based on a single neural network may seem an intuitive choice, we show that the complexity of yarn structures in terms of twisting and migration characteristics of the involved fibers can be better encountered in terms of ensembles of networks that focus on individual characteristics. We analyze the effect of different loss functions including a parameter loss to penalize the deviation of inferred parameters to ground truth annotations, a reconstruction loss to enforce similar statistics of the image generated for the estimated parameters in comparison to training images as well as an additional regularization term to explicitly penalize deviations between latent codes of synthetic images and the average latent code of real images in the latent space of the encoder. We demonstrate that the combination of a carefully designed parametric, procedural yarn model with respective network ensembles as well as loss functions even allows robust parameter inference when solely trained on synthetic data. Since our approach relies on the availability of a yarn database with parameter annotations and we are not aware of such a respectively available dataset, we additionally provide, to the best of our knowledge, the first dataset of yarn images with annotations regarding the respective yarn parameters. For this purpose, we use a novel yarn generator that improves the realism of the produced results over previous approaches.
Efficient 3D Reconstruction, Streaming and Visualization of Static and Dynamic Scene Parts for Multi-client Live-telepresence in Large-scale Environments
Nov 25, 2022

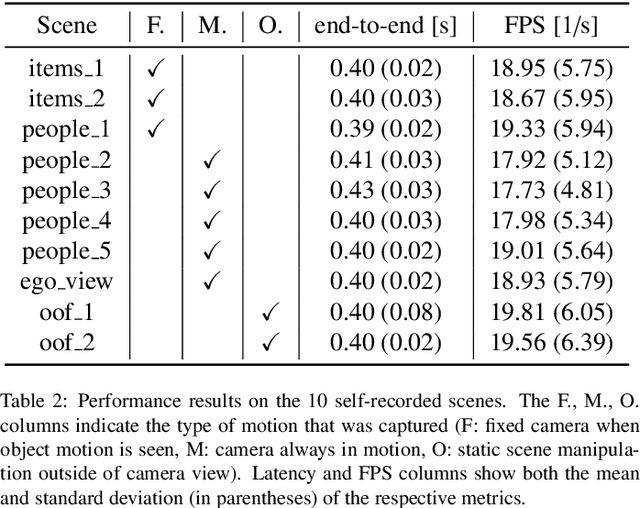
Despite the impressive progress of telepresence systems for room-scale scenes with static and dynamic scene entities, expanding their capabilities to scenarios with larger dynamic environments beyond a fixed size of a few squaremeters remains challenging. In this paper, we aim at sharing 3D live-telepresence experiences in large-scale environments beyond room scale with both static and dynamic scene entities at practical bandwidth requirements only based on light-weight scene capture with a single moving consumer-grade RGB-D camera. To this end, we present a system which is built upon a novel hybrid volumetric scene representation in terms of the combination of a voxel-based scene representation for the static contents, that not only stores the reconstructed surface geometry but also contains information about the object semantics as well as their accumulated dynamic movement over time, and a point-cloud-based representation for dynamic scene parts, where the respective separation from static parts is achieved based on semantic and instance information extracted for the input frames. With an independent yet simultaneous streaming of both static and dynamic content, where we seamlessly integrate potentially moving but currently static scene entities in the static model until they are becoming dynamic again, as well as the fusion of static and dynamic data at the remote client, our system is able to achieve VR-based live-telepresence at interactive rates. Our evaluation demonstrates the potential of our novel approach in terms of visual quality, performance, and ablation studies regarding involved design choices.
BoundED: Neural Boundary and Edge Detection in 3D Point Clouds via Local Neighborhood Statistics
Oct 24, 2022



Extracting high-level structural information from 3D point clouds is challenging but essential for tasks like urban planning or autonomous driving requiring an advanced understanding of the scene at hand. Existing approaches are still not able to produce high-quality results consistently while being fast enough to be deployed in scenarios requiring interactivity. We propose to utilize a novel set of features describing the local neighborhood on a per-point basis via first and second order statistics as input for a simple and compact classification network to distinguish between non-edge, sharp-edge, and boundary points in the given data. Leveraging this feature embedding enables our algorithm to outperform the state-of-the-art techniques in terms of quality and processing time.
Incomplete Gamma Kernels: Generalizing Locally Optimal Projection Operators
May 02, 2022



We present incomplete gamma kernels, a generalization of Locally Optimal Projection (LOP) operators. In particular, we reveal the relation of the classical localized $ L_1 $ estimator, used in the LOP operator for surface reconstruction from noisy point clouds, to the common Mean Shift framework via a novel kernel. Furthermore, we generalize this result to a whole family of kernels that are built upon the incomplete gamma function and each represents a localized $ L_p $ estimator. By deriving various properties of the kernel family concerning distributional, Mean Shift induced, and other aspects such as strict positive definiteness, we obtain a deeper understanding of the operator's projection behavior. From these theoretical insights, we illustrate several applications ranging from an improved Weighted LOP (WLOP) density weighting scheme and a more accurate Continuous LOP (CLOP) kernel approximation to the definition of a novel set of robust loss functions. These incomplete gamma losses include the Gaussian and LOP loss as special cases and can be applied for reconstruction tasks such as normal filtering. We demonstrate the effects of each application in a range of quantitative and qualitative experiments that highlight the benefits induced by our modifications.