 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold-Preserving Superpixel Hierarchies and Embeddings for the Exploration of High-Dimensional Images
Feb 27, 2026High-dimensional images, or images with a high-dimensional attribute vector per pixel, are commonly explored with coordinated views of a low-dimensional embedding of the attribute space and a conventional image representation. Nowadays, such images can easily contain several million pixels. For such large datasets, hierarchical embedding techniques are better suited to represent the high-dimensional attribute space than flat dimensionality reduction methods. However, available hierarchical dimensionality reduction methods construct the hierarchy purely based on the attribute information and ignore the spatial layout of pixels in the images. This impedes the exploration of regions of interest in the image space, since there is no congruence between a region of interest in image space and the associated attribute abstractions in the hierarchy. In this paper, we present a superpixel hierarchy for high-dimensional images that takes the high-dimensional attribute manifold into account during construction. Through this, our method enables consistent exploration of high-dimensional images in both image and attribute space. We show the effectiveness of this new image-guided hierarchy in the context of embedding exploration by comparing it with classical hierarchical embedding-based image exploration in two use cases.
Fast and Uncertainty-Aware SVBRDF Recovery from Multi-View Capture using Frequency Domain Analysis
Jun 25, 2024



Relightable object acquisition is a key challenge in simplifying digital asset creation. Complete reconstruction of an object typically requires capturing hundreds to thousands of photographs under controlled illumination, with specialized equipment. The recent progress in differentiable rendering improved the quality and accessibility of inverse rendering optimization. Nevertheless, under uncontrolled illumination and unstructured viewpoints, there is no guarantee that the observations contain enough information to reconstruct the appearance properties of the captured object. We thus propose to consider the acquisition process from a signal-processing perspective. Given an object's geometry and a lighting environment, we estimate the properties of the materials on the object's surface in seconds. We do so by leveraging frequency domain analysis, considering the recovery of material properties as a deconvolution, enabling fast error estimation. We then quantify the uncertainty of the estimation, based on the available data, highlighting the areas for which priors or additional samples would be required for improved acquisition quality. We compare our approach to previous work and quantitatively evaluate our results, showing similar quality as previous work in a fraction of the time, and providing key information about the certainty of the results.
MotionDreamer: Zero-Shot 3D Mesh Animation from Video Diffusion Models
May 30, 2024



Animation techniques bring digital 3D worlds and characters to life. However, manual animation is tedious and automated techniques are often specialized to narrow shape classes. In our work, we propose a technique for automatic re-animation of arbitrary 3D shapes based on a motion prior extracted from a video diffusion model. Unlike existing 4D generation methods, we focus solely on the motion, and we leverage an explicit mesh-based representation compatible with existing computer-graphics pipelines. Furthermore, our utilization of diffusion features enhances accuracy of our motion fitting. We analyze efficacy of these features for animation fitting and we experimentally validate our approach for two different diffusion models and four animation models. Finally, we demonstrate that our time-efficient zero-shot method achieves a superior performance re-animating a diverse set of 3D shapes when compared to existing techniques in a user study. The project website is located at https://lukas.uzolas.com/MotionDreamer.
Accelerating hyperbolic t-SNE
Jan 23, 2024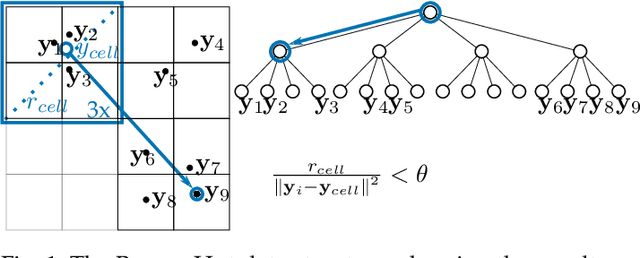

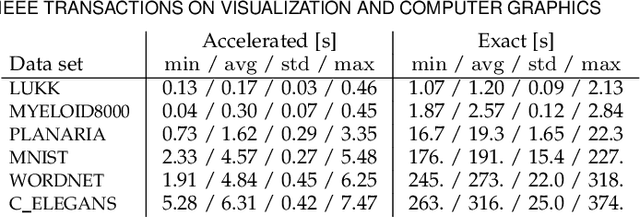
The need to understand the structure of hierarchical or high-dimensional data is present in a variety of fields. Hyperbolic spaces have proven to be an important tool for embedding computations and analysis tasks as their non-linear nature lends itself well to tree or graph data. Subsequently, they have also been used in the visualization of high-dimensional data, where they exhibit increased embedding performance. However, none of the existing dimensionality reduction methods for embedding into hyperbolic spaces scale well with the size of the input data. That is because the embeddings are computed via iterative optimization schemes and the computation cost of every iteration is quadratic in the size of the input. Furthermore, due to the non-linear nature of hyperbolic spaces, Euclidean acceleration structures cannot directly be translated to the hyperbolic setting. This paper introduces the first acceleration structure for hyperbolic embeddings, building upon a polar quadtree. We compare our approach with existing methods and demonstrate that it computes embeddings of similar quality in significantly less time. Implementation and scripts for the experiments can be found at https://graphics.tudelft.nl/accelerating-hyperbolic-tsne.
RANRAC: Robust Neural Scene Representations via Random Ray Consensus
Dec 15, 2023We introduce RANRAC, a robust reconstruction algorithm for 3D objects handling occluded and distracted images, which is a particularly challenging scenario that prior robust reconstruction methods cannot deal with. Our solution supports single-shot reconstruction by involving light-field networks, and is also applicable to photo-realistic, robust, multi-view reconstruction from real-world images based on neural radiance fields. While the algorithm imposes certain limitations on the scene representation and, thereby, the supported scene types, it reliably detects and excludes inconsistent perspectives, resulting in clean images without floating artifacts. Our solution is based on a fuzzy adaption of the random sample consensus paradigm, enabling its application to large scale models. We interpret the minimal number of samples to determine the model parameters as a tunable hyperparameter. This is applicable, as a cleaner set of samples improves reconstruction quality. Further, this procedure also handles outliers. Especially for conditioned models, it can result in the same local minimum in the latent space as would be obtained with a completely clean set. We report significant improvements for novel-view synthesis in occluded scenarios, of up to 8dB PSNR compared to the baseline.
Tuning the perplexity for and computing sampling-based t-SNE embeddings
Aug 29, 2023



Widely used pipelines for the analysis of high-dimensional data utilize two-dimensional visualizations. These are created, e.g., via t-distributed stochastic neighbor embedding (t-SNE). When it comes to large data sets, applying these visualization techniques creates suboptimal embeddings, as the hyperparameters are not suitable for large data. Cranking up these parameters usually does not work as the computations become too expensive for practical workflows. In this paper, we argue that a sampling-based embedding approach can circumvent these problems. We show that hyperparameters must be chosen carefully, depending on the sampling rate and the intended final embedding. Further, we show how this approach speeds up the computation and increases the quality of the embeddings.
Template-free Articulated Neural Point Clouds for Reposable View Synthesis
May 30, 2023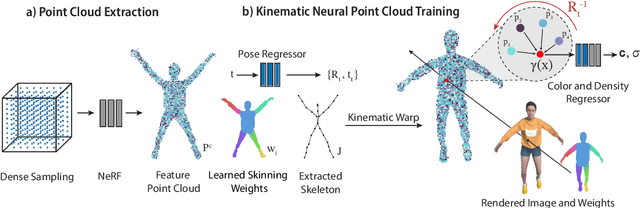


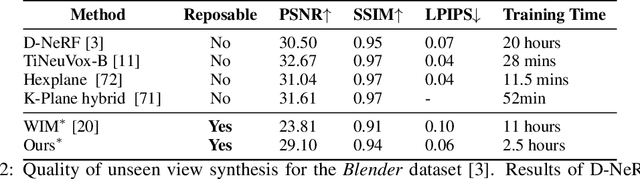
Dynamic Neural Radiance Fields (NeRFs) achieve remarkable visual quality when synthesizing novel views of time-evolving 3D scenes. However, the common reliance on backward deformation fields makes reanimation of the captured object poses challenging. Moreover, the state of the art dynamic models are often limited by low visual fidelity, long reconstruction time or specificity to narrow application domains. In this paper, we present a novel method utilizing a point-based representation and Linear Blend Skinning (LBS) to jointly learn a Dynamic NeRF and an associated skeletal model from even sparse multi-view video. Our forward-warping approach achieves state-of-the-art visual fidelity when synthesizing novel views and poses while significantly reducing the necessary learning time when compared to existing work. We demonstrate the versatility of our representation on a variety of articulated objects from common datasets and obtain reposable 3D reconstructions without the need of object-specific skeletal templates. Code will be made available at https://github.com/lukasuz/Articulated-Point-NeRF.
Deep vanishing point detection: Geometric priors make dataset variations vanish
Mar 16, 2022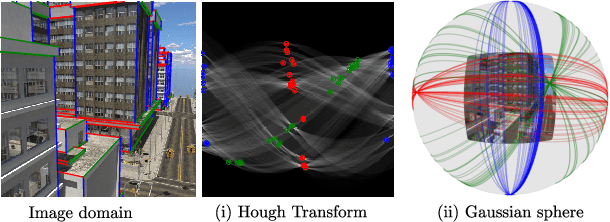
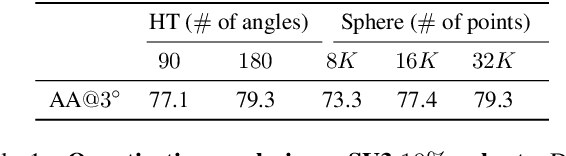
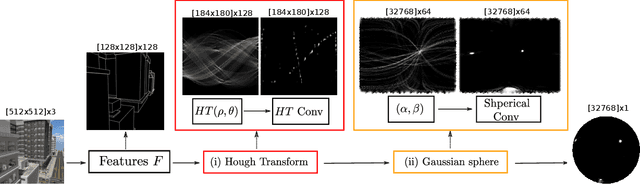
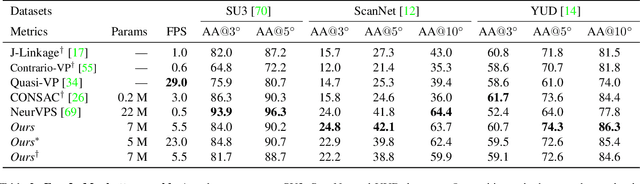
Deep learning has improved vanishing point detection in images. Yet, deep networks require expensive annotated datasets trained on costly hardware and do not generalize to even slightly different domains, and minor problem variants. Here, we address these issues by injecting deep vanishing point detection networks with prior knowledge. This prior knowledge no longer needs to be learned from data, saving valuable annotation efforts and compute, unlocking realistic few-sample scenarios, and reducing the impact of domain changes. Moreover, the interpretability of the priors allows to adapt deep networks to minor problem variations such as switching between Manhattan and non-Manhattan worlds. We seamlessly incorporate two geometric priors: (i) Hough Transform -- mapping image pixels to straight lines, and (ii) Gaussian sphere -- mapping lines to great circles whose intersections denote vanishing points. Experimentally, we ablate our choices and show comparable accuracy to existing models in the large-data setting. We validate our model's improved data efficiency, robustness to domain changes, adaptability to non-Manhattan settings.
Incorporating Texture Information into Dimensionality Reduction for High-Dimensional Images
Mar 02, 2022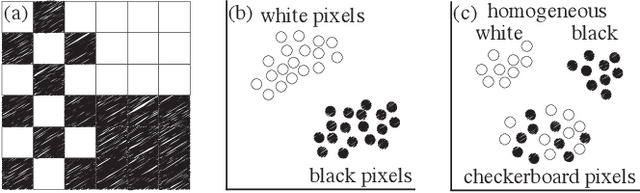
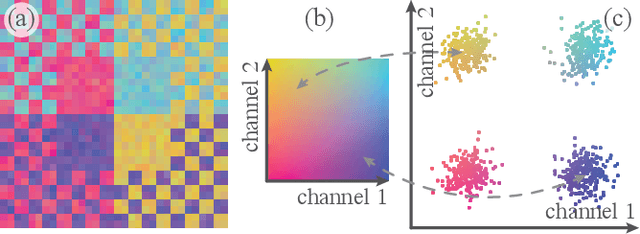
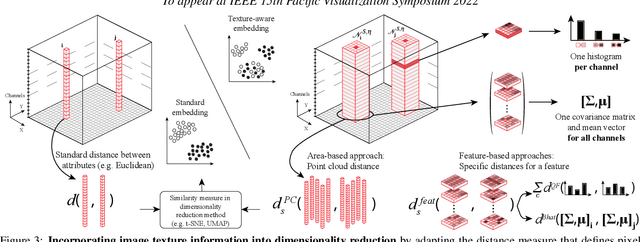
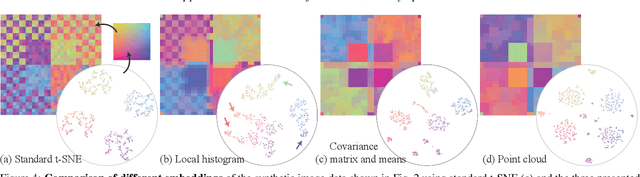
High-dimensional imaging is becoming increasingly relevant in many fields from astronomy and cultural heritage to systems biology. Visual exploration of such high-dimensional data is commonly facilitated by dimensionality reduction. However, common dimensionality reduction methods do not include spatial information present in images, such as local texture features, into the construction of low-dimensional embeddings. Consequently, exploration of such data is typically split into a step focusing on the attribute space followed by a step focusing on spatial information, or vice versa. In this paper, we present a method for incorporating spatial neighborhood information into distance-based dimensionality reduction methods, such as t-Distributed Stochastic Neighbor Embedding (t-SNE). We achieve this by modifying the distance measure between high-dimensional attribute vectors associated with each pixel such that it takes the pixel's spatial neighborhood into account. Based on a classification of different methods for comparing image patches, we explore a number of different approaches. We compare these approaches from a theoretical and experimental point of view. Finally, we illustrate the value of the proposed methods by qualitative and quantitative evaluation on synthetic data and two real-world use cases.
DeltaConv: Anisotropic Point Cloud Learning with Exterior Calculus
Nov 23, 2021
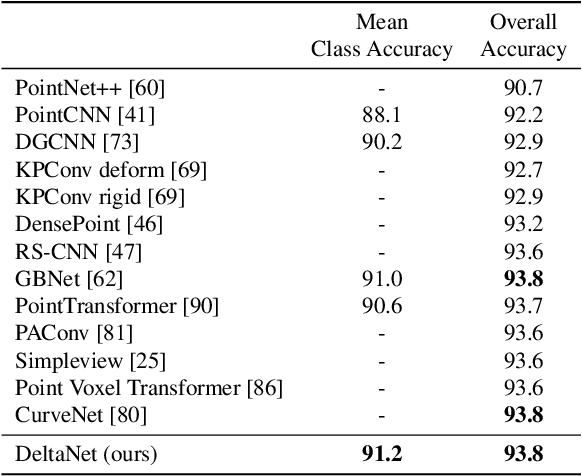

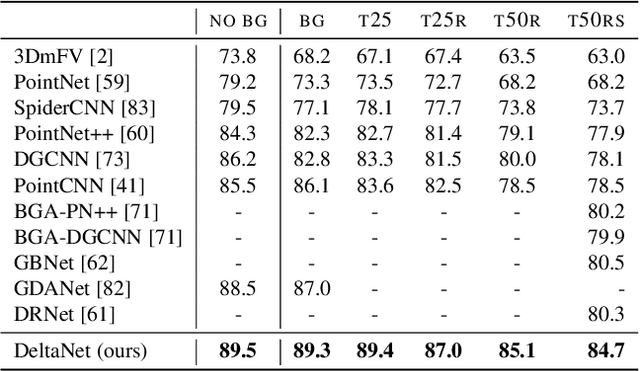
Learning from 3D point-cloud data has rapidly gained momentum, motivated by the success of deep learning on images and the increased availability of 3D data. In this paper, we aim to construct anisotropic convolutions that work directly on the surface derived from a point cloud. This is challenging because of the lack of a global coordinate system for tangential directions on surfaces. We introduce a new convolution operator called DeltaConv, which combines geometric operators from exterior calculus to enable the construction of anisotropic filters on point clouds. Because these operators are defined on scalar- and vector-fields, we separate the network into a scalar- and a vector-stream, which are connected by the operators. The vector stream enables the network to explicitly represent, evaluate, and process directional information. Our convolutions are robust and simple to implement and show improved accuracy compared to state-of-the-art approaches on several benchmarks, while also speeding up training and inference.