 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vehicle System for Navigating Among Vulnerable Road Users Including Remote Operation
May 08, 2025



We present a vehicle system capable of navigating safely and efficiently around Vulnerable Road Users (VRUs), such as pedestrians and cyclists. The system comprises key modules for environment perception, localization and mapping, motion planning, and control, integrated into a prototype vehicle. A key innovation is a motion planner based on Topology-driven Model Predictive Control (T-MPC). The guidance layer generates multiple trajectories in parallel, each representing a distinct strategy for obstacle avoidance or non-passing. The underlying trajectory optimization constrains the joint probability of collision with VRUs under generic uncertainties. To address extraordinary situations ("edge cases") that go beyond the autonomous capabilities - such as construction zones or encounters with emergency responders - the system includes an option for remote human operation, supported by visual and haptic guidance. In simulation, our motion planner outperforms three baseline approaches in terms of safety and efficiency. We also demonstrate the full system in prototype vehicle tests on a closed track, both in autonomous and remotely operated modes.
VoteFlow: Enforcing Local Rigidity in Self-Supervised Scene Flow
Mar 28, 2025Scene flow estimation aims to recover per-point motion from two adjacent LiDAR scans. However, in real-world applications such as autonomous driving, points rarely move independently of others, especially for nearby points belonging to the same object, which often share the same motion. Incorporating this locally rigid motion constraint has been a key challenge in self-supervised scene flow estimation, which is often addressed by post-processing or appending extra regularization. While these approaches are able to improve the rigidity of predicted flows, they lack an architectural inductive bias for local rigidity within the model structure, leading to suboptimal learning efficiency and inferior performance. In contrast, we enforce local rigidity with a lightweight add-on module in neural network design, enabling end-to-end learning. We design a discretized voting space that accommodates all possible translations and then identify the one shared by nearby points by differentiable voting. Additionally, to ensure computational efficiency, we operate on pillars rather than points and learn representative features for voting per pillar. We plug the Voting Module into popular model designs and evaluate its benefit on Argoverse 2 and Waymo datasets. We outperform baseline works with only marginal compute overhead. Code is available at https://github.com/tudelft-iv/VoteFlow.
ICP-Flow: LiDAR Scene Flow Estimation with ICP
Feb 27, 2024Scene flow characterizes the 3D motion between two LiDAR scans captured by an autonomous vehicle at nearby timesteps. Prevalent methods consider scene flow as point-wise unconstrained flow vectors that can be learned by either large-scale training beforehand or time-consuming optimization at inference. However, these methods do not take into account that objects in autonomous driving often move rigidly. We incorporate this rigid-motion assumption into our design, where the goal is to associate objects over scans and then estimate the locally rigid transformations. We propose ICP-Flow, a learning-free flow estimator. The core of our design is the conventional Iterative Closest Point (ICP) algorithm, which aligns the objects over time and outputs the corresponding rigid transformations. Crucially, to aid ICP, we propose a histogram-based initialization that discovers the most likely translation, thus providing a good starting point for ICP. The complete scene flow is then recovered from the rigid transformations. We outperform state-of-the-art baselines, including supervised models, on the Waymo dataset and perform competitively on Argoverse-v2 and nuScenes. Further, we train a feedforward neural network, supervised by the pseudo labels from our model, and achieve top performance among all models capable of real-time inference. We validate the advantage of our model on scene flow estimation with longer temporal gaps, up to 0.5 seconds where other models fail to deliver meaningful results.
BaSAL: Size Balanced Warm Start Active Learning for LiDAR Semantic Segmentation
Oct 12, 2023Active learning strives to reduce the need for costly data annotation, by repeatedly querying an annotator to label the most informative samples from a pool of unlabeled data and retraining a model from these samples. We identify two problems with existing active learning methods for LiDAR semantic segmentation. First, they ignore the severe class imbalance inherent in LiDAR semantic segmentation datasets. Second, to bootstrap the active learning loop, they train their initial model from randomly selected data samples, which leads to low performance and is referred to as the cold start problem. To address these problems we propose BaSAL, a size-balanced warm start active learning model, based on the observation that each object class has a characteristic size. By sampling object clusters according to their size, we can thus create a size-balanced dataset that is also more class-balanced. Furthermore, in contrast to existing information measures like entropy or CoreSet, size-based sampling does not require an already trained model and thus can be used to address the cold start problem. Results show that we are able to improve the performance of the initial model by a large margin. Combining size-balanced sampling and warm start with established information measures, our approach achieves a comparable performance to training on the entire SemanticKITTI dataset, despite using only 5% of the annotations, which outperforms existing active learning methods. We also match the existing state-of-the-art in active learning on nuScenes. Our code will be made available upon paper acceptance.
A step towards understanding why classification helps regression
Aug 21, 2023A number of computer vision deep regression approaches report improved results when adding a classification loss to the regression loss. Here, we explore why this is useful in practice and when it is beneficial. To do so, we start from precisely controlled dataset variations and data samplings and find that the effect of adding a classification loss is the most pronounced for regression with imbalanced data. We explain these empirical findings by formalizing the relation between the balanced and imbalanced regression losses. Finally, we show that our findings hold on two real imbalanced image datasets for depth estimation (NYUD2-DIR), and age estimation (IMDB-WIKI-DIR), and on the problem of imbalanced video progress prediction (Breakfast). Our main takeaway is: for a regression task, if the data sampling is imbalanced, then add a classification loss.
Deep vanishing point detection: Geometric priors make dataset variations vanish
Mar 16, 2022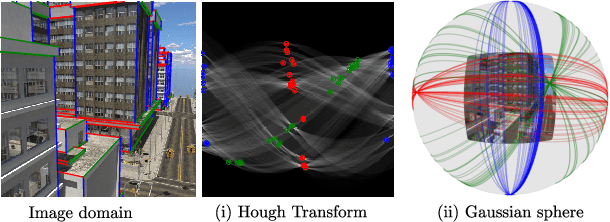
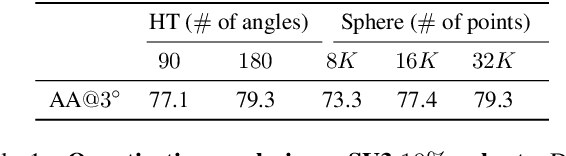
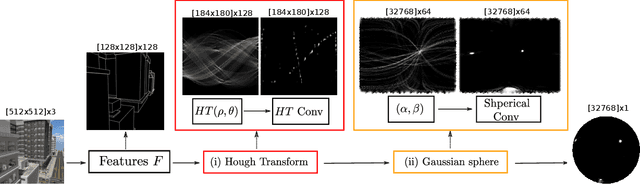
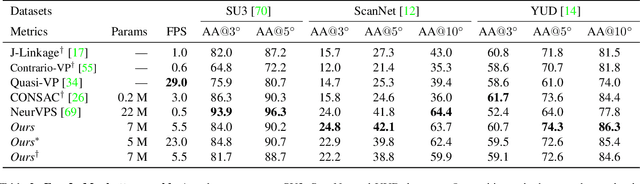
Deep learning has improved vanishing point detection in images. Yet, deep networks require expensive annotated datasets trained on costly hardware and do not generalize to even slightly different domains, and minor problem variants. Here, we address these issues by injecting deep vanishing point detection networks with prior knowledge. This prior knowledge no longer needs to be learned from data, saving valuable annotation efforts and compute, unlocking realistic few-sample scenarios, and reducing the impact of domain changes. Moreover, the interpretability of the priors allows to adapt deep networks to minor problem variations such as switching between Manhattan and non-Manhattan worlds. We seamlessly incorporate two geometric priors: (i) Hough Transform -- mapping image pixels to straight lines, and (ii) Gaussian sphere -- mapping lines to great circles whose intersections denote vanishing points. Experimentally, we ablate our choices and show comparable accuracy to existing models in the large-data setting. We validate our model's improved data efficiency, robustness to domain changes, adaptability to non-Manhattan settings.
Data-efficient learning for 3D mirror symmetry detection
Dec 23, 2021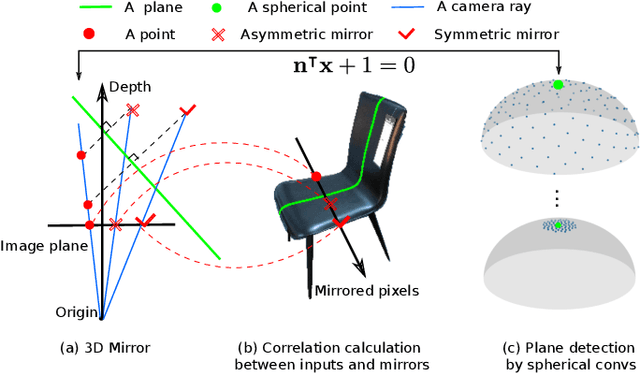
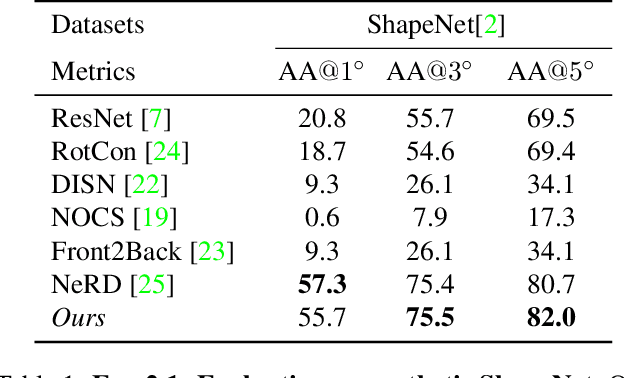
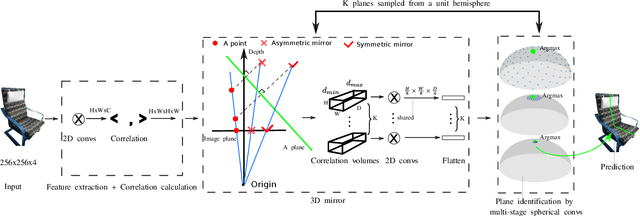
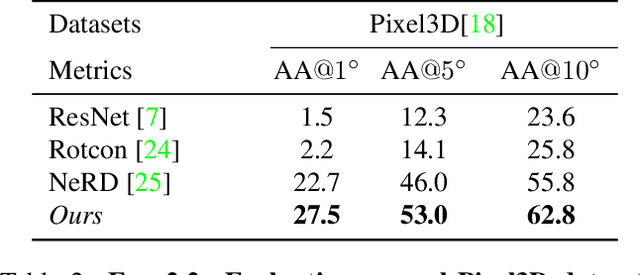
We introduce a geometry-inspired deep learning method for detecting 3D mirror plane from single-view images. We reduce the demand for massive training data by explicitly adding 3D mirror geometry into learning as an inductive prior. We extract semantic features, calculate intra-pixel correlations, and build a 3D correlation volume for each plane. The correlation volume indicates the extent to which the input resembles its mirrors at various depth, allowing us to identify the likelihood of the given plane being a mirror plane. Subsequently, we treat the correlation volumes as feature descriptors for sampled planes and map them to a unit hemisphere where the normal of sampled planes lies. Lastly, we design multi-stage spherical convolutions to identify the optimal mirror plane in a coarse-to-fine manner. Experiments on both synthetic and real-world datasets show the benefit of 3D mirror geometry in improving data efficiency and inference speed (up to 25 FPS).
Investigating transformers in the decomposition of polygonal shapes as point collections
Aug 17, 2021

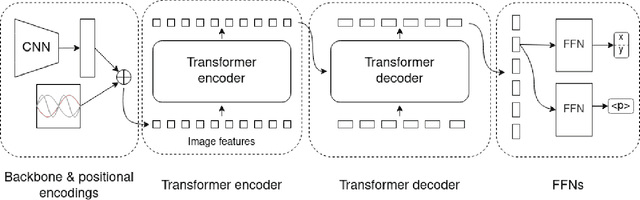

Transformers can generate predictions in two approaches: 1. auto-regressively by conditioning each sequence element on the previous ones, or 2. directly produce an output sequences in parallel. While research has mostly explored upon this difference on sequential tasks in NLP, we study the difference between auto-regressive and parallel prediction on visual set prediction tasks, and in particular on polygonal shapes in images because polygons are representative of numerous types of objects, such as buildings or obstacles for aerial vehicles. This is challenging for deep learning architectures as a polygon can consist of a varying carnality of points. We provide evidence on the importance of natural orders for Transformers, and show the benefit of decomposing complex polygons into collections of points in an auto-regressive manner.
Semi-supervised lane detection with Deep Hough Transform
Jun 09, 2021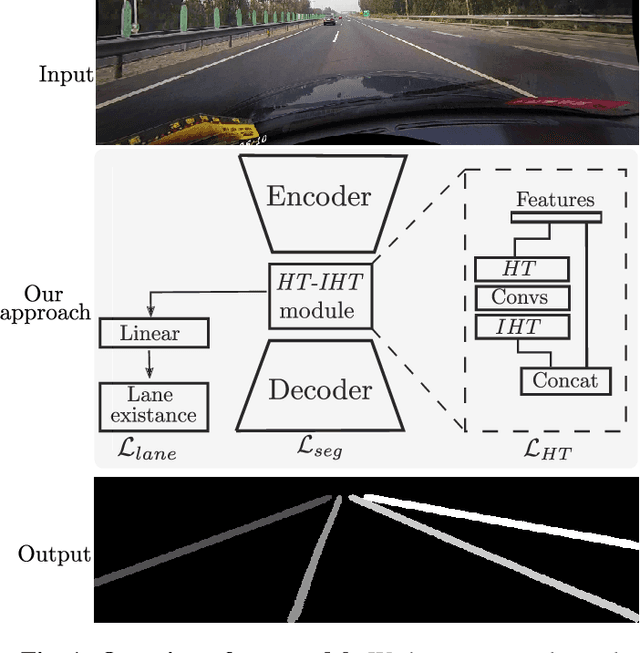
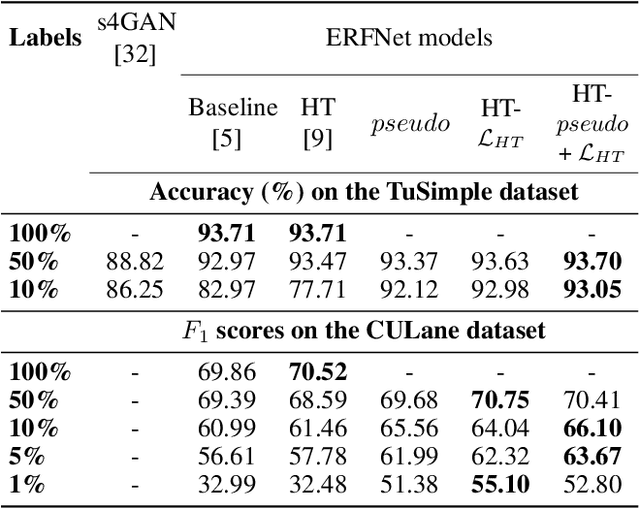

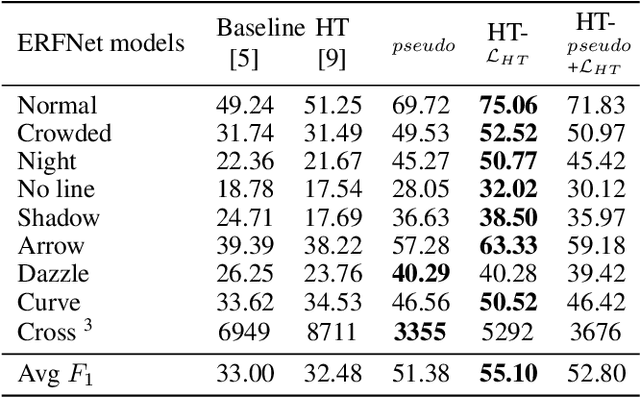
Current work on lane detection relies on large manually annotated datasets. We reduce the dependency on annotations by leveraging massive cheaply available unlabelled data. We propose a novel loss function exploiting geometric knowledge of lanes in Hough space, where a lane can be identified as a local maximum. By splitting lanes into separate channels, we can localize each lane via simple global max-pooling. The location of the maximum encodes the layout of a lane, while the intensity indicates the the probability of a lane being present. Maximizing the log-probability of the maximal bins helps neural networks find lanes without labels. On the CULane and TuSimple datasets, we show that the proposed Hough Transform loss improves performance significantly by learning from large amounts of unlabelled images.
Deep Hough-Transform Line Priors
Jul 18, 2020

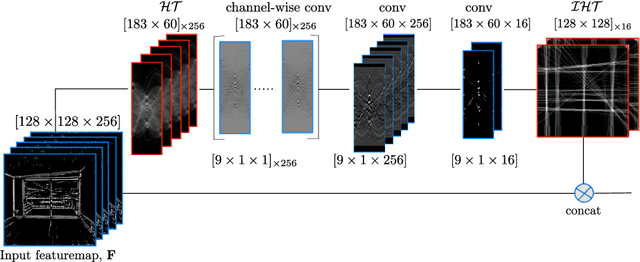
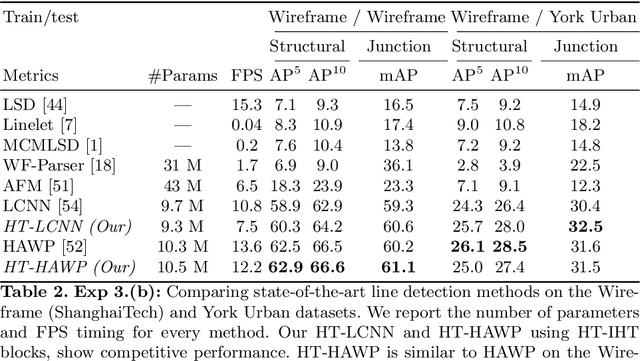
Classical work on line segment detection is knowledge-based; it uses carefully designed geometric priors using either image gradients, pixel groupings, or Hough transform variants. Instead, current deep learning methods do away with all prior knowledge and replace priors by training deep networks on large manually annotated datasets. Here, we reduce the dependency on labeled data by building on the classic knowledge-based priors while using deep networks to learn features. We add line priors through a trainable Hough transform block into a deep network. Hough transform provides the prior knowledge about global line parameterizations, while the convolutional layers can learn the local gradient-like line features. On the Wireframe (ShanghaiTech) and York Urban datasets we show that adding prior knowledge improves data efficiency as line priors no longer need to be learned from data. Keywords: Hough transform; global line prior, line segment detection.