 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep kernel video approximation for unsupervised action segmentation
Apr 23, 2026This work focuses on per-video unsupervised action segmentation, which is of interest to applications where storing large datasets is either not possible, or nor permitted. We propose to segment videos by learning in deep kernel space, to approximate the underlying frame distribution, as closely as possible. To define this closeness metric between the original video distribution and its approximation, we rely on maximum mean discrepancy (MMD) which is a geometry-preserving metric in distribution space, and thus gives more reliable estimates. Moreover, unlike the commonly used optimal transport metric, MMD is both easier to optimize, and faster. We choose to use neural tangent kernels (NTKs) to define the kernel space where MMD operates, because of their improved descriptive power as opposed to fixed kernels. And, also, because NTKs sidestep the trivial solution, when jointly learning the inputs (video approximation) and the kernel function. Finally, we show competitive results when compared to state-of-the-art per-video methods, on six standard benchmarks. Additionally, our method has higher F1 scores than prior agglomerative work, when the number of segments is unknown.
Top-K Maximum Intensity Projection Priors for 3D Liver Vessel Segmentation
Mar 05, 2025Liver-vessel segmentation is an essential task in the pre-operative planning of liver resection. State-of-the-art 2D or 3D convolution-based methods focusing on liver vessel segmentation on 2D CT cross-sectional views, which do not take into account the global liver-vessel topology. To maintain this global vessel topology, we rely on the underlying physics used in the CT reconstruction process, and apply this to liver-vessel segmentation. Concretely, we introduce the concept of top-k maximum intensity projections, which mimics the CT reconstruction by replacing the integral along each projection direction, with keeping the top-k maxima along each projection direction. We use these top-k maximum projections to condition a diffusion model and generate 3D liver-vessel trees. We evaluate our 3D liver-vessel segmentation on the 3D-ircadb-01 dataset, and achieve the highest Dice coefficient, intersection-over-union (IoU), and Sensitivity scores compared to prior work.
A Graph Attention-Guided Diffusion Model for Liver Vessel Segmentation
Nov 01, 2024Improving connectivity and completeness are the most challenging aspects of small liver vessel segmentation. It is difficult for existing methods to obtain segmented liver vessel trees simultaneously with continuous geometry and detail in small vessels. We proposed a diffusion model-based method with a multi-scale graph attention guidance to break through the bottleneck to segment the liver vessels. Experiments show that the proposed method outperforms the other state-of-the-art methods used in this study on two public datasets of 3D-ircadb-01 and LiVS. Dice coefficient and Sensitivity are improved by at least 11.67% and 24.21% on 3D-ircadb-01 dataset, and are improved by at least 3.21% and 9.11% on LiVS dataset. Connectivity is also quantitatively evaluated in this study and our method performs best. The proposed method is reliable for small liver vessel segmentation.
Deep Continuous Networks
Feb 02, 2024CNNs and computational models of biological vision share some fundamental principles, which opened new avenues of research. However, fruitful cross-field research is hampered by conventional CNN architectures being based on spatially and depthwise discrete representations, which cannot accommodate certain aspects of biological complexity such as continuously varying receptive field sizes and dynamics of neuronal responses. Here we propose deep continuous networks (DCNs), which combine spatially continuous filters, with the continuous depth framework of neural ODEs. This allows us to learn the spatial support of the filters during training, as well as model the continuous evolution of feature maps, linking DCNs closely to biological models. We show that DCNs are versatile and highly applicable to standard image classification and reconstruction problems, where they improve parameter and data efficiency, and allow for meta-parametrization. We illustrate the biological plausibility of the scale distributions learned by DCNs and explore their performance in a neuroscientifically inspired pattern completion task. Finally, we investigate an efficient implementation of DCNs by changing input contrast.
* Presented at ICML 2021
A step towards understanding why classification helps regression
Aug 21, 2023A number of computer vision deep regression approaches report improved results when adding a classification loss to the regression loss. Here, we explore why this is useful in practice and when it is beneficial. To do so, we start from precisely controlled dataset variations and data samplings and find that the effect of adding a classification loss is the most pronounced for regression with imbalanced data. We explain these empirical findings by formalizing the relation between the balanced and imbalanced regression losses. Finally, we show that our findings hold on two real imbalanced image datasets for depth estimation (NYUD2-DIR), and age estimation (IMDB-WIKI-DIR), and on the problem of imbalanced video progress prediction (Breakfast). Our main takeaway is: for a regression task, if the data sampling is imbalanced, then add a classification loss.
Is there progress in activity progress prediction?
Aug 10, 2023Activity progress prediction aims to estimate what percentage of an activity has been completed. Currently this is done with machine learning approaches, trained and evaluated on complicated and realistic video datasets. The videos in these datasets vary drastically in length and appearance. And some of the activities have unanticipated developments, making activity progression difficult to estimate. In this work, we examine the results obtained by existing progress prediction methods on these datasets. We find that current progress prediction methods seem not to extract useful visual information for the progress prediction task. Therefore, these methods fail to exceed simple frame-counting baselines. We design a precisely controlled dataset for activity progress prediction and on this synthetic dataset we show that the considered methods can make use of the visual information, when this directly relates to the progress prediction. We conclude that the progress prediction task is ill-posed on the currently used real-world datasets. Moreover, to fairly measure activity progression we advise to consider a, simple but effective, frame-counting baseline.
Objects do not disappear: Video object detection by single-frame object location anticipation
Aug 09, 2023Objects in videos are typically characterized by continuous smooth motion. We exploit continuous smooth motion in three ways. 1) Improved accuracy by using object motion as an additional source of supervision, which we obtain by anticipating object locations from a static keyframe. 2) Improved efficiency by only doing the expensive feature computations on a small subset of all frames. Because neighboring video frames are often redundant, we only compute features for a single static keyframe and predict object locations in subsequent frames. 3) Reduced annotation cost, where we only annotate the keyframe and use smooth pseudo-motion between keyframes. We demonstrate computational efficiency, annotation efficiency, and improved mean average precision compared to the state-of-the-art on four datasets: ImageNet VID, EPIC KITCHENS-55, YouTube-BoundingBoxes, and Waymo Open dataset. Our source code is available at https://github.com/L-KID/Videoobject-detection-by-location-anticipation.
Deep vanishing point detection: Geometric priors make dataset variations vanish
Mar 16, 2022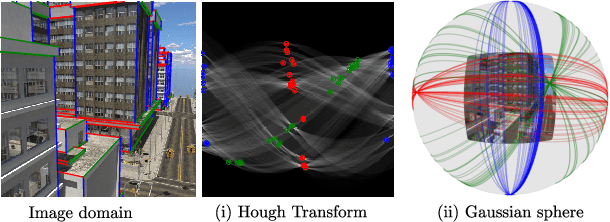
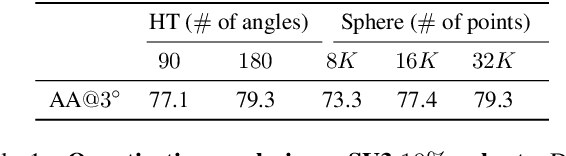
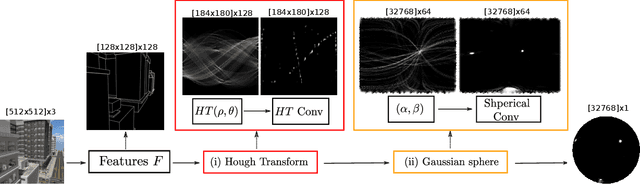
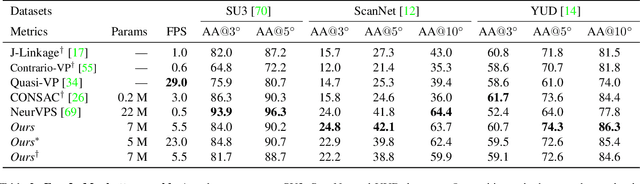
Deep learning has improved vanishing point detection in images. Yet, deep networks require expensive annotated datasets trained on costly hardware and do not generalize to even slightly different domains, and minor problem variants. Here, we address these issues by injecting deep vanishing point detection networks with prior knowledge. This prior knowledge no longer needs to be learned from data, saving valuable annotation efforts and compute, unlocking realistic few-sample scenarios, and reducing the impact of domain changes. Moreover, the interpretability of the priors allows to adapt deep networks to minor problem variations such as switching between Manhattan and non-Manhattan worlds. We seamlessly incorporate two geometric priors: (i) Hough Transform -- mapping image pixels to straight lines, and (ii) Gaussian sphere -- mapping lines to great circles whose intersections denote vanishing points. Experimentally, we ablate our choices and show comparable accuracy to existing models in the large-data setting. We validate our model's improved data efficiency, robustness to domain changes, adaptability to non-Manhattan settings.
Equal Bits: Enforcing Equally Distributed Binary Network Weights
Dec 02, 2021
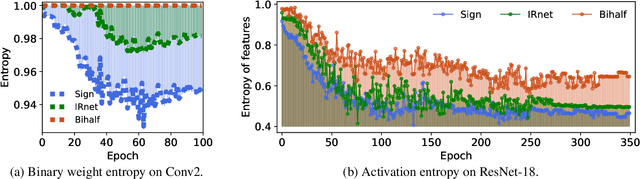

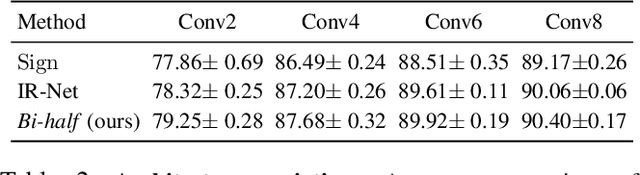
Binary networks are extremely efficient as they use only two symbols to define the network: $\{+1,-1\}$. One can make the prior distribution of these symbols a design choice. The recent IR-Net of Qin et al. argues that imposing a Bernoulli distribution with equal priors (equal bit ratios) over the binary weights leads to maximum entropy and thus minimizes information loss. However, prior work cannot precisely control the binary weight distribution during training, and therefore cannot guarantee maximum entropy. Here, we show that quantizing using optimal transport can guarantee any bit ratio, including equal ratios. We investigate experimentally that equal bit ratios are indeed preferable and show that our method leads to optimization benefits. We show that our quantization method is effective when compared to state-of-the-art binarization methods, even when using binary weight pruning.
Frequency learning for structured CNN filters with Gaussian fractional derivatives
Nov 12, 2021

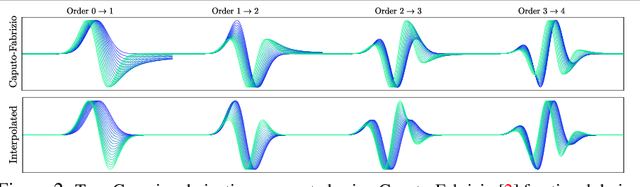

Frequency information lies at the base of discriminating between textures, and therefore between different objects. Classical CNN architectures limit the frequency learning through fixed filter sizes, and lack a way of explicitly controlling it. Here, we build on the structured receptive field filters with Gaussian derivative basis. Yet, rather than using predetermined derivative orders, which typically result in fixed frequency responses for the basis functions, we learn these. We show that by learning the order of the basis we can accurately learn the frequency of the filters, and hence adapt to the optimal frequencies for the underlying learning task. We investigate the well-founded mathematical formulation of fractional derivatives to adapt the filter frequencies during training. Our formulation leads to parameter savings and data efficiency when compared to the standard CNNs and the Gaussian derivative CNN filter networks that we build upon.