 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semi-Supervised Pipeline for Generalized Behavior Discovery from Animal-Borne Motion Time Series
Feb 02, 2026Learning behavioral taxonomies from animal-borne sensors is challenging because labels are scarce, classes are highly imbalanced, and behaviors may be absent from the annotated set. We study generalized behavior discovery in short multivariate motion snippets from gulls, where each sample is a sequence with 3-axis IMU acceleration (20 Hz) and GPS speed, spanning nine expert-annotated behavior categories. We propose a semi-supervised discovery pipeline that (i) learns an embedding function from the labeled subset, (ii) performs label-guided clustering over embeddings of both labeled and unlabeled samples to form candidate behavior groups, and (iii) decides whether a discovered group is truly novel using a containment score. Our key contribution is a KDE + HDR (highest-density region) containment score that measures how much a discovered cluster distribution is contained within, or contains, each known-class distribution; the best-match containment score serves as an interpretable novelty statistic. In experiments where an entire behavior is withheld from supervision and appears only in the unlabeled pool, the method recovers a distinct cluster and the containment score flags novelty via low overlap, while a negative-control setting with no novel behavior yields consistently higher overlaps. These results suggest that HDR-based containment provides a practical, quantitative test for generalized class discovery in ecological motion time series under limited annotation and severe class imbalance.
A Framework for Multi-View Multiple Object Tracking using Single-View Multi-Object Trackers on Fish Data
May 22, 2025Multi-object tracking (MOT) in computer vision has made significant advancements, yet tracking small fish in underwater environments presents unique challenges due to complex 3D motions and data noise. Traditional single-view MOT models often fall short in these settings. This thesis addresses these challenges by adapting state-of-the-art single-view MOT models, FairMOT and YOLOv8, for underwater fish detecting and tracking in ecological studies. The core contribution of this research is the development of a multi-view framework that utilizes stereo video inputs to enhance tracking accuracy and fish behavior pattern recognition. By integrating and evaluating these models on underwater fish video datasets, the study aims to demonstrate significant improvements in precision and reliability compared to single-view approaches. The proposed framework detects fish entities with a relative accuracy of 47% and employs stereo-matching techniques to produce a novel 3D output, providing a more comprehensive understanding of fish movements and interactions
T-MAE: Temporal Masked Autoencoders for Point Cloud Representation Learning
Dec 15, 2023



The scarcity of annotated data in outdoor point cloud segmentation poses a significant obstacle in harnessing the modeling capabilities of advanced networks like transformers. Consequently, scholars have been actively investigating efficacious self-supervised pre-training strategies, e.g. contrasting learning and reconstruction-based pretext tasks. Nevertheless, temporal information, which is inherent in the LiDAR point cloud sequence, is consistently disregarded. To better utilize this property, we propose an effective pre-training strategy, namely Temporal Masked AutoEncoders (T-MAE), which takes as input temporally adjacent frames and learns temporal dependency. A SiamWCA backbone, containing a Siamese encoder and a window-based cross-attention (WCA) module, is established for the two-frame input. Taking into account that the motion of an ego-vehicle alters the illumination angles of the same instance, temporal modeling also serves as a robust and natural data augmentation, enhancing the comprehension of target objects. Moreover, instead of utilizing consecutive frames, it is more cost-effective and powerful by using distant historical frames. SiamWCA is a powerful architecture but heavily relies on annotated data. With our T-MAE pre-training strategy, we achieve the best performance on the Waymo dataset among self-supervised learning methods. Comprehensive experiments are conducted to validate all components of our proposal. Upon acceptance, the source code will be made accessible.
APNet: Urban-level Scene Segmentation of Aerial Images and Point Clouds
Sep 29, 2023In this paper, we focus on semantic segmentation method for point clouds of urban scenes. Our fundamental concept revolves around the collaborative utilization of diverse scene representations to benefit from different context information and network architectures. To this end, the proposed network architecture, called APNet, is split into two branches: a point cloud branch and an aerial image branch which input is generated from a point cloud. To leverage the different properties of each branch, we employ a geometry-aware fusion module that is learned to combine the results of each branch. Additional separate losses for each branch avoid that one branch dominates the results, ensure the best performance for each branch individually and explicitly define the input domain of the fusion network assuring it only performs data fusion. Our experiments demonstrate that the fusion output consistently outperforms the individual network branches and that APNet achieves state-of-the-art performance of 65.2 mIoU on the SensatUrban dataset. Upon acceptance, the source code will be made accessible.
Objects do not disappear: Video object detection by single-frame object location anticipation
Aug 09, 2023Objects in videos are typically characterized by continuous smooth motion. We exploit continuous smooth motion in three ways. 1) Improved accuracy by using object motion as an additional source of supervision, which we obtain by anticipating object locations from a static keyframe. 2) Improved efficiency by only doing the expensive feature computations on a small subset of all frames. Because neighboring video frames are often redundant, we only compute features for a single static keyframe and predict object locations in subsequent frames. 3) Reduced annotation cost, where we only annotate the keyframe and use smooth pseudo-motion between keyframes. We demonstrate computational efficiency, annotation efficiency, and improved mean average precision compared to the state-of-the-art on four datasets: ImageNet VID, EPIC KITCHENS-55, YouTube-BoundingBoxes, and Waymo Open dataset. Our source code is available at https://github.com/L-KID/Videoobject-detection-by-location-anticipation.
No frame left behind: Full Video Action Recognition
Mar 29, 2021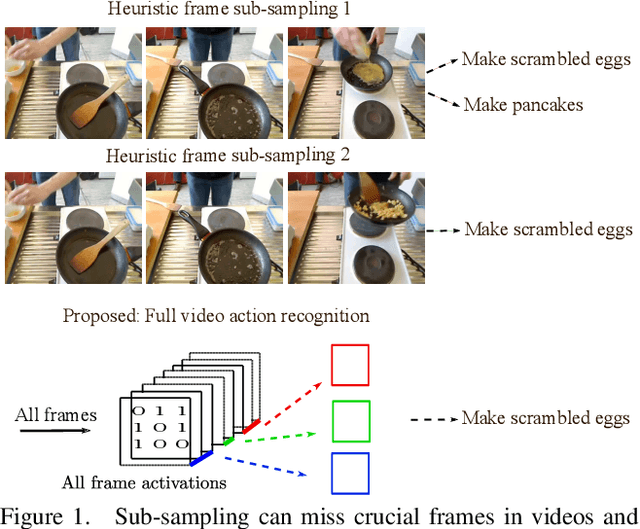

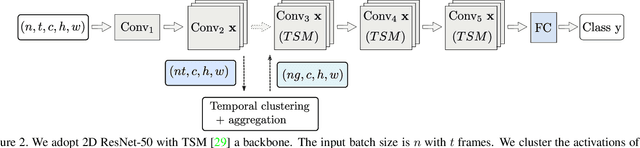
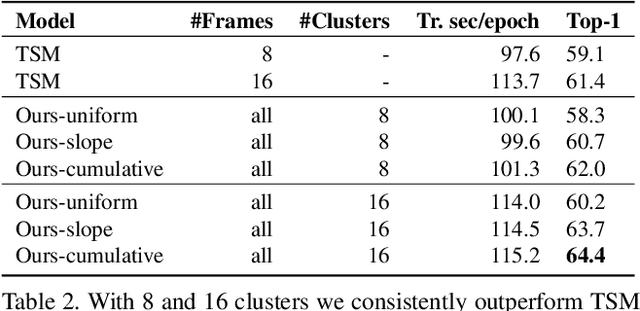
Not all video frames are equally informative for recognizing an action. It is computationally infeasible to train deep networks on all video frames when actions develop over hundreds of frames. A common heuristic is uniformly sampling a small number of video frames and using these to recognize the action. Instead, here we propose full video action recognition and consider all video frames. To make this computational tractable, we first cluster all frame activations along the temporal dimension based on their similarity with respect to the classification task, and then temporally aggregate the frames in the clusters into a smaller number of representations. Our method is end-to-end trainable and computationally efficient as it relies on temporally localized clustering in combination with fast Hamming distances in feature space. We evaluate on UCF101, HMDB51, Breakfast, and Something-Something V1 and V2, where we compare favorably to existing heuristic frame sampling methods.
KPRNet: Improving projection-based LiDAR semantic segmentation
Aug 21, 2020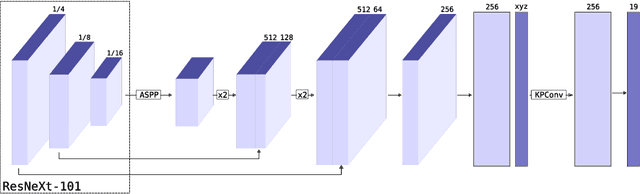
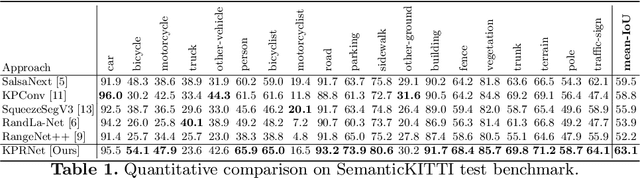
Semantic segmentation is an important component in the perception systems of autonomous vehicles. In this work, we adopt recent advances in both image and point cloud segmentation to achieve a better accuracy in the task of segmenting LiDAR scans. KPRNet improves the convolutional neural network architecture of 2D projection methods and utilizes KPConv to replace the commonly used post-processing techniques with a learnable point-wise component which allows us to obtain more accurate 3D labels. With these improvements our model outperforms the current best method on the SemanticKITTI benchmark, reaching an mIoU of 63.1.