 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep activity propagation via weight initialization in spiking neural networks
Oct 01, 2024Spiking Neural Networks (SNNs) and neuromorphic computing offer bio-inspired advantages such as sparsity and ultra-low power consumption, providing a promising alternative to conventional networks. However, training deep SNNs from scratch remains a challenge, as SNNs process and transmit information by quantizing the real-valued membrane potentials into binary spikes. This can lead to information loss and vanishing spikes in deeper layers, impeding effective training. While weight initialization is known to be critical for training deep neural networks, what constitutes an effective initial state for a deep SNN is not well-understood. Existing weight initialization methods designed for conventional networks (ANNs) are often applied to SNNs without accounting for their distinct computational properties. In this work we derive an optimal weight initialization method specifically tailored for SNNs, taking into account the quantization operation. We show theoretically that, unlike standard approaches, this method enables the propagation of activity in deep SNNs without loss of spikes. We demonstrate this behavior in numerical simulations of SNNs with up to 100 layers across multiple time steps. We present an in-depth analysis of the numerical conditions, regarding layer width and neuron hyperparameters, which are necessary to accurately apply our theoretical findings. Furthermore, our experiments on MNIST demonstrate higher accuracy and faster convergence when using the proposed weight initialization scheme. Finally, we show that the newly introduced weight initialization is robust against variations in several network and neuron hyperparameters.
Objects do not disappear: Video object detection by single-frame object location anticipation
Aug 09, 2023Objects in videos are typically characterized by continuous smooth motion. We exploit continuous smooth motion in three ways. 1) Improved accuracy by using object motion as an additional source of supervision, which we obtain by anticipating object locations from a static keyframe. 2) Improved efficiency by only doing the expensive feature computations on a small subset of all frames. Because neighboring video frames are often redundant, we only compute features for a single static keyframe and predict object locations in subsequent frames. 3) Reduced annotation cost, where we only annotate the keyframe and use smooth pseudo-motion between keyframes. We demonstrate computational efficiency, annotation efficiency, and improved mean average precision compared to the state-of-the-art on four datasets: ImageNet VID, EPIC KITCHENS-55, YouTube-BoundingBoxes, and Waymo Open dataset. Our source code is available at https://github.com/L-KID/Videoobject-detection-by-location-anticipation.
Convolutional Cross-View Pose Estimation
Mar 09, 2023We propose a novel end-to-end method for cross-view pose estimation. Given a ground-level query image and an aerial image that covers the query's local neighborhood, the 3 Degrees-of-Freedom camera pose of the query is estimated by matching its image descriptor to descriptors of local regions within the aerial image. The orientation-aware descriptors are obtained by using a translational equivariant convolutional ground image encoder and contrastive learning. The Localization Decoder produces a dense probability distribution in a coarse-to-fine manner with a novel Localization Matching Upsampling module. A smaller Orientation Decoder produces a vector field to condition the orientation estimate on the localization. Our method is validated on the VIGOR and KITTI datasets, where it surpasses the state-of-the-art baseline by 72% and 36% in median localization error for comparable orientation estimation accuracy. The predicted probability distribution can represent localization ambiguity, and enables rejecting possible erroneous predictions. Without re-training, the model can infer on ground images with different field of views and utilize orientation priors if available. On the Oxford RobotCar dataset, our method can reliably estimate the ego-vehicle's pose over time, achieving a median localization error under 1 meter and a median orientation error of around 1 degree at 14 FPS.
Visual Cross-View Metric Localization with Dense Uncertainty Estimates
Aug 17, 2022

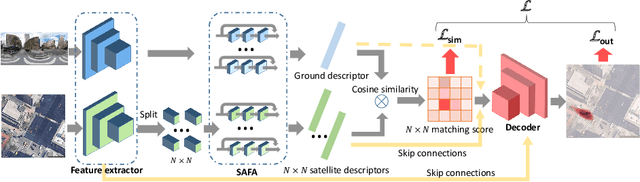
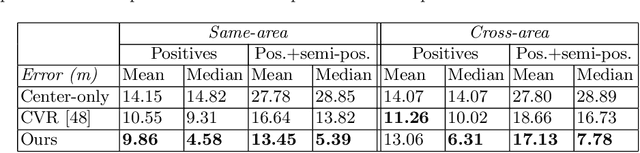
This work addresses visual cross-view metric localization for outdoor robotics. Given a ground-level color image and a satellite patch that contains the local surroundings, the task is to identify the location of the ground camera within the satellite patch. Related work addressed this task for range-sensors (LiDAR, Radar), but for vision, only as a secondary regression step after an initial cross-view image retrieval step. Since the local satellite patch could also be retrieved through any rough localization prior (e.g. from GPS/GNSS, temporal filtering), we drop the image retrieval objective and focus on the metric localization only. We devise a novel network architecture with denser satellite descriptors, similarity matching at the bottleneck (rather than at the output as in image retrieval), and a dense spatial distribution as output to capture multi-modal localization ambiguities. We compare against a state-of-the-art regression baseline that uses global image descriptors. Quantitative and qualitative experimental results on the recently proposed VIGOR and the Oxford RobotCar datasets validate our design. The produced probabilities are correlated with localization accuracy, and can even be used to roughly estimate the ground camera's heading when its orientation is unknown. Overall, our method reduces the median metric localization error by 51%, 37%, and 28% compared to the state-of-the-art when generalizing respectively in the same area, across areas, and across time.
No frame left behind: Full Video Action Recognition
Mar 29, 2021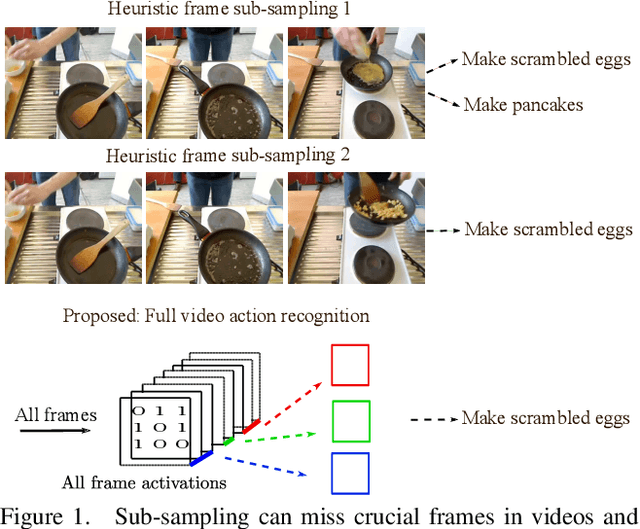

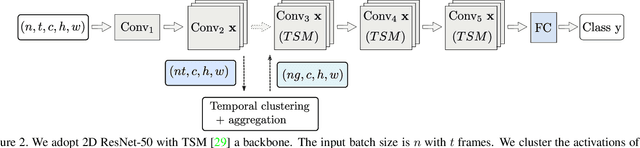
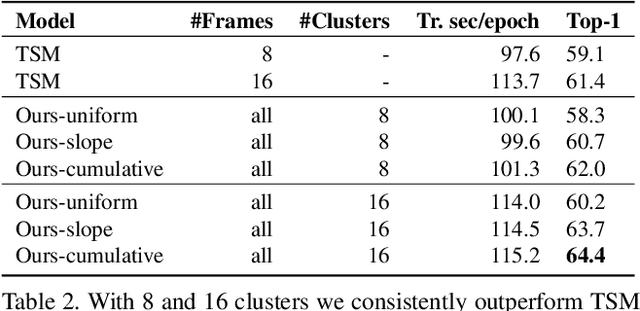
Not all video frames are equally informative for recognizing an action. It is computationally infeasible to train deep networks on all video frames when actions develop over hundreds of frames. A common heuristic is uniformly sampling a small number of video frames and using these to recognize the action. Instead, here we propose full video action recognition and consider all video frames. To make this computational tractable, we first cluster all frame activations along the temporal dimension based on their similarity with respect to the classification task, and then temporally aggregate the frames in the clusters into a smaller number of representations. Our method is end-to-end trainable and computationally efficient as it relies on temporally localized clustering in combination with fast Hamming distances in feature space. We evaluate on UCF101, HMDB51, Breakfast, and Something-Something V1 and V2, where we compare favorably to existing heuristic frame sampling methods.
Adversarial Self-Supervised Scene Flow Estimation
Nov 01, 2020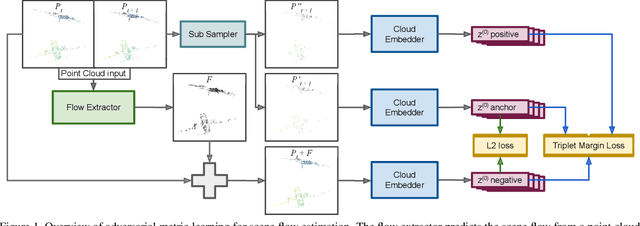
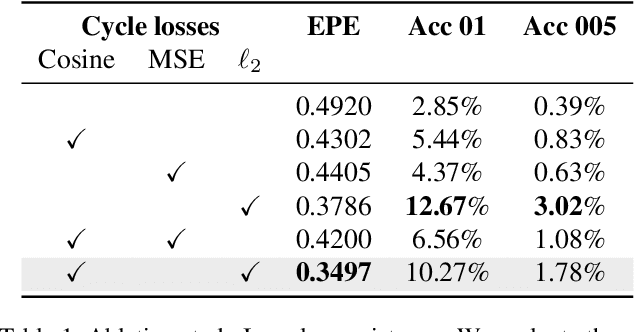
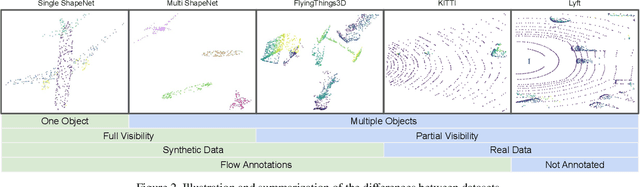
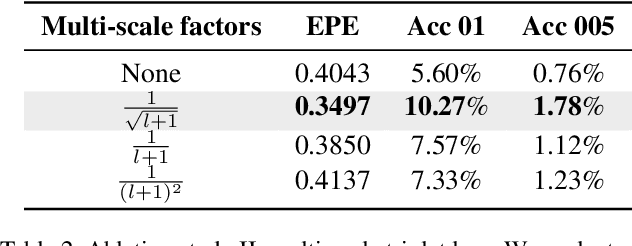
This work proposes a metric learning approach for self-supervised scene flow estimation. Scene flow estimation is the task of estimating 3D flow vectors for consecutive 3D point clouds. Such flow vectors are fruitful, \eg for recognizing actions, or avoiding collisions. Training a neural network via supervised learning for scene flow is impractical, as this requires manual annotations for each 3D point at each new timestamp for each scene. To that end, we seek for a self-supervised approach, where a network learns a latent metric to distinguish between points translated by flow estimations and the target point cloud. Our adversarial metric learning includes a multi-scale triplet loss on sequences of two-point clouds as well as a cycle consistency loss. Furthermore, we outline a benchmark for self-supervised scene flow estimation: the Scene Flow Sandbox. The benchmark consists of five datasets designed to study individual aspects of flow estimation in progressive order of complexity, from a moving object to real-world scenes. Experimental evaluation on the benchmark shows that our approach obtains state-of-the-art self-supervised scene flow results, outperforming recent neighbor-based approaches. We use our proposed benchmark to expose shortcomings and draw insights on various training setups. We find that our setup captures motion coherence and preserves local geometries. Dealing with occlusions, on the other hand, is still an open challenge.
KPRNet: Improving projection-based LiDAR semantic segmentation
Aug 21, 2020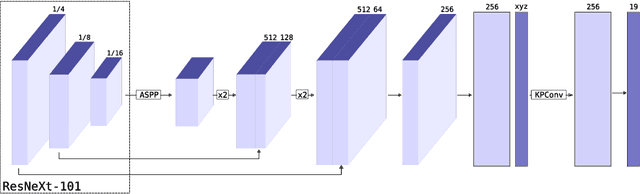
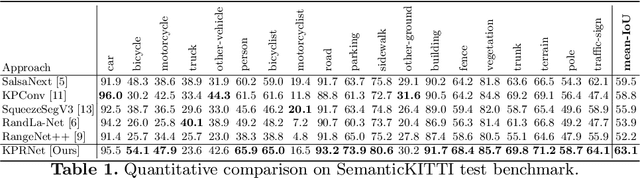
Semantic segmentation is an important component in the perception systems of autonomous vehicles. In this work, we adopt recent advances in both image and point cloud segmentation to achieve a better accuracy in the task of segmenting LiDAR scans. KPRNet improves the convolutional neural network architecture of 2D projection methods and utilizes KPConv to replace the commonly used post-processing techniques with a learnable point-wise component which allows us to obtain more accurate 3D labels. With these improvements our model outperforms the current best method on the SemanticKITTI benchmark, reaching an mIoU of 63.1.
Exploiting Temporality for Semi-Supervised Video Segmentation
Aug 29, 2019
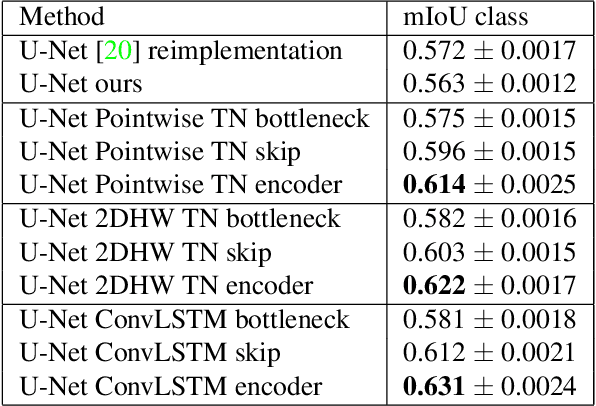
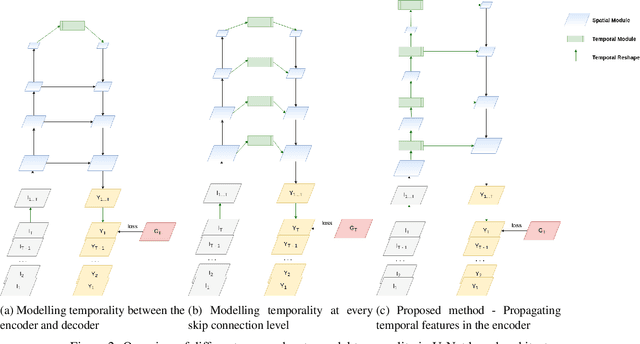
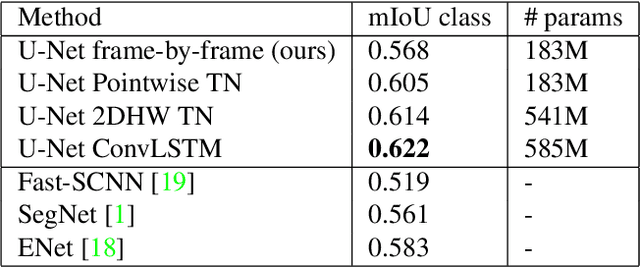
In recent years, there has been remarkable progress in supervised image segmentation. Video segmentation is less explored, despite the temporal dimension being highly informative. Semantic labels, e.g. that cannot be accurately detected in the current frame, may be inferred by incorporating information from previous frames. However, video segmentation is challenging due to the amount of data that needs to be processed and, more importantly, the cost involved in obtaining ground truth annotations for each frame. In this paper, we tackle the issue of label scarcity by using consecutive frames of a video, where only one frame is annotated. We propose a deep, end-to-end trainable model which leverages temporal information in order to make use of easy to acquire unlabeled data. Our network architecture relies on a novel interconnection of two components: a fully convolutional network to model spatial information and temporal units that are employed at intermediate levels of the convolutional network in order to propagate information through time. The main contribution of this work is the guidance of the temporal signal through the network. We show that only placing a temporal module between the encoder and decoder is suboptimal (baseline). Our extensive experiments on the CityScapes dataset indicate that the resulting model can leverage unlabeled temporal frames and significantly outperform both the frame-by-frame image segmentation and the baseline approach.
I Bet You Are Wrong: Gambling Adversarial Networks for Structured Semantic Segmentation
Aug 07, 2019

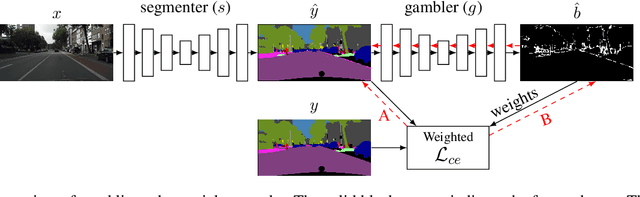
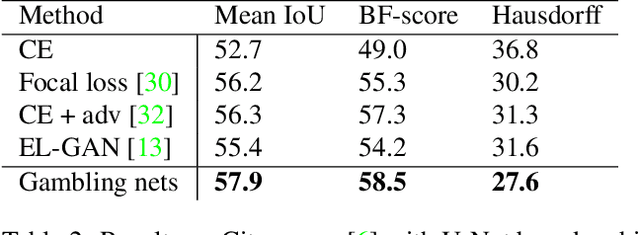
Adversarial training has been recently employed for realizing structured semantic segmentation, in which the aim is to preserve higher-level scene structural consistencies in dense predictions. However, as we show, value-based discrimination between the predictions from the segmentation network and ground-truth annotations can hinder the training process from learning to improve structural qualities as well as disabling the network from properly expressing uncertainties. In this paper, we rethink adversarial training for semantic segmentation and propose to formulate the fake/real discrimination framework with a correct/incorrect training objective. More specifically, we replace the discriminator with a "gambler" network that learns to spot and distribute its budget in areas where the predictions are clearly wrong, while the segmenter network tries to leave no clear clues for the gambler where to bet. Empirical evaluation on two road-scene semantic segmentation tasks shows that not only does the proposed method re-enable expressing uncertainties, it also improves pixel-wise and structure-based metrics.
EL-GAN: Embedding Loss Driven Generative Adversarial Networks for Lane Detection
Jul 05, 2018
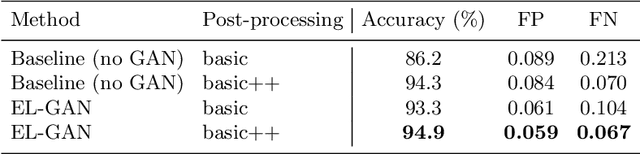
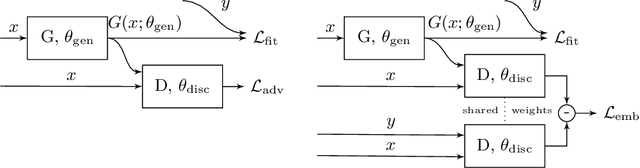
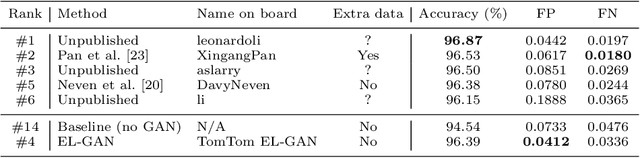
Convolutional neural networks have been successfully applied to semantic segmentation problems. However, there are many problems that are inherently not pixel-wise classification problems but are nevertheless frequently formulated as semantic segmentation. This ill-posed formulation consequently necessitates hand-crafted scenario-specific and computationally expensive post-processing methods to convert the per pixel probability maps to final desired outputs. Generative adversarial networks (GANs) can be used to make the semantic segmentation network output to be more realistic or better structure-preserving, decreasing the dependency on potentially complex post-processing. In this work, we propose EL-GAN: a GAN framework to mitigate the discussed problem using an embedding loss. With EL-GAN, we discriminate based on learned embeddings of both the labels and the prediction at the same time. This results in more stable training due to having better discriminative information, benefiting from seeing both `fake' and `real' predictions at the same time. This substantially stabilizes the adversarial training process. We use the TuSimple lane marking challenge to demonstrate that with our proposed framework it is viable to overcome the inherent anomalies of posing it as a semantic segmentation problem. Not only is the output considerably more similar to the labels when compared to conventional methods, the subsequent post-processing is also simpler and crosses the competitive 96% accuracy threshold.