 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Bet You Are Wrong: Gambling Adversarial Networks for Structured Semantic Segmentation
Paper and Code
Aug 07, 2019

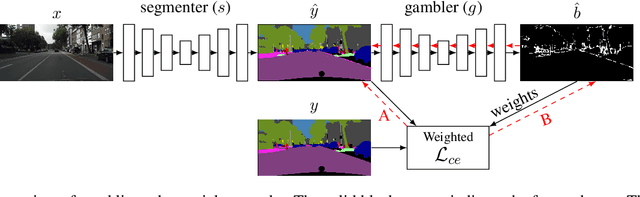
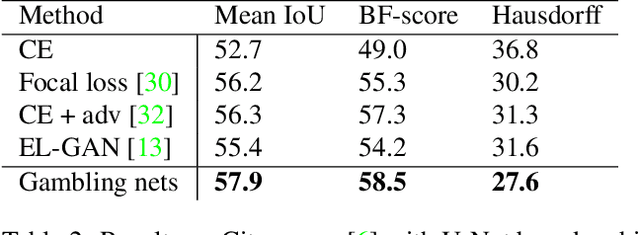
Adversarial training has been recently employed for realizing structured semantic segmentation, in which the aim is to preserve higher-level scene structural consistencies in dense predictions. However, as we show, value-based discrimination between the predictions from the segmentation network and ground-truth annotations can hinder the training process from learning to improve structural qualities as well as disabling the network from properly expressing uncertainties. In this paper, we rethink adversarial training for semantic segmentation and propose to formulate the fake/real discrimination framework with a correct/incorrect training objective. More specifically, we replace the discriminator with a "gambler" network that learns to spot and distribute its budget in areas where the predictions are clearly wrong, while the segmenter network tries to leave no clear clues for the gambler where to bet. Empirical evaluation on two road-scene semantic segmentation tasks shows that not only does the proposed method re-enable expressing uncertainties, it also improves pixel-wise and structure-based metrics.