 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFind it if You Can: End-to-End Adversarial Erasing for Weakly-Supervised Semantic Segmentation
Nov 09, 2020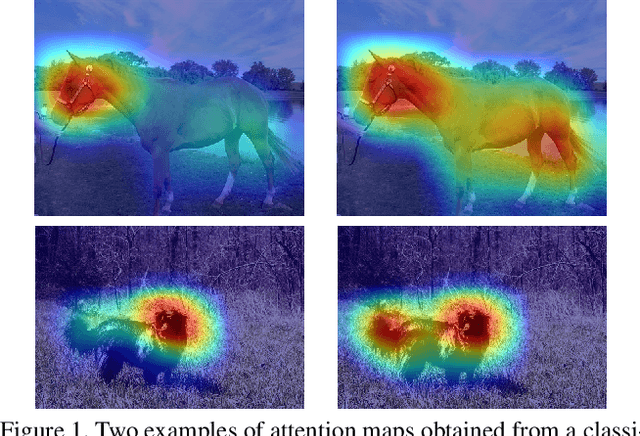
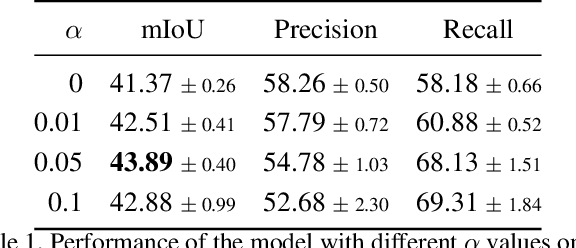


Semantic segmentation is a task that traditionally requires a large dataset of pixel-level ground truth labels, which is time-consuming and expensive to obtain. Recent advancements in the weakly-supervised setting show that reasonable performance can be obtained by using only image-level labels. Classification is often used as a proxy task to train a deep neural network from which attention maps are extracted. However, the classification task needs only the minimum evidence to make predictions, hence it focuses on the most discriminative object regions. To overcome this problem, we propose a novel formulation of adversarial erasing of the attention maps. In contrast to previous adversarial erasing methods, we optimize two networks with opposing loss functions, which eliminates the requirement of certain suboptimal strategies; for instance, having multiple training steps that complicate the training process or a weight sharing policy between networks operating on different distributions that might be suboptimal for performance. The proposed solution does not require saliency masks, instead it uses a regularization loss to prevent the attention maps from spreading to less discriminative object regions. Our experiments on the Pascal VOC dataset demonstrate that our adversarial approach increases segmentation performance by 2.1 mIoU compared to our baseline and by 1.0 mIoU compared to previous adversarial erasing approaches.
VATLD: A Visual Analytics System to Assess, Understand and Improve Traffic Light Detection
Sep 27, 2020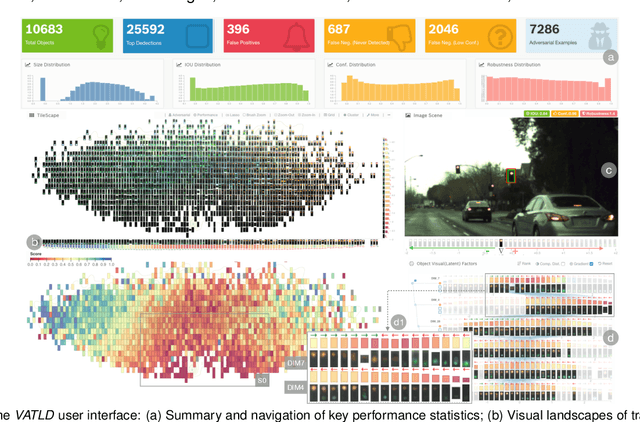
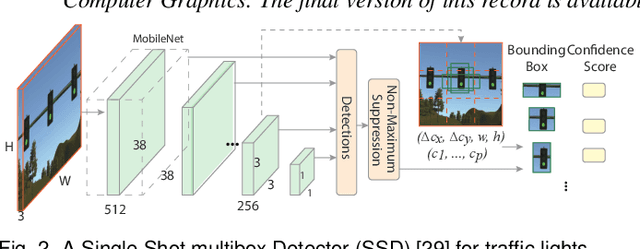

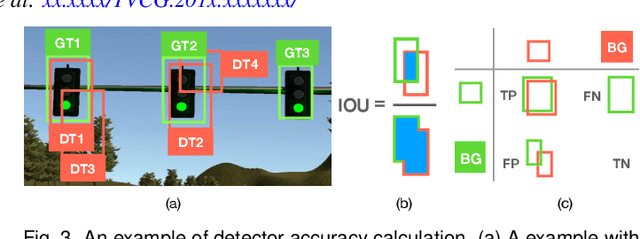
Traffic light detection is crucial for environment perception and decision-making in autonomous driving. State-of-the-art detectors are built upon deep Convolutional Neural Networks (CNNs) and have exhibited promising performance. However, one looming concern with CNN based detectors is how to thoroughly evaluate the performance of accuracy and robustness before they can be deployed to autonomous vehicles. In this work, we propose a visual analytics system, VATLD, equipped with a disentangled representation learning and semantic adversarial learning, to assess, understand, and improve the accuracy and robustness of traffic light detectors in autonomous driving applications. The disentangled representation learning extracts data semantics to augment human cognition with human-friendly visual summarization, and the semantic adversarial learning efficiently exposes interpretable robustness risks and enables minimal human interaction for actionable insights. We also demonstrate the effectiveness of various performance improvement strategies derived from actionable insights with our visual analytics system, VATLD, and illustrate some practical implications for safety-critical applications in autonomous driving.
I Bet You Are Wrong: Gambling Adversarial Networks for Structured Semantic Segmentation
Aug 07, 2019

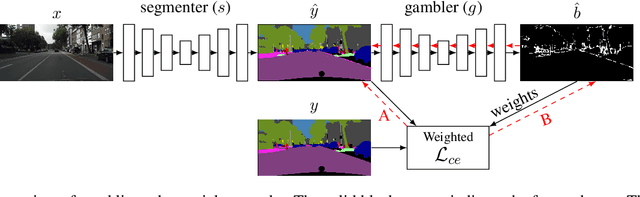
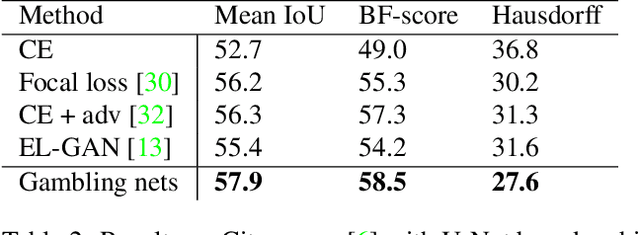
Adversarial training has been recently employed for realizing structured semantic segmentation, in which the aim is to preserve higher-level scene structural consistencies in dense predictions. However, as we show, value-based discrimination between the predictions from the segmentation network and ground-truth annotations can hinder the training process from learning to improve structural qualities as well as disabling the network from properly expressing uncertainties. In this paper, we rethink adversarial training for semantic segmentation and propose to formulate the fake/real discrimination framework with a correct/incorrect training objective. More specifically, we replace the discriminator with a "gambler" network that learns to spot and distribute its budget in areas where the predictions are clearly wrong, while the segmenter network tries to leave no clear clues for the gambler where to bet. Empirical evaluation on two road-scene semantic segmentation tasks shows that not only does the proposed method re-enable expressing uncertainties, it also improves pixel-wise and structure-based metrics.
Dynamic Adaptation on Non-Stationary Visual Domains
Aug 02, 2018
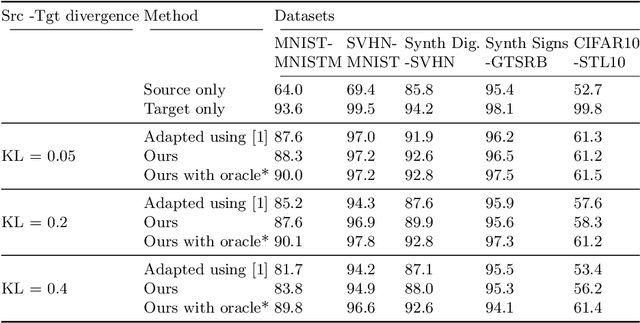

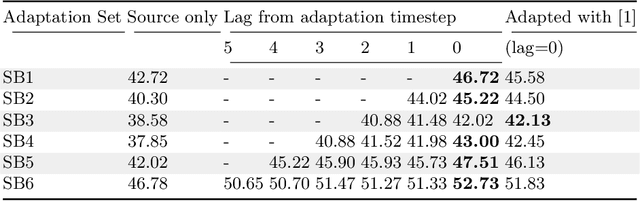
Domain adaptation aims to learn models on a supervised source domain that perform well on an unsupervised target. Prior work has examined domain adaptation in the context of stationary domain shifts, i.e. static data sets. However, with large-scale or dynamic data sources, data from a defined domain is not usually available all at once. For instance, in a streaming data scenario, dataset statistics effectively become a function of time. We introduce a framework for adaptation over non-stationary distribution shifts applicable to large-scale and streaming data scenarios. The model is adapted sequentially over incoming unsupervised streaming data batches. This enables improvements over several batches without the need for any additionally annotated data. To demonstrate the effectiveness of our proposed framework, we modify associative domain adaptation to work well on source and target data batches with unequal class distributions. We apply our method to several adaptation benchmark datasets for classification and show improved classifier accuracy not only for the currently adapted batch, but also when applied on future stream batches. Furthermore, we show the applicability of our associative learning modifications to semantic segmentation, where we achieve competitive results.
EL-GAN: Embedding Loss Driven Generative Adversarial Networks for Lane Detection
Jul 05, 2018
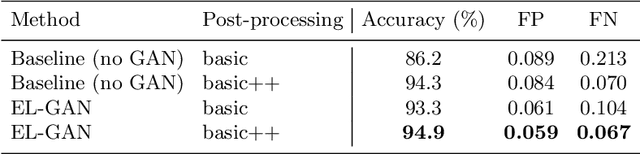
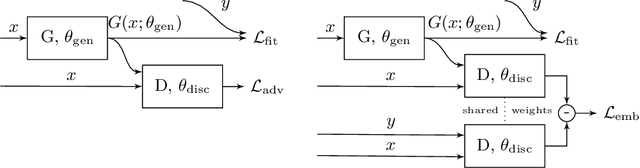
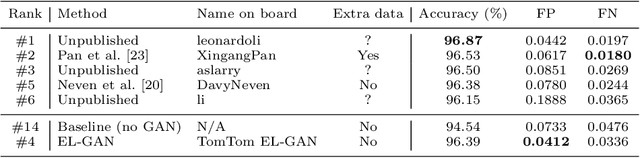
Convolutional neural networks have been successfully applied to semantic segmentation problems. However, there are many problems that are inherently not pixel-wise classification problems but are nevertheless frequently formulated as semantic segmentation. This ill-posed formulation consequently necessitates hand-crafted scenario-specific and computationally expensive post-processing methods to convert the per pixel probability maps to final desired outputs. Generative adversarial networks (GANs) can be used to make the semantic segmentation network output to be more realistic or better structure-preserving, decreasing the dependency on potentially complex post-processing. In this work, we propose EL-GAN: a GAN framework to mitigate the discussed problem using an embedding loss. With EL-GAN, we discriminate based on learned embeddings of both the labels and the prediction at the same time. This results in more stable training due to having better discriminative information, benefiting from seeing both `fake' and `real' predictions at the same time. This substantially stabilizes the adversarial training process. We use the TuSimple lane marking challenge to demonstrate that with our proposed framework it is viable to overcome the inherent anomalies of posing it as a semantic segmentation problem. Not only is the output considerably more similar to the labels when compared to conventional methods, the subsequent post-processing is also simpler and crosses the competitive 96% accuracy threshold.
US-Cut: Interactive Algorithm for rapid Detection and Segmentation of Liver Tumors in Ultrasound Acquisitions
Mar 02, 2016Ultrasound (US) is the most commonly used liver imaging modality worldwide. It plays an important role in follow-up of cancer patients with liver metastases. We present an interactive segmentation approach for liver tumors in US acquisitions. Due to the low image quality and the low contrast between the tumors and the surrounding tissue in US images, the segmentation is very challenging. Thus, the clinical practice still relies on manual measurement and outlining of the tumors in the US images. We target this problem by applying an interactive segmentation algorithm to the US data, allowing the user to get real-time feedback of the segmentation results. The algorithm has been developed and tested hand-in-hand by physicians and computer scientists to make sure a future practical usage in a clinical setting is feasible. To cover typical acquisitions from the clinical routine, the approach has been evaluated with dozens of datasets where the tumors are hyperechoic (brighter), hypoechoic (darker) or isoechoic (similar) in comparison to the surrounding liver tissue. Due to the interactive real-time behavior of the approach, it was possible even in difficult cases to find satisfying segmentations of the tumors within seconds and without parameter settings, and the average tumor deviation was only 1.4mm compared with manual measurements. However, the long term goal is to ease the volumetric acquisition of liver tumors in order to evaluate for treatment response. Additional aim is the registration of intraoperative US images via the interactive segmentations to the patient's pre-interventional CT acquisitions.
* 6 pages, 6 figures, 1 table, 32 references
Interactive Volumetry Of Liver Ablation Zones
Oct 21, 2015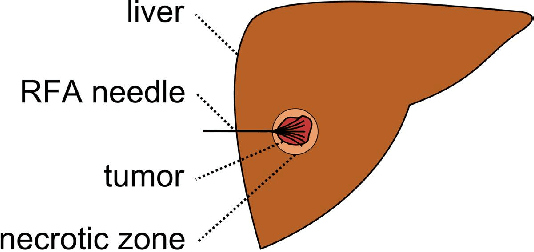
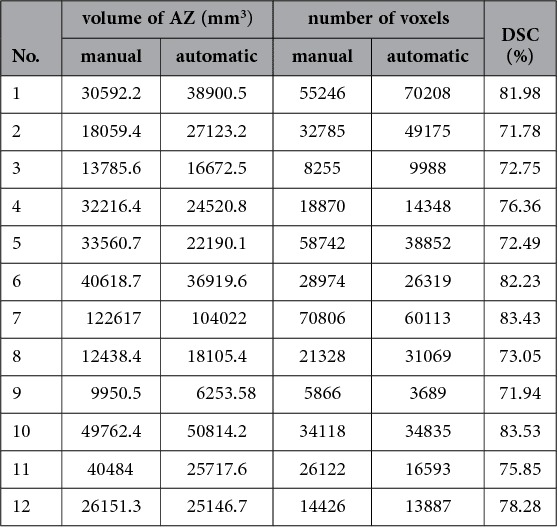
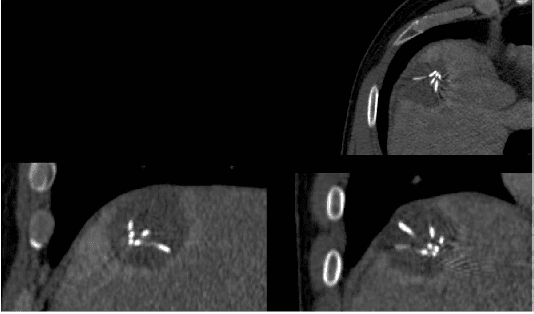
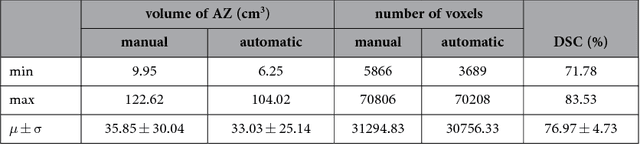
Percutaneous radiofrequency ablation (RFA) is a minimally invasive technique that destroys cancer cells by heat. The heat results from focusing energy in the radiofrequency spectrum through a needle. Amongst others, this can enable the treatment of patients who are not eligible for an open surgery. However, the possibility of recurrent liver cancer due to incomplete ablation of the tumor makes post-interventional monitoring via regular follow-up scans mandatory. These scans have to be carefully inspected for any conspicuousness. Within this study, the RF ablation zones from twelve post-interventional CT acquisitions have been segmented semi-automatically to support the visual inspection. An interactive, graph-based contouring approach, which prefers spherically shaped regions, has been applied. For the quantitative and qualitative analysis of the algorithm's results, manual slice-by-slice segmentations produced by clinical experts have been used as the gold standard (which have also been compared among each other). As evaluation metric for the statistical validation, the Dice Similarity Coefficient (DSC) has been calculated. The results show that the proposed tool provides lesion segmentation with sufficient accuracy much faster than manual segmentation. The visual feedback and interactivity make the proposed tool well suitable for the clinical workflow.
* 18 pages, 15 figures, 8 tables, 57 references