 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFind it if You Can: End-to-End Adversarial Erasing for Weakly-Supervised Semantic Segmentation
Nov 09, 2020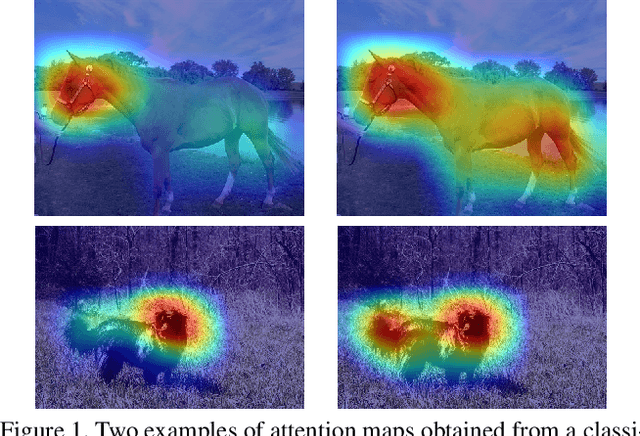
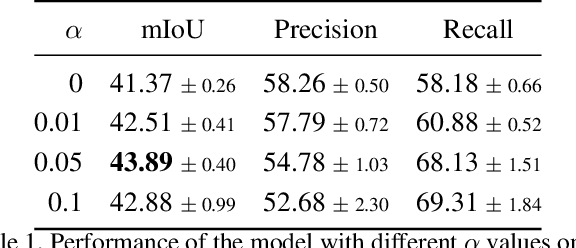


Semantic segmentation is a task that traditionally requires a large dataset of pixel-level ground truth labels, which is time-consuming and expensive to obtain. Recent advancements in the weakly-supervised setting show that reasonable performance can be obtained by using only image-level labels. Classification is often used as a proxy task to train a deep neural network from which attention maps are extracted. However, the classification task needs only the minimum evidence to make predictions, hence it focuses on the most discriminative object regions. To overcome this problem, we propose a novel formulation of adversarial erasing of the attention maps. In contrast to previous adversarial erasing methods, we optimize two networks with opposing loss functions, which eliminates the requirement of certain suboptimal strategies; for instance, having multiple training steps that complicate the training process or a weight sharing policy between networks operating on different distributions that might be suboptimal for performance. The proposed solution does not require saliency masks, instead it uses a regularization loss to prevent the attention maps from spreading to less discriminative object regions. Our experiments on the Pascal VOC dataset demonstrate that our adversarial approach increases segmentation performance by 2.1 mIoU compared to our baseline and by 1.0 mIoU compared to previous adversarial erasing approaches.
Cloth in the Wind: A Case Study of Physical Measurement through Simulation
Mar 09, 2020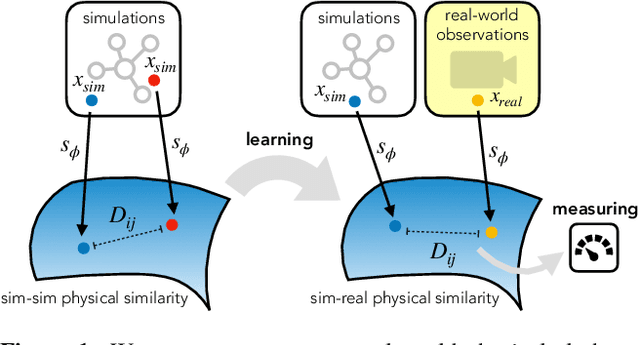
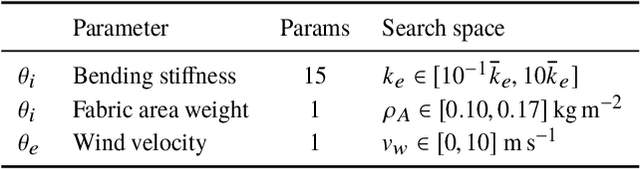

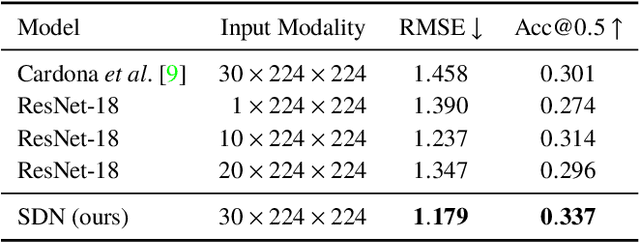
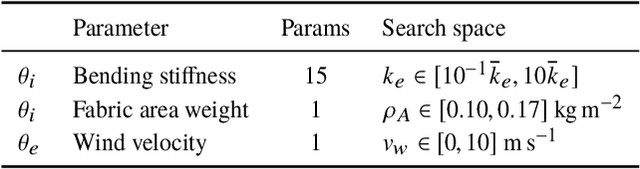
For many of the physical phenomena around us, we have developed sophisticated models explaining their behavior. Nevertheless, measuring physical properties from visual observations is challenging due to the high number of causally underlying physical parameters -- including material properties and external forces. In this paper, we propose to measure latent physical properties for cloth in the wind without ever having seen a real example before. Our solution is an iterative refinement procedure with simulation at its core. The algorithm gradually updates the physical model parameters by running a simulation of the observed phenomenon and comparing the current simulation to a real-world observation. The correspondence is measured using an embedding function that maps physically similar examples to nearby points. We consider a case study of cloth in the wind, with curling flags as our leading example -- a seemingly simple phenomena but physically highly involved. Based on the physics of cloth and its visual manifestation, we propose an instantiation of the embedding function. For this mapping, modeled as a deep network, we introduce a spectral layer that decomposes a video volume into its temporal spectral power and corresponding frequencies. Our experiments demonstrate that the proposed method compares favorably to prior work on the task of measuring cloth material properties and external wind force from a real-world video.
Go with the Flow: Perception-refined Physics Simulation
Oct 17, 2019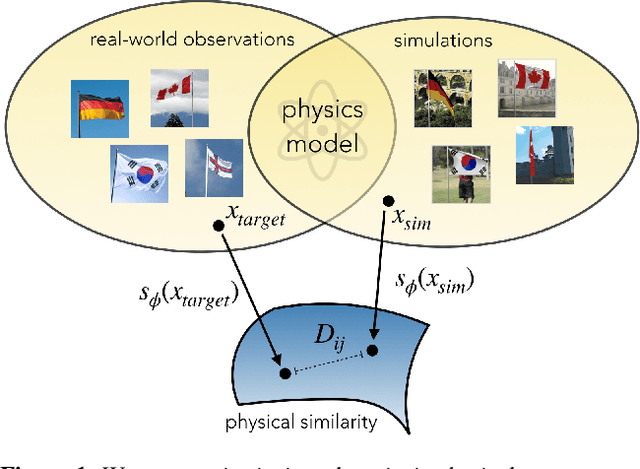


For many of the physical phenomena around us, we have developed sophisticated models explaining their behavior. Nevertheless, inferring specifics from visual observations is challenging due to the high number of causally underlying physical parameters -- including material properties and external forces. This paper addresses the problem of inferring such latent physical properties from observations. Our solution is an iterative refinement procedure with simulation at its core. The algorithm gradually updates the physical model parameters by running a simulation of the observed phenomenon and comparing the current simulation to a real-world observation. The physical similarity is computed using an embedding function that maps physically similar examples to nearby points. As a tangible example, we concentrate on flags curling in the wind -- a seemingly simple phenomenon but physically highly involved. Based on its underlying physical model and visual manifestation, we propose an instantiation of the embedding function. For this mapping, modeled as a deep network, we introduce a spectral decomposition layer that decomposes a video volume into its temporal spectral power and corresponding frequencies. In experiments, we demonstrate our method's ability to recover intrinsic and extrinsic physical parameters from both simulated and real-world video.
Subitizing with Variational Autoencoders
Aug 01, 2018
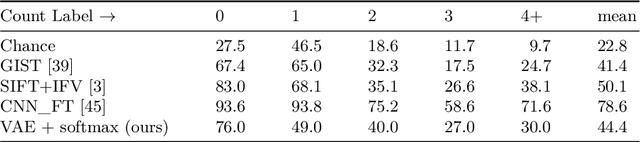


Numerosity, the number of objects in a set, is a basic property of a given visual scene. Many animals develop the perceptual ability to subitize: the near-instantaneous identification of the numerosity in small sets of visual items. In computer vision, it has been shown that numerosity emerges as a statistical property in neural networks during unsupervised learning from simple synthetic images. In this work, we focus on more complex natural images using unsupervised hierarchical neural networks. Specifically, we show that variational autoencoders are able to spontaneously perform subitizing after training without supervision on a large amount images from the Salient Object Subitizing dataset. While our method is unable to outperform supervised convolutional networks for subitizing, we observe that the networks learn to encode numerosity as basic visual property. Moreover, we find that the learned representations are likely invariant to object area; an observation in alignment with studies on biological neural networks in cognitive neuroscience.
Repetition Estimation
Jun 18, 2018
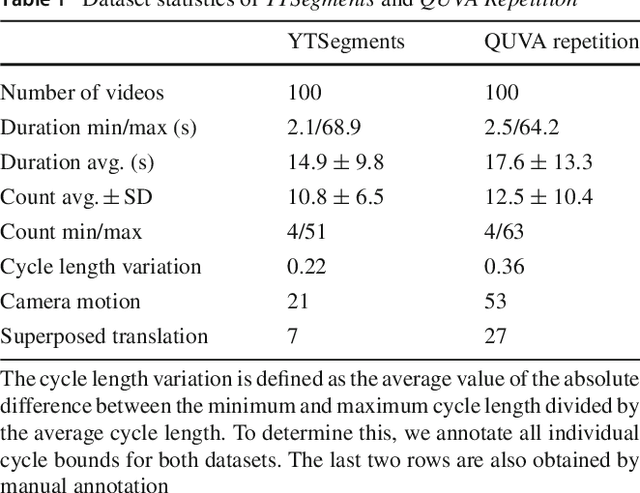

Visual repetition is ubiquitous in our world. It appears in human activity (sports, cooking), animal behavior (a bee's waggle dance), natural phenomena (leaves in the wind) and in urban environments (flashing lights). Estimating visual repetition from realistic video is challenging as periodic motion is rarely perfectly static and stationary. To better deal with realistic video, we elevate the static and stationary assumptions often made by existing work. Our spatiotemporal filtering approach, established on the theory of periodic motion, effectively handles a wide variety of appearances and requires no learning. Starting from motion in 3D we derive three periodic motion types by decomposition of the motion field into its fundamental components. In addition, three temporal motion continuities emerge from the field's temporal dynamics. For the 2D perception of 3D motion we consider the viewpoint relative to the motion; what follows are 18 cases of recurrent motion perception. To estimate repetition under all circumstances, our theory implies constructing a mixture of differential motion maps: gradient, divergence and curl. We temporally convolve the motion maps with wavelet filters to estimate repetitive dynamics. Our method is able to spatially segment repetitive motion directly from the temporal filter responses densely computed over the motion maps. For experimental verification of our claims, we use our novel dataset for repetition estimation, better-reflecting reality with non-static and non-stationary repetitive motion. On the task of repetition counting, we obtain favorable results compared to a deep learning alternative.
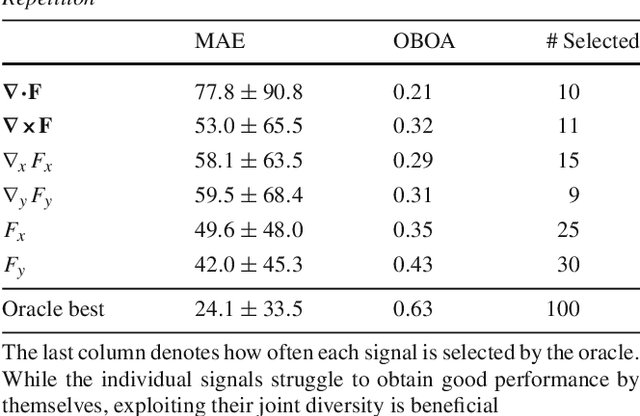
Real-World Repetition Estimation by Div, Grad and Curl
Feb 27, 2018
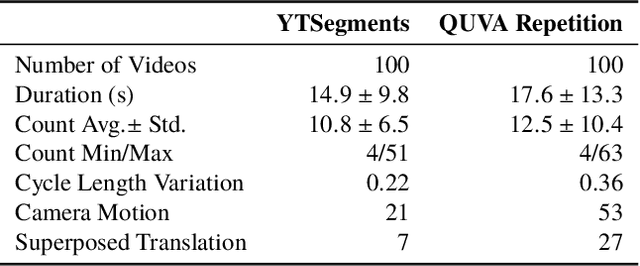
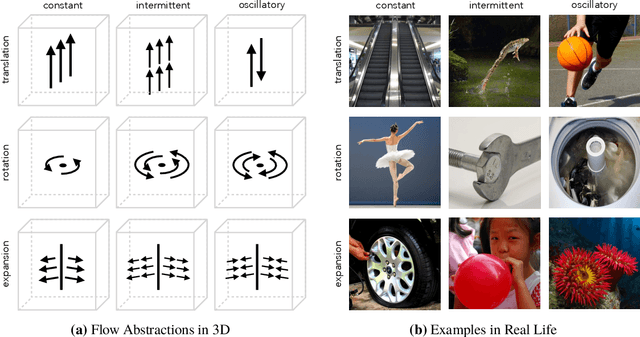
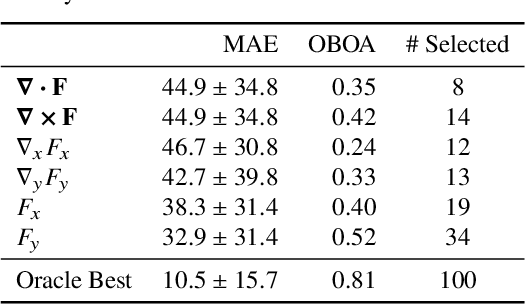
We consider the problem of estimating repetition in video, such as performing push-ups, cutting a melon or playing violin. Existing work shows good results under the assumption of static and stationary periodicity. As realistic video is rarely perfectly static and stationary, the often preferred Fourier-based measurements is inapt. Instead, we adopt the wavelet transform to better handle non-static and non-stationary video dynamics. From the flow field and its differentials, we derive three fundamental motion types and three motion continuities of intrinsic periodicity in 3D. On top of this, the 2D perception of 3D periodicity considers two extreme viewpoints. What follows are 18 fundamental cases of recurrent perception in 2D. In practice, to deal with the variety of repetitive appearance, our theory implies measuring time-varying flow and its differentials (gradient, divergence and curl) over segmented foreground motion. For experiments, we introduce the new QUVA Repetition dataset, reflecting reality by including non-static and non-stationary videos. On the task of counting repetitions in video, we obtain favorable results compared to a deep learning alternative.