 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Visual Search via Composition-aware Learning
Oct 27, 2020
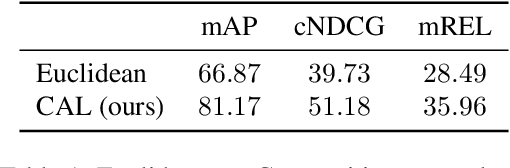
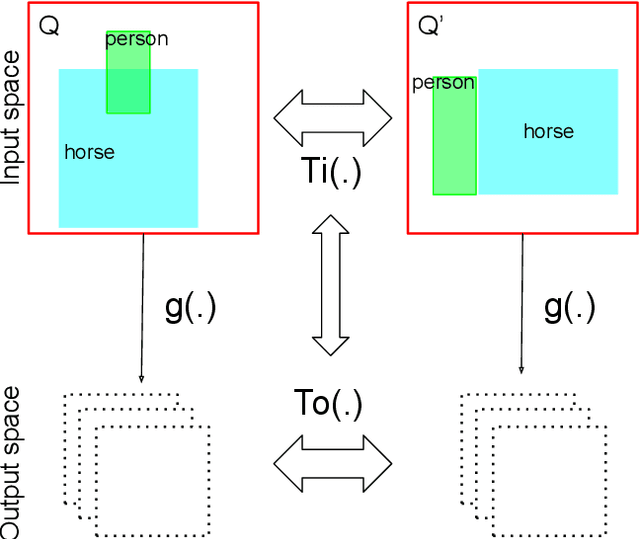
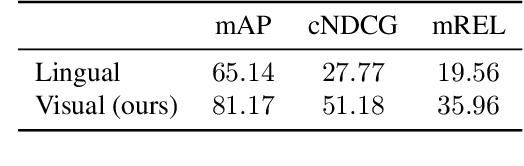
This paper studies visual search using structured queries. The structure is in the form of a 2D composition that encodes the position and the category of the objects. The transformation of the position and the category of the objects leads to a continuous-valued relationship between visual compositions, which carries highly beneficial information, although not leveraged by previous techniques. To that end, in this work, our goal is to leverage these continuous relationships by using the notion of symmetry in equivariance. Our model output is trained to change symmetrically with respect to the input transformations, leading to a sensitive feature space. Doing so leads to a highly efficient search technique, as our approach learns from fewer data using a smaller feature space. Experiments on two large-scale benchmarks of MS-COCO and HICO-DET demonstrates that our approach leads to a considerable gain in the performance against competing techniques.
Tackling Occlusion in Siamese Tracking with Structured Dropouts
Jun 30, 2020
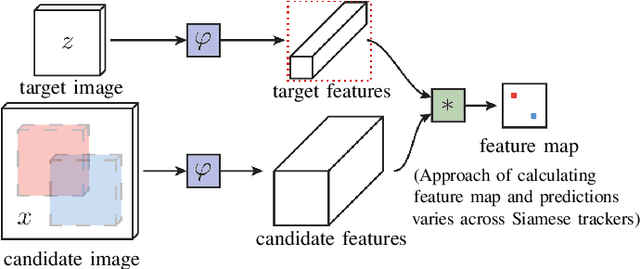

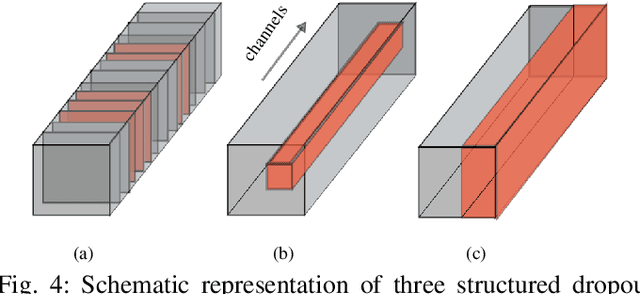
Occlusion is one of the most difficult challenges in object tracking to model. This is because unlike other challenges, where data augmentation can be of help, occlusion is hard to simulate as the occluding object can be anything in any shape. In this paper, we propose a simple solution to simulate the effects of occlusion in the latent space. Specifically, we present structured dropout to mimick the change in latent codes under occlusion. We present three forms of dropout (channel dropout, segment dropout and slice dropout) with the various forms of occlusion in mind. To demonstrate its effectiveness, the dropouts are incorporated into two modern Siamese trackers (SiamFC and SiamRPN++). The outputs from multiple dropouts are combined using an encoder network to obtain the final prediction. Experiments on several tracking benchmarks show the benefits of structured dropouts, while due to their simplicity requiring only small changes to the existing tracker models.
PIC: Permutation Invariant Convolution for Recognizing Long-range Activities
Mar 18, 2020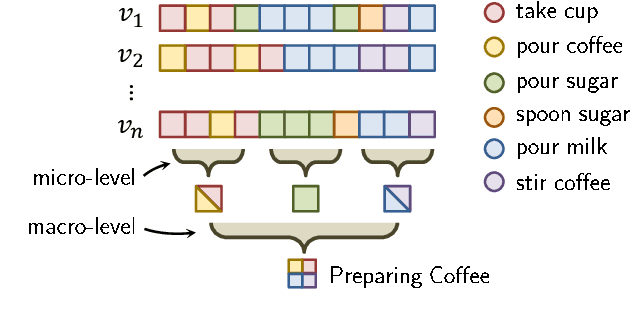
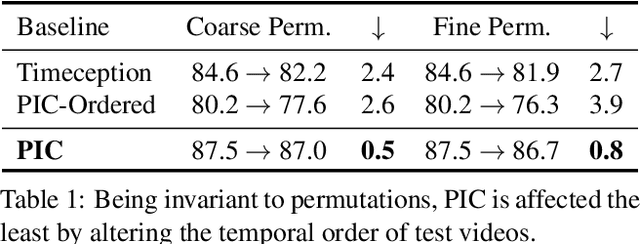
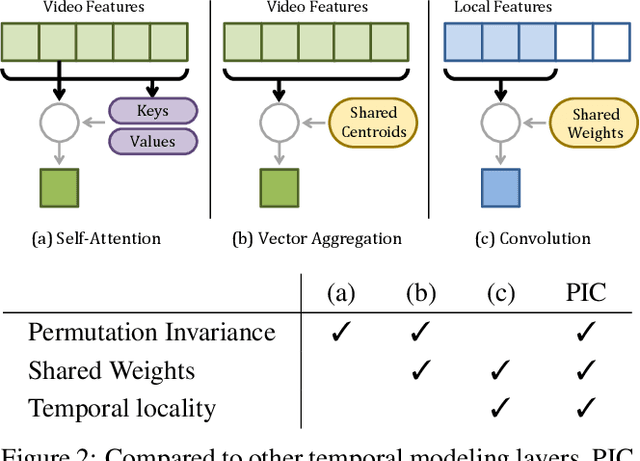
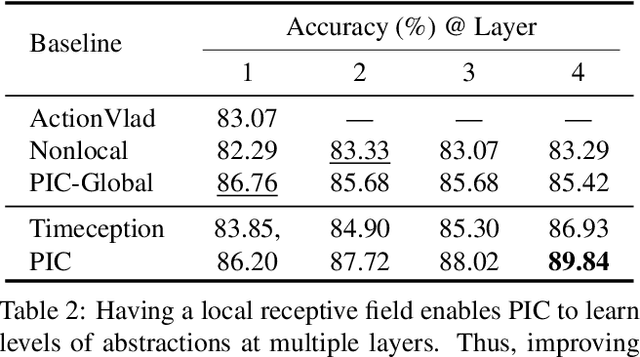
Neural operations as convolutions, self-attention, and vector aggregation are the go-to choices for recognizing short-range actions. However, they have three limitations in modeling long-range activities. This paper presents PIC, Permutation Invariant Convolution, a novel neural layer to model the temporal structure of long-range activities. It has three desirable properties. i. Unlike standard convolution, PIC is invariant to the temporal permutations of features within its receptive field, qualifying it to model the weak temporal structures. ii. Different from vector aggregation, PIC respects local connectivity, enabling it to learn long-range temporal abstractions using cascaded layers. iii. In contrast to self-attention, PIC uses shared weights, making it more capable of detecting the most discriminant visual evidence across long and noisy videos. We study the three properties of PIC and demonstrate its effectiveness in recognizing the long-range activities of Charades, Breakfast, and MultiThumos.
Cloth in the Wind: A Case Study of Physical Measurement through Simulation
Mar 09, 2020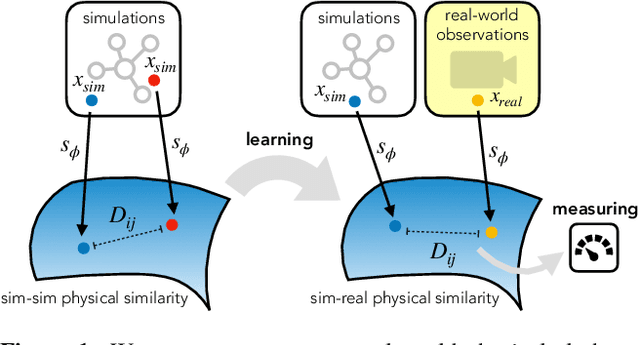
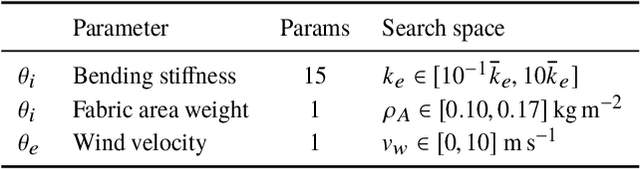

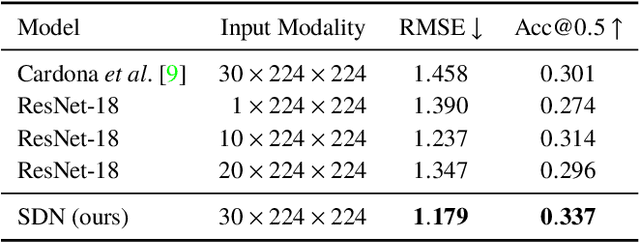
For many of the physical phenomena around us, we have developed sophisticated models explaining their behavior. Nevertheless, measuring physical properties from visual observations is challenging due to the high number of causally underlying physical parameters -- including material properties and external forces. In this paper, we propose to measure latent physical properties for cloth in the wind without ever having seen a real example before. Our solution is an iterative refinement procedure with simulation at its core. The algorithm gradually updates the physical model parameters by running a simulation of the observed phenomenon and comparing the current simulation to a real-world observation. The correspondence is measured using an embedding function that maps physically similar examples to nearby points. We consider a case study of cloth in the wind, with curling flags as our leading example -- a seemingly simple phenomena but physically highly involved. Based on the physics of cloth and its visual manifestation, we propose an instantiation of the embedding function. For this mapping, modeled as a deep network, we introduce a spectral layer that decomposes a video volume into its temporal spectral power and corresponding frequencies. Our experiments demonstrate that the proposed method compares favorably to prior work on the task of measuring cloth material properties and external wind force from a real-world video.
Go with the Flow: Perception-refined Physics Simulation
Oct 17, 2019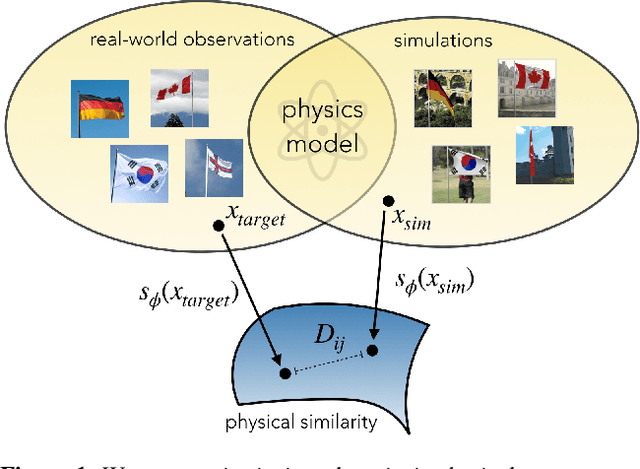
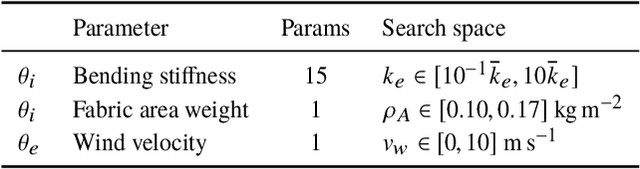


For many of the physical phenomena around us, we have developed sophisticated models explaining their behavior. Nevertheless, inferring specifics from visual observations is challenging due to the high number of causally underlying physical parameters -- including material properties and external forces. This paper addresses the problem of inferring such latent physical properties from observations. Our solution is an iterative refinement procedure with simulation at its core. The algorithm gradually updates the physical model parameters by running a simulation of the observed phenomenon and comparing the current simulation to a real-world observation. The physical similarity is computed using an embedding function that maps physically similar examples to nearby points. As a tangible example, we concentrate on flags curling in the wind -- a seemingly simple phenomenon but physically highly involved. Based on its underlying physical model and visual manifestation, we propose an instantiation of the embedding function. For this mapping, modeled as a deep network, we introduce a spectral decomposition layer that decomposes a video volume into its temporal spectral power and corresponding frequencies. In experiments, we demonstrate our method's ability to recover intrinsic and extrinsic physical parameters from both simulated and real-world video.
Model Decay in Long-Term Tracking
Aug 05, 2019

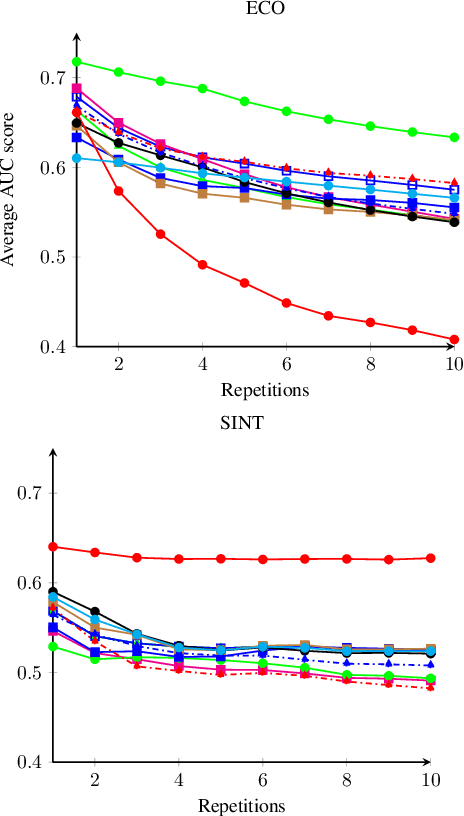
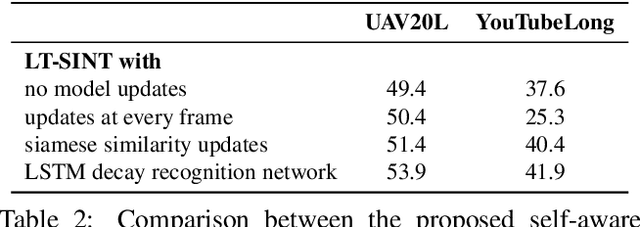
Updating the tracker model with adverse bounding box predictions adds an unavoidable bias term to the learning. This bias term, which we refer to as model decay, offsets the learning and causes tracking drift. While its adverse affect might not be visible in short-term tracking, accumulation of this bias over a long-term can eventually lead to a permanent loss of the target. In this paper, we look at the problem of model bias from a mathematical perspective. Further, we briefly examine the effect of various sources of tracking error on model decay, using a correlation filter (ECO) and a Siamese (SINT) tracker. Based on observations and insights, we propose simple additions that help to reduce model decay in long-term tracking. The proposed tracker is evaluated on four long-term and one short term tracking benchmarks, demonstrating superior accuracy and robustness, even in 30 minute long videos.
VideoGraph: Recognizing Minutes-Long Human Activities in Videos
May 13, 2019
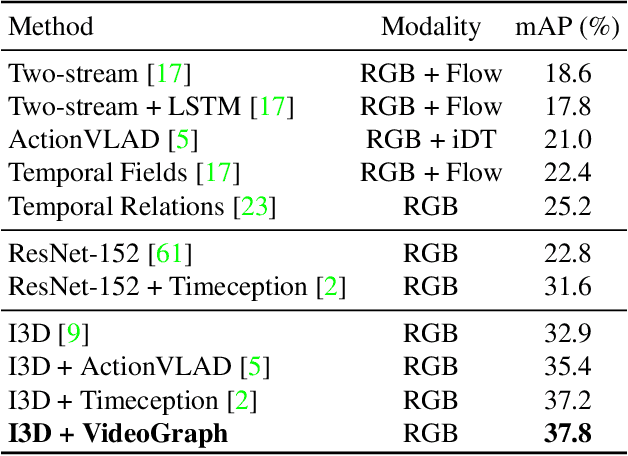
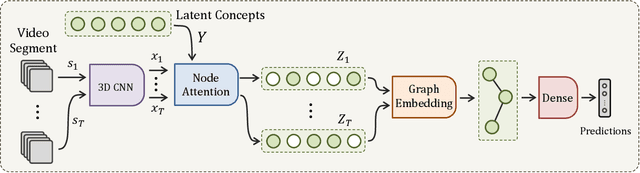
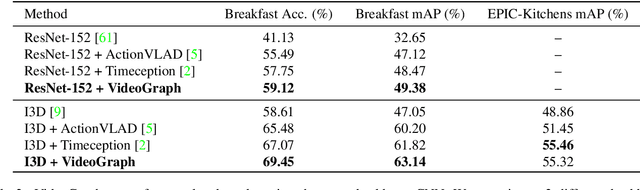
Many human activities take minutes to unfold. To represent them, related works opt for statistical pooling, which neglects the temporal structure. Others opt for convolutional methods, as CNN and Non-Local. While successful in learning temporal concepts, they are short of modeling minutes-long temporal dependencies. We propose VideoGraph, a method to achieve the best of two worlds: represent minutes-long human activities and learn their underlying temporal structure. VideoGraph learns a graph-based representation for human activities. The graph, its nodes and edges are learned entirely from video datasets, making VideoGraph applicable to problems without node-level annotation. The result is improvements over related works on benchmarks: Epic-Kitchen and Breakfast. Besides, we demonstrate that VideoGraph is able to learn the temporal structure of human activities in minutes-long videos.
Cooperative Embeddings for Instance, Attribute and Category Retrieval
Apr 02, 2019



The goal of this paper is to retrieve an image based on instance, attribute and category similarity notions. Different from existing works, which usually address only one of these entities in isolation, we introduce a cooperative embedding to integrate them while preserving their specific level of semantic representation. An algebraic structure defines a superspace filled with instances. Attributes are axis-aligned to form subspaces, while categories influence the arrangement of similar instances. These relationships enable them to cooperate for their mutual benefits for image retrieval. We derive a proxy-based softmax embedding loss to learn simultaneously all similarity measures in both superspace and subspaces. We evaluate our model on datasets from two different domains. Experiments on image retrieval tasks show the benefits of the cooperative embeddings for modeling multiple image similarities, and for discovering style evolution of instances between- and within-categories.
Timeception for Complex Action Recognition
Dec 04, 2018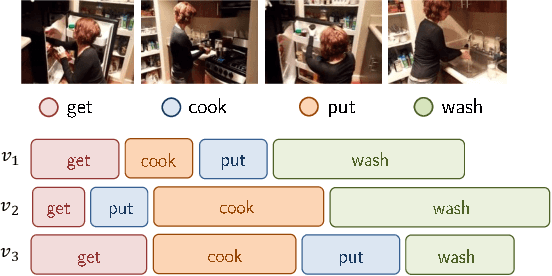
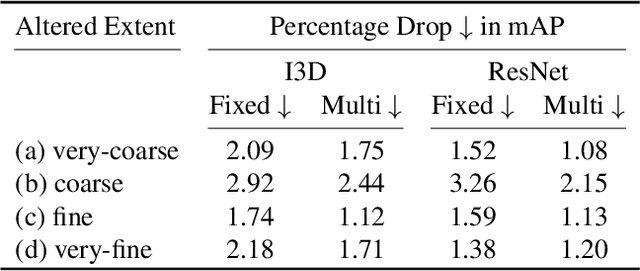
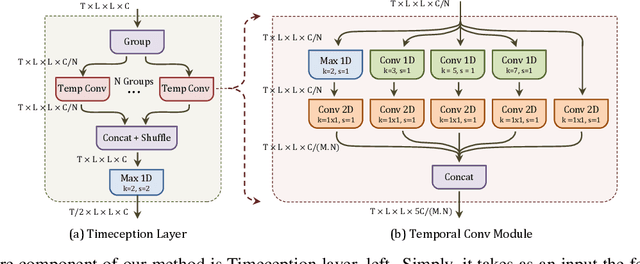
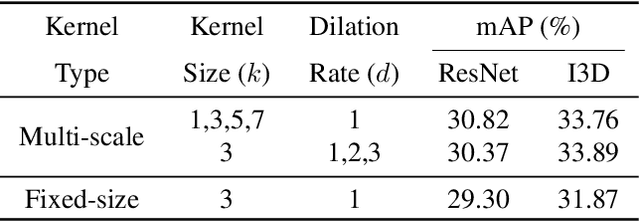
This paper focuses on the temporal aspect for recognizing human activities in videos; an important visual cue that has long been either disregarded or ill-used. We revisit the conventional definition of an activity and restrict it to "Complex Action": a set of one-actions with a weak temporal pattern that serves a specific purpose. Related works use spatiotemporal 3D convolutions with fixed kernel size, too rigid to capture the varieties in temporal extents of complex actions, and too short for long-range temporal modeling. In contrast, we use multi-scale temporal convolutions, and we reduce the complexity of 3D convolutions. The outcome is Timeception convolution layers, which reasons about minute-long temporal patterns, a factor of 8 longer than best related works. As a result, Timeception achieves impressive accuracy in recognizing human activities of Charades. Further, we conduct analysis to demonstrate that Timeception learns long-range temporal dependencies and tolerate temporal extents of complex actions.
Estimating Small Differences in Car-Pose from Orbits
Sep 03, 2018

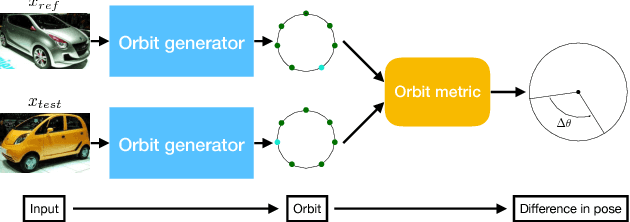

Distinction among nearby poses and among symmetries of an object is challenging. In this paper, we propose a unified, group-theoretic approach to tackle both. Different from existing works which directly predict absolute pose, our method measures the pose of an object relative to another pose, i.e., the pose difference. The proposed method generates the complete orbit of an object from a single view of the object with respect to the subgroup of SO(3) of rotations around the z-axis, and compares the orbit of the object with another orbit using a novel orbit metric to estimate the pose difference. The generated orbit in the latent space records all the differences in pose in the original observational space, and as a result, the method is capable of finding subtle differences in pose. We demonstrate the effectiveness of the proposed method on cars, where identifying the subtle pose differences is vital.