 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoGraph: Recognizing Minutes-Long Human Activities in Videos
Paper and Code

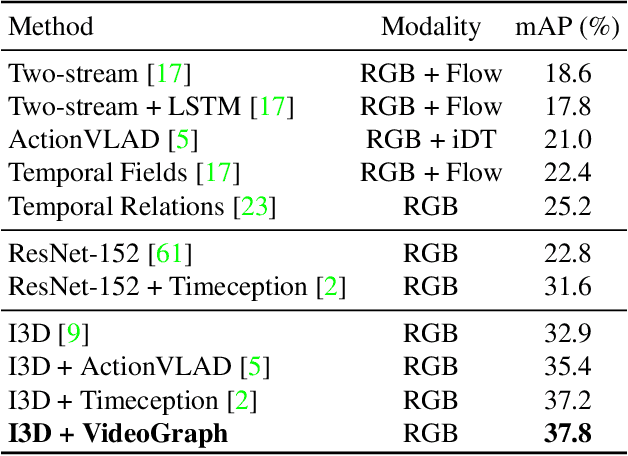
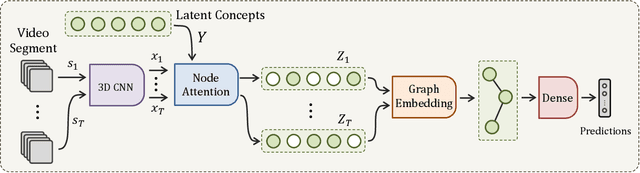
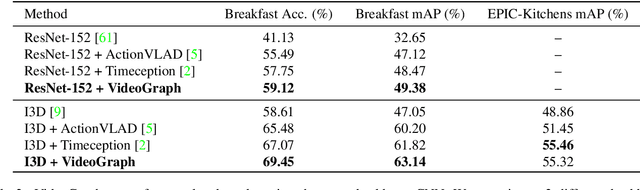
Many human activities take minutes to unfold. To represent them, related works opt for statistical pooling, which neglects the temporal structure. Others opt for convolutional methods, as CNN and Non-Local. While successful in learning temporal concepts, they are short of modeling minutes-long temporal dependencies. We propose VideoGraph, a method to achieve the best of two worlds: represent minutes-long human activities and learn their underlying temporal structure. VideoGraph learns a graph-based representation for human activities. The graph, its nodes and edges are learned entirely from video datasets, making VideoGraph applicable to problems without node-level annotation. The result is improvements over related works on benchmarks: Epic-Kitchen and Breakfast. Besides, we demonstrate that VideoGraph is able to learn the temporal structure of human activities in minutes-long videos.